Ŀ¼
һ��ע�������ƽ���
1.dz̸ע����
2.ע�����������
����������Ӿ��е�ע��������
1.��ͼ˵��
2.���ڵ�����
3.����ע��������
��������ģ���е�ע��������
1.Seq2Seq��һЩ����?
2.Seq2Seq����ע��������
�ġ���ע����������Transformer
1.��ע�������ƽ���
2. ��ע��������ϸ��
3.λ�ñ���
�ܽ�
һ��ע�������ƽ���
1.dz̸ע����
ע����������ѧϰ�бز����ٵ�Ҫ��,����˵����ȥ�Ķ�һ������,��������ȥ����һ������������������˼,����ͨ�����Ķ������л��ע�������ڱȽ���Ҫ�Ļ�����,������ȥ��ÿ��ϸ�ڶ���һһ��ס���˵ļ���������,ץ�ص��ѧϰ��ʽ������õ��°빦����Ч����
�Ǽ�Ȼע������ô��Ҫ,������û�а취��������AIӦ������?�����е�,�Ǿ���ע�������ơ�
ע���������ڹ�ȥ����ȡ���˷��ٵķ�չ,�����Ѿ���Ϊ�ܶ�Ӧ�õı��䡣��ע�������Ʒŵ���������,��ʵ�����û���ѧϰѡ���Ե�ȥѧϰ,ͬʱ֪����ΰ�ע�������ڸ���Ҫ��������,�������һ����������,�����京�����ֻ��Ҫ���ص���ڼ������ĵĵ����ϡ�
2.ע�������Ƶ���Ҫ��
��Attention����֮ǰ,�Ѿ���CNN��RNN�������ģ����,��Ϊʲô��Ҫ����attention����?��Ҫ�����������ԭ��,����:
(1)��������������:��Ҫ��ס�ܶࡰ��Ϣ��,ģ�;�Ҫ��ø�����,Ȼ��Ŀǰ����������Ȼ�����������緢չ��ƿ����
(2)�Ż��㷨������:LSTMֻ����һ���̶��ϻ���RNN�еij�������������,����Ϣ�����䡱����������
ע���������ڲ�ͬӦ���µ�ʹ��Ҳ��ͬС�졣����ͼƬ����,ע������Ҫ�ŵ�ijһ��������; �����ı�����,ע������Ҫ����ij����������; ����,������������ע�������Ƹ���ͳ��ע��������������һ��,�ܹ�����Ч�ؽ���ݶ�,���л������⡣
����������Ӿ��е�ע��������
1.��ͼ˵��
��ͼ˵����ָ,���ݸ�����ͼƬ����һ���ı�����,����������Ƕ���ͼƬ�����⡣ ʵ����,��������������Ϊ��һ��ͼƬת�����ı�,ͼƬ�������ɲ���CNNģ��,�ı�����ģ��ɲ���LSTMģ�顣
2.���ڵ�����
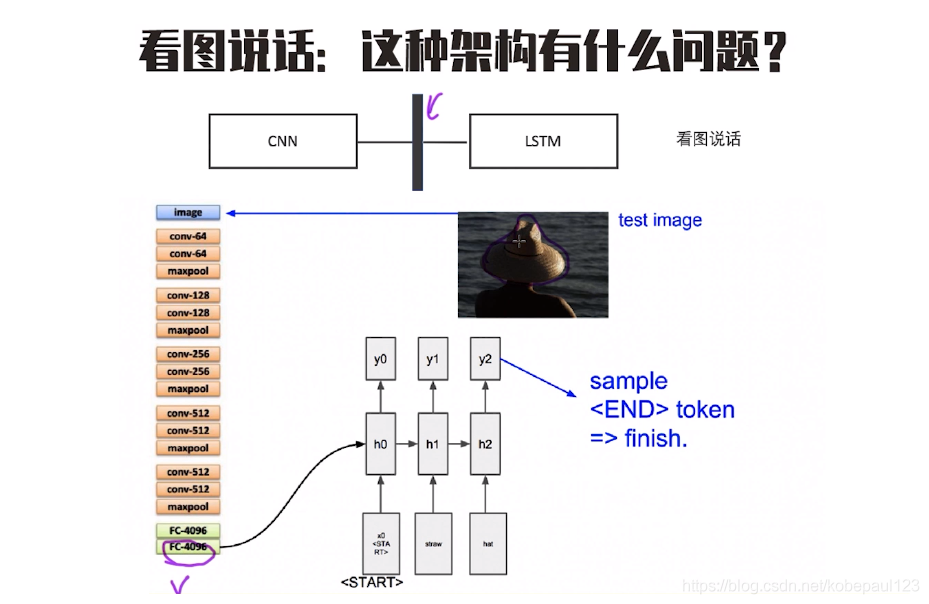
���Կ�����ͼ˵��ʱ,���ɵ��ı�������ȫ��ͼ��Ĵ�����,ʵ���ϲ�����Ҫ����,��Ϊÿһ���ı���ʵ��ӦͼƬ��ijһ���֡�
�������ϵ�����,�������ע�������Ƽ��뵽ģ�͵��С����ڿ�ͼ˵��,һ������˼��:����ÿһ�����ɵĵ���ʵ��������ֻ��Ҫ��עͼƬ��ijһ��ģ��Ϳ����ˡ�������ע������λ�ȡ��?һ�ּIJ�����ʽ��,��ͼƬ�ֳɶ������,Ȼ��ѧ�������ÿ�������Ȩ�ء�
3.����ע��������

���Կ�������ע�������ƺ�,����������ģ�͵Ľ�����,Ҳ����˵�����ı���ʱ���ܹ���ע�����Ӧ��ͼ�������Ƿ���ȷ��
��������ģ���е�ע��������
seq2seq����������˼�����������е�����,�پ�����������һ������(������һ�仰,һ��ͼƬ��)�����һ�����С�����;�кܶ�,�����������,дʫ,����,��ͼд���ֵȵ���;�ܹ㷺��
1.Seq2Seq��һЩ����?
