def detect_cards(img):
path="datas\cards.png"
img.save(path)
raw_cards=detect(source=path)
replace_cards=[replace_num[i] if i in replace_num else i for i in raw_cards]
list_cards = sorted(replace_cards, key=lambda x: ranks_value[x])
cards=("".join(list_cards))
return cards
def detect()
# Initialize
set_logging()
# device = select_device(device)
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")#����gpu��������gpu
# half &= device.type != 'cpu' # half precision only supported on CUDA
w = weights[0] if isinstance(weights, list) else weights
classify, pt, onnx = False, w.endswith('.pt'), w.endswith('.onnx') # inference type
stride, names = 64, [f'class{i}' for i in range(1000)] # assign defaults
if pt:
model = attempt_load(weights, map_location=device) # load FP32 model
stride = int(model.stride.max()) # model stride
names = model.module.names if hasattr(model, 'module') else model.names # get class names
if half:
model.half() # to FP16
if classify: # second-stage classifier
modelc = load_classifier(name='resnet50', n=2) # initialize
modelc.load_state_dict(torch.load('resnet50.pt', map_location=device)['model']).to(device).eval()
elif onnx:
check_requirements(('onnx', 'onnxruntime'))
import onnxruntime
session = onnxruntime.InferenceSession(w, None)
dataset = LoadImages(source, img_size=imgsz, stride=stride)
bs = 1 # batch_size
vid_path, vid_writer = [None] * bs, [None] * bs
t0 = time.time()
imgsz = check_img_size(imgsz, s=stride) # check image size
for path, img, im0s, vid_cap in dataset:
if pt:
img = torch.from_numpy(img).to(device)
img = img.half() if half else img.float() # uint8 to fp16/32
elif onnx:
img = img.astype('float32')
img /= 255.0 # 0 - 255 to 0.0 - 1.0
if len(img.shape) == 3:
img = img[None] # expand for batch dim
# Inference
t1 = time_sync()
if pt:
pred = model(img, augment=augment, visualize=visualize)[0]
elif onnx:
pred = torch.tensor(session.run([session.get_outputs()[0].name], {session.get_inputs()[0].name: img}))
# NMS
pred = non_max_suppression(pred, conf_thres, iou_thres, classes, agnostic_nms, max_det=max_det)
t2 = time_sync()
# Second-stage classifier (optional)
if classify:
