目录
前言
一、词向量的回顾
1.词向量介绍
2.词向量训练的常见方法
二、基于语言模型的词向量训练
1.语言模型的回顾
2.基于LSTM的词向量训练
3.静态词向量的问题
三、ELMo模型详解
1.ELMo模型概述
2.图像识别中的层次表示
3.ELMo模型
总结
前言
之前的文章中提到,在自然语言任务中最重要的一步就是训练词向量,但是传统的词向量模型,例如 Word2Vec 和 Glove 学习得到的词向量是固定不变的,即一个单词只有一种词向量,显然不适合用于多义词。而 ELMo 算法使用了深度双向语言模型来训练语言模型,而单词的词向量是在输入句子实时获得的,因此词向量与上下文信息密切相关,可以较好地区分歧义。
一、词向量的回顾
1.词向量介绍
词向量在某种意义上可以表示一个单词的含义,所以当我们把词向量在二维或者三维空间里可视化时,就可以看到一些有趣的现象。你会发现,含义类似的单词会聚集在一起,这也从直观上说明词向量确实可以表示一些语义。

2.词向量训练的常见方法
给定语料库的前提下,基于词向量模型我们即可以训练出每个单词的向量。具体的模型包括像SkipGram, CBOW等等。不同模型所训练出来的效果是不一样的,但SkipGram, Glove等为常用的词向量模型,被认为是效果不错的模型。
- 利用CBOW训练出来的词向量,有能力基于中心词预测上下文词。
- 利用SkipGram训练出来的词向量,有能力基于上下文词预测中心词。
二、基于语言模型的词向量训练
1.语言模型的回顾
总体来讲,训练好的语言模型可以用来生成文本:给定一开始的几个单词,接着可通过预测下一个单词的方式来不断生成句子。所以在自然语言处理任务中,只要涉及到生成文本的任务,实际上就是语言模型的作用。
2.基于LSTM的词向量训练

?
LSTM算法全称为Long short-term memory,是一种特殊的 RNN 类型,其是拥有三个“门”结构的特殊网络结构,包括遗忘门、信息增强门以及输出门,并以此来学习长期依赖信息,但是它依然无法解决静态词向量的问题。
3.静态词向量的问题
目前为止讨论的所有词向量模型均为静态词向量,跟词库里的单词是一对一对应的。但显然,这种词向量无法满足实际的场景:一个单词在不同的上下文中可以充当不同的语义。 所以,我们有必要提出一些新型的词向量模型,使得可以捕获单词在上下文中的不同语义,这就是后文提到的ELMo的一个非常重要的作用。
三、ELMo模型详解
1.ELMo模型概述
ELMo是一款极具有历史意义的词向量模型,作为动态词向量技术的开端,为后续这个领域的发展起到了极其重要的作用。ELMo实际上就是深度LSTM模型,借助于图像识别领域的层次表示思想来学习动态词向量,具体的技术细节非常简单,可以理解为基于深度Bi-LSTM训练了一套语言模型,并用这套语言模型来预测一个单词在上下文章的含义。
2.图像识别中的层次表示
层次表示具有很重要的意义,人的大脑也被认为遵循类似的层次认知模式。之后很多人就想,有没有可能把层次表示也应用在自然语言处理任务中? 假如用在了自然语言处理,那它的表现形式又如何呢?
?图片中有层次表示,由低级特征到高级特征。那么自然语言处理中同样存在,从共性特征到高级的语义特征,但我们该如何训练呢?
3.ELMo模型
图像识别中的层次结构是源自于模型的深度,那么,我们是不是也可以把LSTM做成深度模型,这样是否就可以捕获一个单词在上下文中的含义呢?这其实点拔了搭建深度LSTM的必要,并期望这种模型可以用来解决动态词向量问题。幸运的是,实验证明确实有这种现象!

?
ELMo 是Embeeding from Language?Model的缩写,它通过「无监督」的方式对语言模型进行预训练来学习单词表示。
ELMo 是一种动态词向量算法,它最大的特点就是在大型的语料库里训练一个 biLSTM (双向LSTM模型)。下游任务需要获取单词词向量的时候,可以直接将整个句子输入 biLSTM,利用 biLSTM 的输出作为单词的词向量,这样词向量就能包含上下文语义信息。我们也可以简单理解为:biLSTM 是一个函数,函数的输入是一个句子,输出是句子中单词的词向量。
ELMo 中使用的 biLSTM 层数 L = 2,ELMo 首先在大型的数据集上训练好模型,然后再后续任务中可以根据输入的句子,输出每一个单词的词向量。例如给定一个句子 ![T=[t(1),t(2),...,t(N)]](http://style.iis7.com/uploads/2021/09/10242260230.gif) ,ELMo 计算词向量的方法如下:
,ELMo 计算词向量的方法如下:
总结
本文主要对ELMo进行介绍,简单做个总结:
ELMo 训练语言模型,而不是直接训练得到单词的词向量,在后续使用中可以把句子传入语言模型,结合上下文语义得到单词更准确的词向量。
使用了 biLSTM,可以同时学习得到保存上文信息和下文信息的词向量。
biLSTM 中不同层得到的词向量侧重点不同,输入层采用的 CNN-BIG-LSTM 词向量可以比较好编码词性信息,第 1 层 LSTM 可以比较好编码句法信息,第 2 层 LSTM 可以比较好编码单词语义信息。通过多层词向量的融合得到最终词向量,最终词向量可以兼顾多种不同层次的信息。
本文是从零开始学NLP系列文章第十三篇,希望小伙伴们多多支持,互相交流。
cs
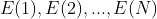 用于输入。ELMo 使用 CNN-BIG-LSTM 生成的词向量作为输入。
用于输入。ELMo 使用 CNN-BIG-LSTM 生成的词向量作为输入。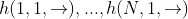 ?,和后向输出
?,和后向输出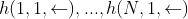 。
。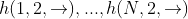 ;将后向输出
;将后向输出 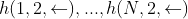 。
。 最终可以得到的词向量包括
最终可以得到的词向量包括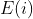 ,
,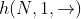 ,
,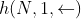 ,
,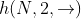 ,
,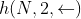 。如果采用 L 层的 biLSTM 则最终可以得到 2L+1 个词向量。
。如果采用 L 层的 biLSTM 则最终可以得到 2L+1 个词向量。