ǰ��
ǰ��ʱ�������Ͽ���������AI���!��д��һ��ǹǹ��ͷ���Ӿ�AI,�����֡�ɱ����������?�����Ƶ,�������Ҽ������Ȥ��
��Ƶ���ᵽ,�ڹ������˸�ʹ���ٻ����˸�AI������ʵ���Զ���������������ͳ��Ҳ�һ��,�ó�����Ҫ����Ϸ�ڴ�����,Ҳ������������������ָ��,ֻ��ͨ��������Ӿ���������Ϸ����,��λ����,�����ƶ���ȥ,��������Ҳ���һģһ��,��˷���ҳ��������������Ҹ��ֲ�������AI����ȫƽ̨ͨ��,������X-box,PS4�����ֻ�,ֻҪ�ܰѻ���ӳ���,�Ѳ����ͽ�ȥ,�Ϳ���ʵ�֡�ǹǹ��ͷ����

�������Ǹ��������õ������ڷ����Ŀ����,�����������Ϸ��Ҫ��λ����ij���,��ʵ�бȷ�������õ��㷨��up���������˼���Сʱ��ʱ���д������һ��Ч������,���ܸ����ŵ�AI����,Ҳ������������ؽڵ��⼼��,ͨ����������ͼƬѵ���������Ӿ�AI,������Ƶ��ͼƬ������Ĺؽ���Ϣ��ȡ���� ������ÿ����λ���ĵ�ľ�ȷ��������,������Ȼѵ������������ͼƬ,���Ǹ�����Ϸ�������,��Ҳһ���ܰ�����ؽڶ�λ������
����˵��������AI����ij���,����fps��Ϸ����ʽ����ɽ����������¥,ʮ���Ͼ���!
����,�����ȿ�ʼ��������Ӿ�AI�Զ���������˼·,Ȼ����̸̸������������Ӱ���Լ���ν�����������
һ�����Ĺ������
������˵,����������Ҫѵ����һ������ؽڵ����AI�Ӿ�ģ��,Ȼ����Ϸ����ʵʱ����AI�Ӿ�ģ����,�ٷ�������Ϸ���������λ������λ��,Ȼ��ȷ������,��������ƶ�������λ�á�
��������,����������������:
- ѵ������ؽڵ���ģ��
- ������Ƶ��ͼƬ��AI�Ӿ�ģ��,���������λ����
- �Զ���������ƶ�����Ӧ��λ��
������Ҫʵ�ֵ�Ч������ͼ��ʾ:

��������ʵ�ֲ���
1.ѵ������ؽڵ���ģ��
����һ����,�Ҵ���ʹ�����������о�Ժ���пƴ����High-Resoultion Net(HRNet)����������ؽڵ���,��ģ��ͨ���ڸ߷ֱ�������ͼ���������м���ͷֱ�������ͼ������,��ͬ����ʵ�ֶ�߶��ں���������ȡʵ�ֵ�,������Ŀǰ��ͨ�����ݼ���ȡ���˽ϺõĽ����
1.1 HRNet����ⰲװ
���չٷ���installָ������,��װʮ�ּ����Dz��ñ���Դ���밲װ��ʽ��
git clone https://github.com/leoxiaobin/deep-high-resolution-net.pytorch.git
python -m pip install -e deep-high-resolution-ne.pytorch
1.2 ����ؼ������ݼ�����
���ȴ�COCO���ݼ��ٷ��������ӡ�
����Imagesһ������ɫ����Ҫ������������ļ�,�ֱ��Ӧ����ѵ����,��֤���Ͳ��Լ�:
?2017 Train images [118K/18GB]
2017 Val images [5K/1GB]
2017 Test images [41K/6GB]
����Annotationsһ����ɫ����Ҫ����һ����ע�ļ�:
