目录
前言
一、词向量基础
1.单词的表示
2.从独热编码到分布式表示
3.词向量的训练
二、SkipGram模型详解
1.训练词向量的核心思想
2.SkipGram的目标函数
3.SkipGram的负采样
三、其他词向量技术
1.矩阵分解法
2.Glove向量
总结
前言
上一章已经介绍完自然语言处理任务中较为重要的文本表示这一概念,里面提到了词向量,但没有具体讲解,而本章将会详细介绍词向量技术以及应用。
一、词向量基础
?自然语言任务中单词作为一个最小单元输入,那如何将其转化为计算机能够识别的东西呢?这就涉及到单词的表示。
1.单词的表示
如何表示一个单词,最直观的理解就是用独热编码来实现。独热编码简单且有效、而且广泛应用在各类NLP场景。但它的问题有以下三点:
- 独热编码没有办法表示单词的含义
- 独热编码没有办法表示单词之间的语义相似度
- 独热编码向量维度高,而且非常稀疏
2.从独热编码到分布式表示
基于独热编码的缺点,我们提出分布式表示,通常称为词向量,因为我们将单词用向量来表示。分布式表示具有以下特点:
- 可以认为表示单词的含义
- 向量稠密
- 向量长度是超参数
- 需要训练
3.词向量的训练
词向量是训练出来的。所以,我们可以认为,中间有一个模型可以帮助我们训练出每个单词的向量。这个模型到底是什么呢?那就是通过词向量技术训练模型。词向量技术也是带动NLP发展的最有利的催化器,自从2013年提出word2vec开始,之后整个NLP领域有了飞跃式的发展。如果说,ImageNet是CV领域的催化剂,那么word2vec有着同样的重要性。简单的说,如下图所示,词向量技术就是给定一个语料库,设定各种参数,比如向量长度,然后训练模型得到词向量。其中最重要的就是skip gram模型。
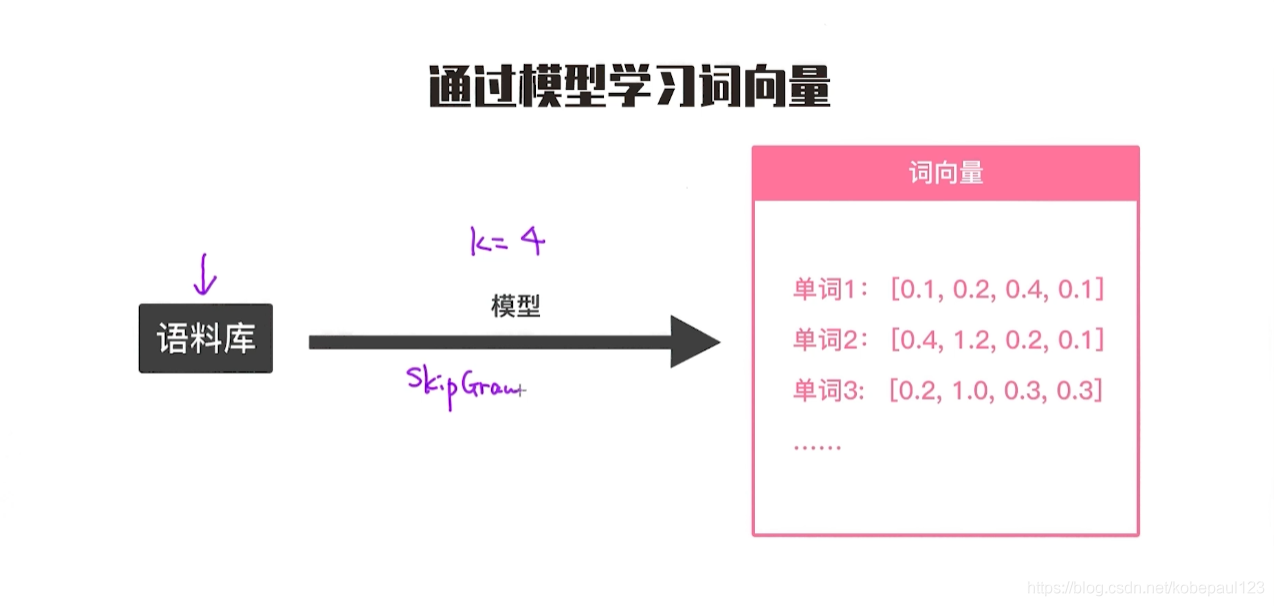
?