pred = apply_classifier(pred, modelc, img, im0s)
# Process predictions
for i, det in enumerate(pred): # detections per image
p, s, im0, frame = path, '', im0s.copy(), getattr(dataset, 'frame', 0)
p = Path(p) # to Path
gn = torch.tensor(im0.shape)[[1, 0, 1, 0]] # normalization gain whwh
imc = im0.copy() if save_crop else im0 # for save_crop
if len(det):
# Rescale boxes from img_size to im0 size
det[:, :4] = scale_coords(img.shape[2:], det[:, :4], im0.shape).round()
lists=[]
# Print results
for c in det[:, -1].unique():
n = (det[:, -1] == c).sum() # detections per class
for i in range(n):
lists.append(names[int(c)])
return lists
Ч��������ʾ:


?
�����������ϼҡ������¼�:
ͬ�����ǿ��Ը�����Ϸ��Ļ��ͼ,ʶ�������ͼ��,ȷ�ϵ�����ɫ�����Ĵ�������:��
# ���ҵ�����ɫ
def find_landlord(self, landlord_flag_pos):
for pos in landlord_flag_pos:
result = pyautogui.locateOnScreen('pics/landlord_words.png', region=pos, confidence=self.LandlordFlagConfidence)
if result is not None:
return landlord_flag_pos.index(pos)
return None
Ч��������ʾ:

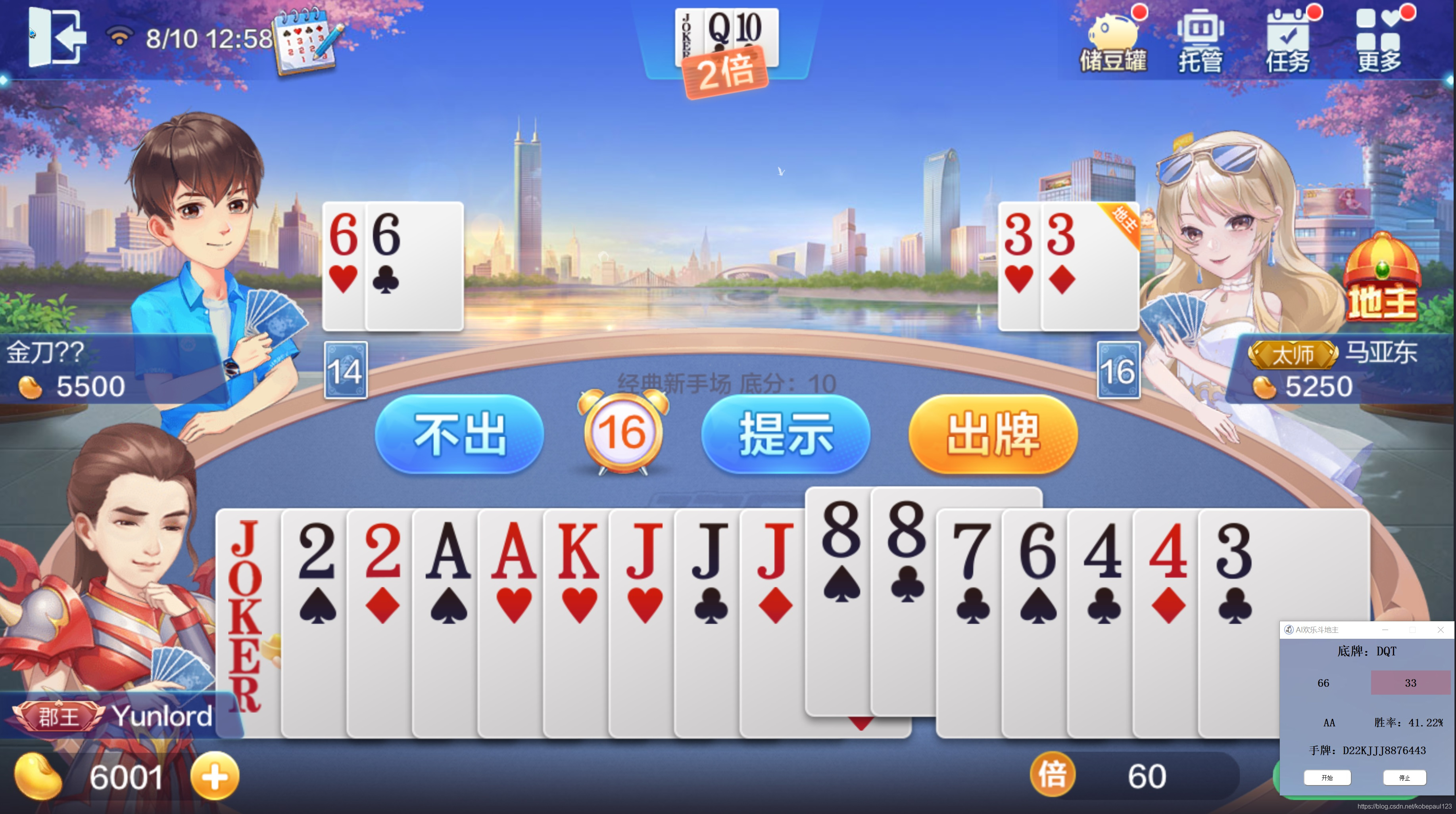
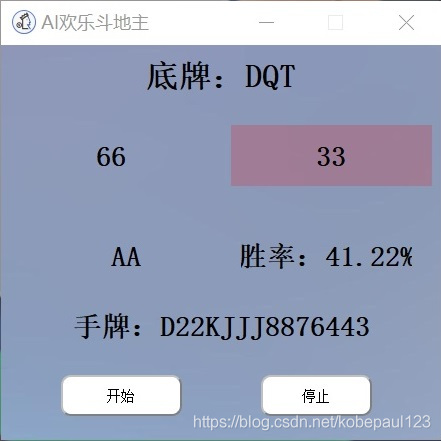
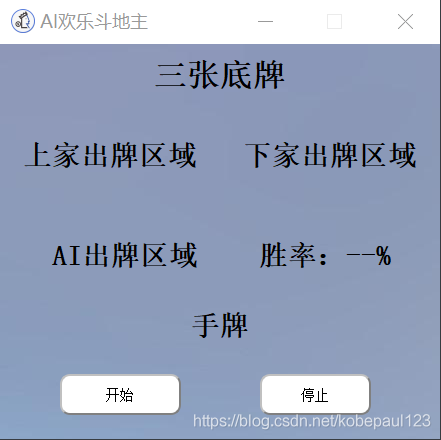
�������ǾͿ��Եõ����AI����,�����������(Ԥ��),�������ŵ���,���߽�ɫ��ϵ,����˳��
3. AI���Ʒ������
��һ����,������Ȼ�ǻ���Dragon�������õ���DouZero��Դ��AI�������ˡ�DouZero��Ŀ��https://github.com/kwai/DouZero��������Ҫ���ÿ�Դ��Ŀ���ز�������Ŀ�С�
����һ��AI��ҽ�ɫ,��ʼ����Ϸ����,����ģ��,����ÿ�ֵij����ж�,����һ����Ϸ���̵Ľ��кͽ�����
�������������Ҫ�ж϶��������������˵ij������,�����ȴ�,����������������������һ��,����ѵ����ResNet50����,����Ӧ�����ͼ�����������н�������״̬���жϡ�����dz��ƵĻ�,��ô�ٽ���Ӧ�����ͼ������YOLOv5�����������ʶ��
���ơ��������ȴ�״̬:
ͬ�����ǿ��Ը�����Ϸ��Ļ��ͼ,ʶ�������˳�������,�ж�������״̬ �����Ĵ�������:
labels=['�ȴ�','����','����']
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")#����gpu��������gpu
model = models.resnet50(pretrained=False)
fc_inputs = model.fc.in_features
model.fc = nn.Sequential(
nn.Linear(fc_inputs, 256),
nn.ReLU(),
nn.Dropout(0.4),
nn.Linear(256, config.NUM_CLASSES),
nn.LogSoftmax(dim=1)
)
pthfile=config.TRAINED_BEST_MODEL
checkpoint = torch.load(pthfile)
model.load_state_dict(checkpoint['model'])