2017 Train/Val annotations [241MB]?
���ļ���ѹ��,���Եõ�����Ŀ¼�ṹ:
���е� person_keypoints_train2017.json �� person_keypoints_val2017.json �ֱ��Ӧ������ؼ������Ӧ��ѵ��������֤����ע��
annotations
������ captions_train2017.json
������ captions_val2017.json
������ instances_train2017.json
������ instances_val2017.json
������ person_keypoints_train2017.json ? ?����ؼ������Ӧ��ѵ������ע�ļ�
������ person_keypoints_val2017.json ? ? ����ؼ������Ӧ����֤����ע�ļ�
�ڱ��ش����datasetsĿ¼�����½���cocoĿ¼,�������ѵ����,��֤���Լ���ע�ļ��ŵ����ش����cocoĿ¼����
?datasets
������ coco
�� ? ������ annotations
�� ? ������ test2017
�� ? ������ train2017
�� ? ������ val2017
1.3 ����������ģ��ѵ��
����ѵ����������:
def train(config, train_loader, model, criterion, optimizer, epoch,
output_dir, tb_log_dir, writer_dict):
batch_time = AverageMeter()
data_time = AverageMeter()
losses = AverageMeter()
acc = AverageMeter()
# switch to train mode
model.train()
end = time.time()
for i, (input, target, target_weight, meta) in enumerate(train_loader):
data_time.update(time.time() - end)
outputs = model(input)
target = target.cuda(non_blocking=True)
target_weight = target_weight.cuda(non_blocking=True)
if isinstance(outputs, list):
loss = criterion(outputs[0], target, target_weight)
for output in outputs[1:]:
loss += criterion(output, target, target_weight)
else:
output = outputs
loss = criterion(output, target, target_weight)
optimizer.zero_grad()
loss.backward()
optimizer.step()
# measure accuracy and record loss
losses.update(loss.item(), input.size(0))
_, avg_acc, cnt, pred = accuracy(output.detach().cpu().numpy(),
target.detach().cpu().numpy())
acc.update(avg_acc, cnt)
batch_time.update(time.time() - end)
end = time.time()
if i % config.PRINT_FREQ == 0:
msg = 'Epoch: [{0}][{1}/{2}]\t' \
'Time {batch_time.val:.3f}s ({batch_time.avg:.3f}s)\t' \
'Speed {speed:.1f} samples/s\t' \
'Data {data_time.val:.3f}s ({data_time.avg:.3f}s)\t' \
'Loss {loss.val:.5f} ({loss.avg:.5f})\t' \
'Accuracy {acc.val:.3f} ({acc.avg:.3f})'.format(
epoch, i, len(train_loader), batch_time=batch_time,
speed=input.size(0)/batch_time.val,
data_time=data_time, loss=losses, acc=acc)
logger.info(msg)
writer = writer_dict['writer']
global_steps = writer_dict['train_global_steps']
writer.add_scalar('train_loss', losses.val, global_steps)
writer.add_scalar('train_acc', acc.val, global_steps)
writer_dict['train_global_steps'] = global_steps + 1
prefix = '{}_{}'.format(os.path.join(output_dir, 'train'), i)