到目前为止简单地介绍词向量以及它的训练。在这里做个简单的总结:
- 词向量可以认为在某种程度上代表单词的含义
- 词向量是需要训练出来的,也就是提前要设计好词向量训练模型
- 词向量技术极大推动了NLP领域的发展
二、SkipGram模型详解
1.训练词向量的核心思想
词向量模型其实很多,包括大家所熟悉的BERT等。每一种词向量,它的目标和作用是不一样的,我们在后续的章节中会一一做介绍。但不管怎么样,这些模型都享有着共同的核心思想。等我们深入理解了这个思想,便可以更容易理解模型为什么会这么设计,而且甚至将来也可以提出自己的模型。
词向量训练的学习目标就是针对每个单词学习向量化表示,而我们基于一个基础的分布式假设,即周围单词的相关性高,预测的单词可以根据周围的单词判断。
那我们基于分布式假设,可以得到不同的模型,简单地说,比如CBOW就是通过周围的单词预测出中间词,Skip-Ngram就是通过中心词预测周围的词。
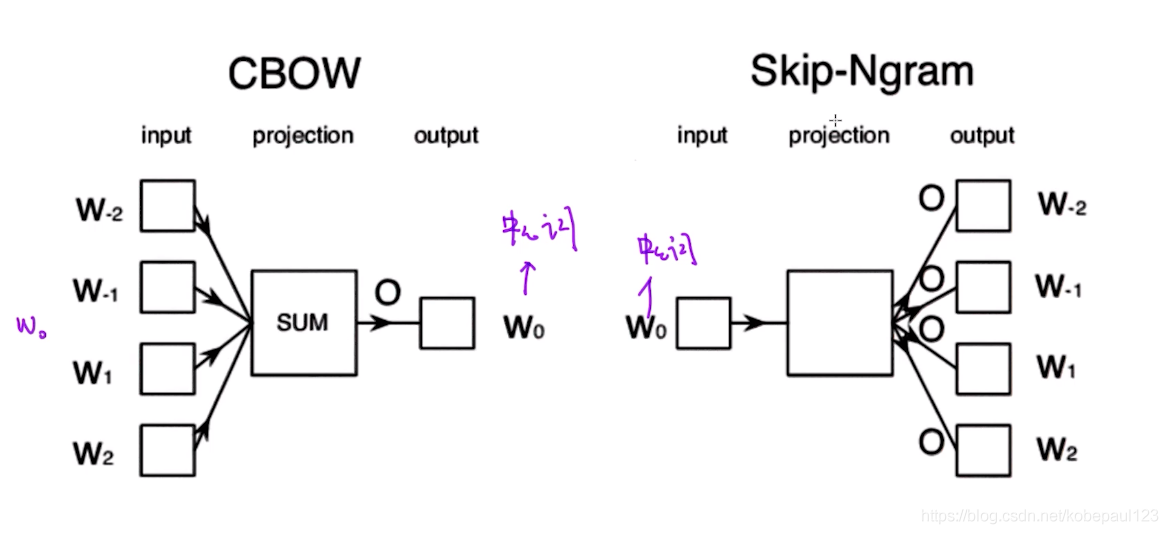
2.SkipGram的目标函数
下面,具体来学习一下SkipGram模型。它是一个非常著名的词向量训练模型。它的核心思想是通过中心词来预测它周围的单词。也就是说,如果我们的词向量训练比较到位,则这方面的预测能力会更强。我们要最大化相邻的词向量,那如何去构建目标函数,基于以下条件:
- 概率处于0,1之间
- 相邻词越相似概率越大
- 相邻词越不相似概率越小
- 概率之和为1
推导出目标函数如下:
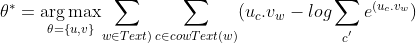
?由于推导过程过于繁琐,所以就不一一列举,基本思想就是针对每一个单词在上下文词库和中心词库训练出不同的词向量,但这样会出现一个问题,就是每计算一个中心词,就得遍历词库中涉及该词的上下文,所以为了优化训练过程,提出了SkipGram的负采样。
3.SkipGram的负采样
得到了SkipGram目标函数之后,发现了这个目标函数其实不好优化。所以需要换一种方式去优化,其中比较流行的方法是使用负采样。判断两个单词是不是一对上下文词与目标词,如果是一对,则是正样本,如果不是一对,则是负样本。生成一个正样本则是采样得到一个上下文词和一个目标词,生成一个负样本则是用与正样本相同的上下文词,再在字典中随机选择一个单词,这就是负采样。接下来我们从负样本的角度来推导SkipGram的目标函数,如下所示:
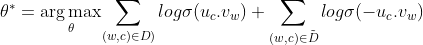
前半部分是正样本,后半部分是负样本,因为负样本数量远远大于正样本,所以我们仅需要采样部分负样本就可以了。当我们有了目标函数之后,剩下的过程无非就是优化并寻找最优参数了。实际上,通过优化最终得出来的最优参数就是训练出来的词向量。优化方法可采用梯度下降法或者随机梯度下降法,具体可以参考skip-gram与负采样。