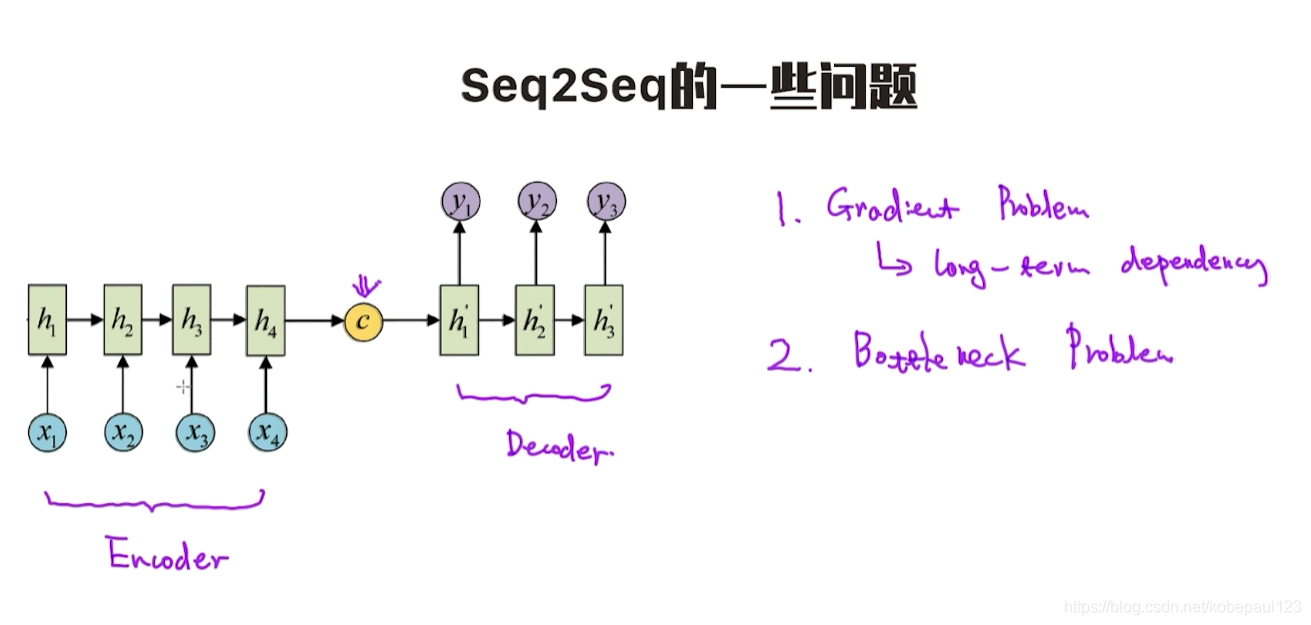
����ͼ��֪,��Ȼ��Ȼ���Դ���������������LSTM��һϵ�иĽ�ģ��,����Ȼ����Ϊ�������������ݶ���ʧ����,�������ڱ���������ѧϰ����һ������,�������������ʾ֮ǰ��һϵ���ı�,���ʹ�ø�����ѧϰ��ʾ����ʮ�����ѡ�
����seq2seq����������������:
- �ݶ���ʧ���⡣
- ƿ�����⡣?