# optimizer.load_state_dict(checkpoint['optimizer'])
start_epoch = checkpoint['epoch']
# test(model, test_load)
model.to(device).eval()
def detect_pass(pos):
img = pyautogui.screenshot(region=pos)
# path="datas\state.png"
time =datetime.datetime.now().strftime(TIMESTAMP)
path="datas\states\state"+'_'+time+'.png'
img.save(path)
# path="datas/states/state_20210807160852.png"
src = cv2.imread(path) # aeroplane.jpg
image = cv2.resize(src, (224, 224))
image = np.float32(image) / 255.0
image[:,:,] -= (np.float32(0.485), np.float32(0.456), np.float32(0.406))
image[:,:,] /= (np.float32(0.229), np.float32(0.224), np.float32(0.225))
image = image.transpose((2, 0, 1))
input_x = torch.from_numpy(image).unsqueeze(0).to(device)
pred = model(input_x)
pred_index = torch.argmax(pred, 1).cpu().detach().numpy()
pred_index=int(pred_index)
print(pred_index)
return pred_index
Ч��������ʾ:?

������,����AI�������������̻����Ѿ�����ˡ�
�����������÷�
������������,���AI�������Ѿ���������ˡ�����Ӧ�����ʹ��?
��������о�Դ��,ֻ��ʹ�����AI������������,��֤��Ч��,��ô���濪ʼ����������û������������AI��������
1. ��������
����������Ҫ��װ��Щ��������,������ػ���,������ʾ:
torch==1.9.0
GitPython==3.0.5
gitdb2==2.0.6
PyAutoGUI==0.9.50
PyQt5==5.13.0
PyQt5-sip==12.8.1
Pillow>=5.2.0
opencv-python
rlcard
2. �������ȷ��
���ǿ��Դ�������Ϸ����,��AI������������Ҫ�������½�,ֻҪ��Ҫ�ڵ����ơ�������־�����ơ���ʷ������Щ�ؼ�λ��,�Ϳ��ԡ�
�������Ҫȷ����Ļ��ͼ��ȡ�ĸ��������Ƿ���ȷ�������������Ҫ��������λ�����������
# ����
self.MyHandCardsPos = (110, 1310, 3620, 600) # �ҵĽ�ͼ����
self.LPlayedCardsPos = (880, 340, 1020, 545) # ��߽�ͼ����
self.RPlayedCardsPos = (1940, 340, 1020, 545) # �ұ߽�ͼ����
self.LandlordFlagPos = [ (105, 545, 240, 260), (640, 1190, 240, 260), (3475, 545, 240, 260)] # ������־��ͼ����(��-��-��)
self.ThreeLandlordCardsPos = (1770, 50, 300, 170) # �������ƽ�ͼ����,resize��349x168
���������,������:

3. �����
�����л����������,����������λ��ȷ������֮��,�������ǾͿ���ֱ�����г���,����Ч����~
������������AI����������,���ֶ�������Ϸ����,������Ϸ������Ҿ�λ,���Ʒַ����,��������ȷ��֮��,���ǾͿ��Ե�������п�ʼ��ť,��AI���������Ƕ������ˡ�
�������һ�����������AI��������ʵ��Ч���,����AI����δ���ũ�����,ȡ��ʤ����!
?
����������AI������!
cs