三、其他词向量技术
SkipGram是训练词向量的其中一种方式,但并不是唯一的方法。实际上,从第一次提出word2vec开始,学者们已经提出了各种各样的训练方式。每个方法论的侧重点、目标是有所不同的。接下来,我们来重点介绍几个有趣的词向量训练模型。
1.矩阵分解法
矩阵分解法就是通过统计一个事先指定大小的窗口内的词共现次数,以词周边的共现词的次数做为当前word的vector。具体来说,我们通过从大量的语料文本中构建一个词共现矩阵来统计次数。然后再通过SVD分解等方法对原始词向量进行降维,从而得到一个稠密的连续词向量。
矩阵分解作为全局方法也有它的优点和缺点。一个最大的缺点是每次分解依赖于整个矩阵,这就导致假如有些个别文本改变了,按理来讲是需要重新训练的,但优点是学习过程包含了全局的信息。相反,对于SkipGram模型,由于训练发生在局部,所以训练起来效率高,且能够很好把握局部的文本特征,但问题是它并不能从全局的视角掌握语料库的特点。
所以,接下来的问题是能否把各自的都优点发挥出来?答案是设计一个融合矩阵分解和SkipGram模型的方法,这个答案其实是Glove模型。
2.Glove向量
Glove实际上是结合了矩阵分解和SkipGram两种方法,其全称Global vevtors of Word Representation,其损失函数是:
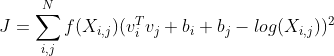
简单地说,就是从共现矩阵中随机采集一批非零词对作为一个mini-batch的训练数据;随机初始化这些训练数据的词向量以及随机初始化两个偏置;然后进行内积和平移操作并与计算损失值,计算梯度值;然后反向传播更新词向量和两个偏置;循环以上过程直到结束条件,具体可以参考理解GloVe模型,总结如下:
- 记录每两个单词之间共同出现的频次
- 设定窗口大小
- 使用加权的最小二乘误差
总结
到此为止讲完了SkipGram。在本章的最后,总结一下:
- 词向量技术的目的是通过向量来表示一个单词的语义
- SkipGram是流行的一种词向量学习技术
- SkipGram通过中心词来预测它周围的单词
- SkipGram原始的目标函数很难优化,所以采用负采样的方式来解决
- 除了SkipGram还有很多不同的学习词向量的方式。
但是前面讲的所有方法都是用来学习静态词向量,也就是不管在什么样的上下文中,每一个单词都是对应同一个词向量。所以说为了更好的表示词,接下来的章节将会介绍动态词向量。
?
参考:
贪心学院nlp
skip-gram与负采样???????
GloVe模型???????
cs