�������ǿ��Խ�ע�����������뵽seq2seq��
2.Seq2Seq����ע��������
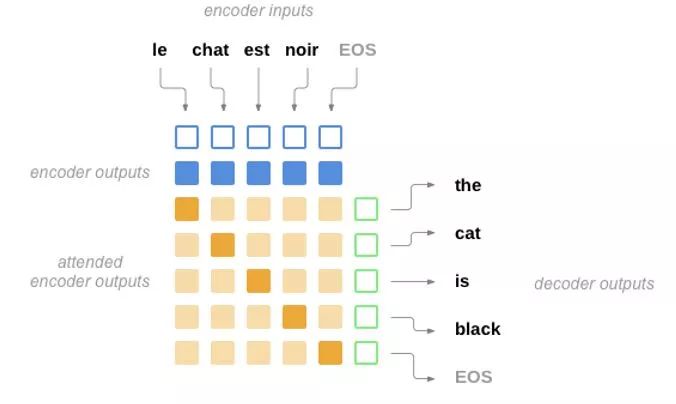
��Щ��ɫ����dz����������ÿ���ʵ�ע�����ķ��䡣
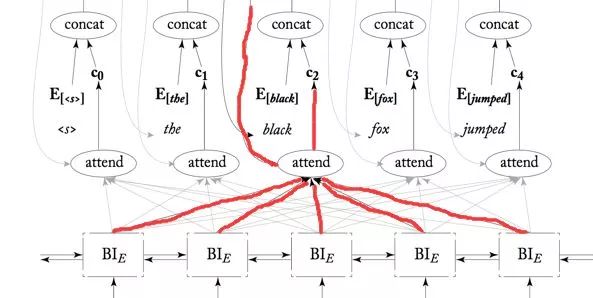
Encoder�õ�����˫��RNN,��RNN��Ԫѭ��������ʱ����һ����������㽫Ҫ����Ĵʶ�Ӧ��attend,����ʱ�϶����������·��Ĵ�Ӧ����ע������е�,��������Ӧ��Ȩ�ؿ϶������ġ�
�����Ȩ�ط��乫ʽΪ:
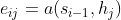
����������������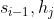 �ǵ�
�ǵ�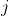 ��Encoder��������ļ��䵥Ԫ��
��Encoder��������ļ��䵥Ԫ��
���еķִ������,Ҫ���¹�һ��:
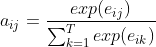
�����Softmax��ࡣ
Ȼ������ǽ�����ʹ���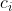 :
:
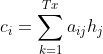
���ע�������ƴ������˻��������������ȻҲ��������������
1.��ע�������ƽ���
self attention��ע���������е�һ��,Ҳ��transformer�е���Ҫ��ɲ��֡�
��ע����������ע�������Ƶı���,������˶��ⲿ��Ϣ������,���ó������ݻ��������ڲ�����ԡ�
��ע�����������ı��е�Ӧ��,��Ҫ��ͨ�����㵥�ʼ�Ļ���Ӱ��,������������������⡣
��ע�������Ƶļ������:
1.�����뵥��ת����Ƕ������;
2.����Ƕ�������õ�q,k,v��������;
3.Ϊÿ����������һ��score:score =q . k ;
4.Ϊ���ݶȵ��ȶ�,Transformerʹ����score��һ��,������?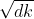 ;
;
5.��scoreʩ��softmax�����;
6.softmax���Valueֵv,�õ���Ȩ��ÿ����������������v;
7.���֮��õ����յ�������z :z=??v��
2. ��ע��������ϸ��
����һ���ı�����,��ע�������ƿ��Լ���ÿ��������֮��Ĺ�ϵ,�����������ϵ�����ⵥ�����������е���˼��ͨ���������ӻ���ʽ,����Ҳ���Թ۲쵽���ֹ�ϵ������,���ַ�ʽ��һ��ȱ�����ڸ��ӶȻ�Ƚϸ�,�ر��Ƕ��ںܳ����ı���
3.λ�ñ���
���ı���,����֮������˳���,�������ᵽ��self-attention��û�а�λ����Ϣ�����˽���,ֻ�Ǽ�����ÿ��������֮��Ĺ�ϵ������������ΰ�λ����Ϣ�ںϵ�ģ�͵�����?��Transformer��,����������˶���ؼ�����λ��������
�ܽ�
ע�������Ƶ��ŵ�
1.������:����� CNN��RNN ,�临�Ӷȸ�С,����Ҳ���١����Զ�������Ҫ��Ҳ��С��
2.�ٶȿ�:Attention ����� RNN�������ģ�� ���ܲ��м�������⡣Attention����ÿһ�����㲻��������һ���ļ�����,��˿��Ժ�CNNһ�����д�����
3.Ч����:��Attention ��������֮ǰ,��һ��������һֱ�ܿ���:���������Ϣ�ᱻ����,�ͺ����������������,�Dz�ס��ȥ��������һ���ġ�
�����Ǵ��㿪ʼѧNLPϵ�����µ�ʮ��ƪ,ϣ��С����Ƕ��֧��,���ཻ����
�ο�:
̰��ѧԺnlp
����ע�������Ƶ�seq2seq����
cs