目录
前言
一、文本表示基础
1.单词的表示
2.句子的表示
3.tf-idf向量?
二、文本相似度
1.计算欧式距离
2.计算余弦距离
三、词向量基础
1.计算单词之间的相似度
2.词向量基础
3. 句子向量
总结
?
前言
上一章已经介绍完自然语言处理任务的第一个流程——文本处理,接下来就是如何用计算机明白的语言向量表示文本了,里面包括如何更好的表示单词和句子。
一、文本表示基础
对于自然语言处理各类应用,最基础的任务就是文本表示。因为我们都知道一个文本是不能直接作为模型的输入的,所以我们必须要先把文本转换成向量的形式之后,再导入到模型中训练。所谓文本的表示,其实就是研究如何把文本表示成向量或者矩阵的形式。
1.单词的表示
如何表示一个单词,最直观的理解就是用One-hot编码来实现。
One-hot表示很容易理解。在一个语料库中,给每个字/词编码一个索引,根据索引进行one-hot表示。
词典:[我们,去,爬山,今天,你们,昨天,跑步]
其中的每个单词都可以用one-hot方法表示:
我们:[1, 0, 0, 0, 0, 0, 0, 0, 0, 0]
爬山:[0, 0, 1, 0, 0, 0, 0, 0, 0, 0]
跑步:[0, 0, 0, 0, 0, 0, 0, 0, 1, 0]
当语料库非常大时,需要建立一个很大的字典对所有单词进行索引编码。比如100W个单词,每个单词就需要表示成100W维的向量,而且这个向量是很稀疏的,只有一个地方为1其他全为0。还有很重要的一点,这种表示方法无法表达单词与单词之间的相似程度,如爬山和登山可以表达相似的意思但是One-hot法无法将之表示出来。
2.句子的表示
知道了如何表示一个单词之后,我们很自然地就可以得到如何表示一个句子了。一个句子由多个单词来组成,那实际上记录一下哪些单词出现,哪些单词没有出现就可以了。当然,很多时候我们也需要记录一个单词所出现的次数。
这里包括两种方法:boolean vector、counter vector。区别只在于前者不统计出现的次数,后者统计出现的次数。
词典:[我们,又,去,爬山,今天,你们,昨天,跑步]
boolean vector
你们又去爬山又去跑步:[0,1,1,1,0,1,0,1]
counter vector
你们又去爬山又去跑步:[0,2,2,1,0,1,0,1]
3.tf-idf向量?
但是上述统计方法存在一个问题,就是单词并不是在一个句子里出现越多就越重要,越少就越不重要,自然语言处理任务的区分更重要的是某一些独特的单词而不是大部分文档都存在的词汇。
所以,如果只记录单词的个数也是不够的,我们还需要考虑单词的权重,也可以认为是质量。这有点类似于,一个人有很多朋友不代表这个人有多厉害,还需要社交的质量,其实是同一个道理。 那如何把这种所谓的“质量”引入到表示中呢?答案是tf-idf。
TF-IDF的应用非常广泛,即便放在当前,也是表示文本的最核心的技术之一。 之前我们讲过什么是基准,那TF-IDF是文本表示领域的最有效的基准。很多时候,基于深度学习的文本表示也未必要优于TF-IDF的表示。
下面简要介绍下TF-IDF,TF-IDF的分数代表了词语在当前文档和整个语料库中的相对重要性。TF-IDF 分数由两部分组成:第一部分是词语频率,第二部分是逆文档频率,如下表示:
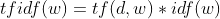
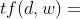 该词语在当前文档出现的次数 / 当前文档中词语的总数。
该词语在当前文档出现的次数 / 当前文档中词语的总数。
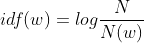 ,
,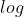 中包含的是文档总数 / 出现该词语的文档总数。