save_debug_images(config, input, meta, target, pred*4, output,
prefix)
ѵ�����:

2.������Ƶ��ͼƬʵʱ������������
2.1 ʵʱ��ȡ��Ļ����
import pyautogui
img = pyautogui.screenshot()
��һ�� 1920��1080 ����Ļ��,screenshot()����Ҫ����100��,�����ﵽʵʱ������Ϸ����Ҫ��
�������Ҫ��ȡ������Ļ,����һ����ѡ��region����������ѽ�ȡ��������Ͻ�XY����ֵ�Ϳ��ȡ��߶ȴ����ȡ��
im = pyautogui.screenshot(region=(0, 0, 300 ,400))
2.2 ��ȡͼƬ��������
parser.add_argument('--keypoints', help='f:full body 17 keypoints,h:half body 11 keypoints,sh:small half body 6 keypotins')
hp = PoseEstimation(config=args.keypoints, device="cuda:0")
����ѡ������ؽڵ�����Ŀ,�����ϰ���6���ؼ��㡢�ϰ���11���ؼ����Լ�ȫ��17���ؼ���,Ȼ��̽������
����ؽڵ��Ӧ���:
?"keypoints": { 0: "nose", 1: "left_eye", 2: "right_eye", 3: "left_ear", 4: "right_ear", 5: "left_shoulder", 6: "right_shoulder", 7: "left_elbow", 8: "right_elbow", 9: "left_wrist", 10: "right_wrist", 11: "left_hip", 12: "right_hip", 13: "left_knee", 14: "right_knee", 15: "left_ankle", 16: "right_ankle" }
������Ϊ���Զ���ͷ��ʵ�֡�ǹǹ��ͷ��,����Ҫ����?0: "nose"�����������ˡ�
��������:
location=hp.detect_head(img_path, detect_person=True, waitKey=0)
def detect_head(self, image_path, detect_person=True, waitKey=0):
bgr_image = cv2.imread(image_path)
kp_points, kp_scores, boxes = self.detect_image(bgr_image,
threshhold=self.threshhold,
detect_person=detect_person)
return kp_points[0][0]
������:[701.179 493.55]
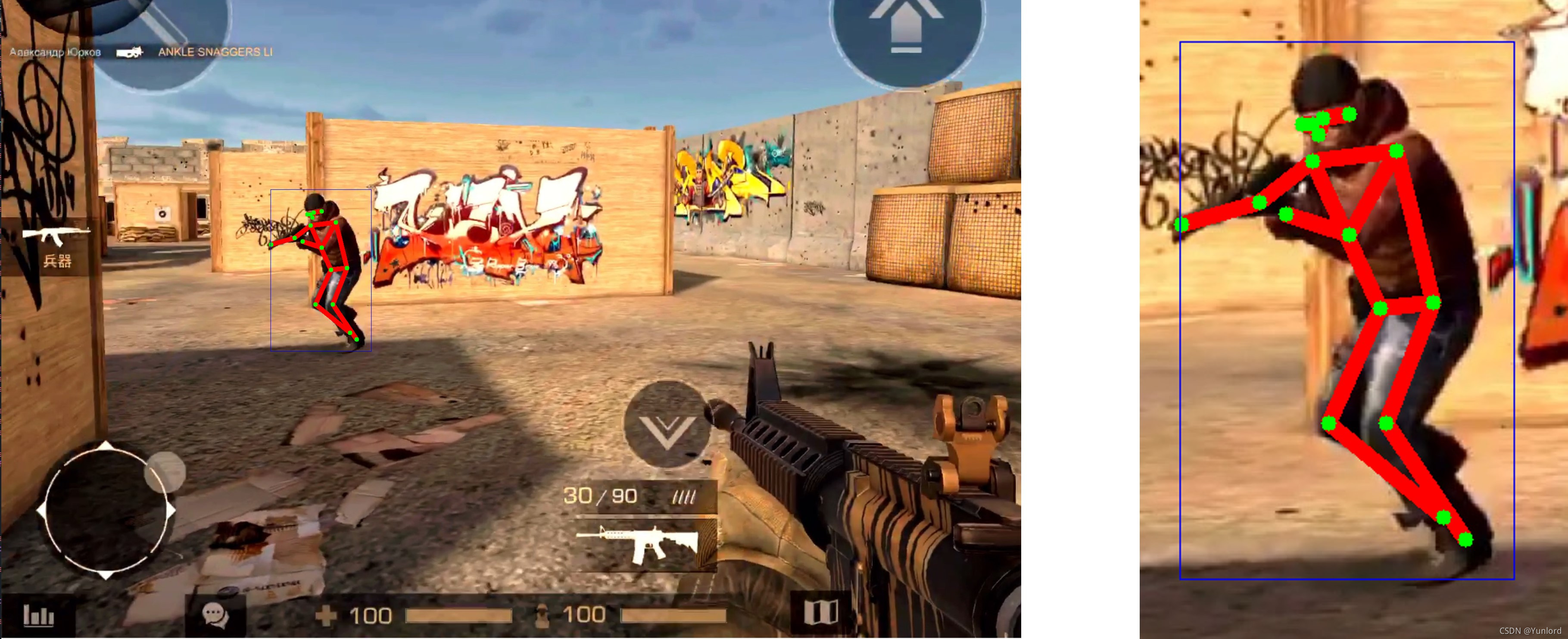
���Կ�����Ȼѵ����������ͼƬ,���Ǹ�����Ϸ�������,��Ҳһ���ܰ�����ؽڶ�λ������
���������֮��������,������Ϊ����һ���������ƹ�������û�����Ķ���,��Ҳ�ܿ��Ų����������һ��,�������Ҳͦ��������Ϸ��������ʵ�����ļ�֮��Ľ��,������Ӱ��Ҫ�Ķ�,�ܰ���ʵ������������Ӿ�AI,�Ը���3D��Ϸ����С��һ���ˡ�
3.�Զ��ƶ���굽��Ӧ�������
3.1 �ƶ����
�ƶ���ָ��λ��:
pyautogui.moveTo(100,300,duration=1)
������ƶ���ָ��������;duration �������������ƶ�ʱ��,���е�gui���������������,���Ҷ��ǿ�ѡ������
��ȡ���λ��:
print(pyautogui.position()) ? # �õ���ǰ���λ��;���:Point(x=200, y=800)
3.2 ���������
�������:
# ������
pyautogui.click(10,10) ? # �����ָ��λ��,Ĭ�����
pyautogui.click(10,10,button='left') ?# �������
pyautogui.click(1000,300,button='right') ?# �����Ҽ�
pyautogui.click(1000,300,button='middle') ?# �����м�
˫�����:
pyautogui.doubleClick(10,10) ?# ָ��λ��,˫�����
pyautogui.rightClick(10,10) ? # ָ��λ��,˫���Ҽ�
pyautogui.middleClick(10,10) ?# ָ��λ��,˫���м�
��� & �ͷ�:
pyautogui.mouseDown() ? # ��갴��
pyautogui.mouseUp() ? ?# ����ͷ�
����,�Ӿ�AI��������Ѿ����������ɡ�����ʵ��Ч�����Բμ����up������Ƶ��
���ࡿ����AI���!��д��һ��ǹǹ��ͷ���Ӿ�AI,�����֡�ɱ��������
cs