中包含的是文档总数 / 出现该词语的文档总数。
TF-IDF算法的优点是简单快速,结果比较符合实际情况。缺点是,单纯以"词频"衡量一个词的重要性,不够全面,有时重要的词可能出现次数并不多。而且,这种算法无法体现词的位置信息,出现位置靠前的词与出现位置靠后的词,都被视为重要性相同,这是不正确的。
二、文本相似度
如何计算两个文本之间的相似度?这个问题实际上可以认为是计算两个向量之间的相似度。上一节已经将文本转换成向量,那么可以采用两种常见的相似度计算方法来衡量算两个文本之间的相似度,一个是基于欧式距离的计算,另外一种方式为基于余弦相似度的计算。
1.计算欧式距离
欧氏距离是最易于理解的一种距离计算方法,源自欧氏空间中两点间的距离公式,如下所示:
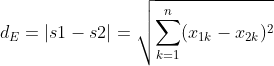
向量之间的相似度实际上要考虑到向量的方向,因为向量最重要的特性为它的方向性。如果两个向量相似,那也需要它俩的方向也比较相似。然而,计算欧式距离的过程并没有把方向考虑进去,这是欧式距离的最大的问题。
2.计算余弦距离
为了弥补欧式距离所存在的问题,需要提出另外一种相似度计算方法——余弦相似度。通过余弦相似度,实际计算的是两个向量之间的夹角大小。两个向量的方向上越一致就说明它俩的相似度就越高,表达式如下所示:
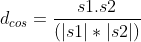
所以余弦相似度有以下四点特征:
- 在分母上除以向量大小是为了消除两个向量大小所带来的影响
- 内积可用来计算向量之间的相似度
- 余弦相似度考虑到了方向,欧式距离则没有
- 在向量之间相似度计算上,余弦相似度的应用相比欧式距离更广泛一些
三、词向量基础
上一节为止,我们一直在讨论如何计算两个文本之间的相似度,但至今还没有讨论过如何计算两个单词之间的相似度。单词作为文本的最基本的要素,如何表示单词的含义以及两个单词之间的相似度也极其重要。
1.计算单词之间的相似度
可以发现通过One-hot编码得到的单词向量,是无法通过欧式距离或者余弦相似度计算出单词之间的相似度,因为不管如何计算,俩俩之间的结果都是一样的。因此我们需要考虑另外一种单词的表示法,这就自然引出词向量的概念。而且 除了不能计算相似度,独热编码也存在稀疏性的问题。
2.词向量基础
我们可以在分布式表示方法下计算出两个单词之间的相似度。当然,效果取决于词向量的质量。所以,如何得出这些词向量?

由于具体的训练词向量方法需要涉及其他知识,在后续文章会说明。在这一节中,仅需要知道当我们将语料库输入到某个模型中,通过训练出可以将单词转化成具有某些特征的词向量,比如语义相似度高的单词转化的词向量相似度也高。

3. 句子向量
假如我们手里已经有了训练好的词向量,那如何通过这些词向量来表示一个完整的文本呢,或者一个句子呢?有一种最简单且常用的方法,就是做平均。
有了文本表示之后,我们就可以开始对文本做建模了,比如计算两个文本之间的相似度,或者对某个文本做分类。在这里我们来做个简单的小结:
- 单词的One-hot编码和分布式表示是两种完全不一样的编码方式
- 这两种不同的编码方式是目前文本表示的两个方向,有些时候传统的One-hot编码的方式可能更适合,有些时候分布式表示法更适合,具体还是要通过测试来获得结论
- One-hot编码的最大的问题是不能表示一个单词的含义
- 词向量的质量取决于词向量训练模型,不同的模型所给出的结果是不一样的
总结
本章主要是研究如何表示文本,包括单词和句子。对单词可以采用One-hot编码和分布式编码,对于句子可以取向量平均。而衡量文本相似度的方法主要是欧氏距离和余弦距离,更通常使用余弦距离,因为其考虑了向量的方向。
参考:
贪心学院nlp
NLP中的文本表示方法
?
cs