def load_dataset(path, pad_size=32):
contents = []
with open(path, 'r', encoding='UTF-8') as f: # 读取数据
for line in tqdm(f):
lin = line.strip()
if not lin:
continue
if len(lin.split('\t')) == 2:
content, label = lin.split('\t')
token = config.tokenizer.tokenize(content) # 分词
token = [CLS] + token # 句首加入CLS
seq_len = len(token)
mask = []
token_ids = config.tokenizer.convert_tokens_to_ids(token)
if pad_size:
if len(token) < pad_size:
mask = [1] * len(token_ids) + [0] * (pad_size - len(token))
token_ids += ([0] * (pad_size - len(token)))
else:
mask = [1] * pad_size
token_ids = token_ids[:pad_size]
seq_len = pad_size
contents.append((token_ids, int(label), seq_len, mask))
return contents
调用tokenizer,使用tokenizer分割输入,将数据转换为特征。
特征中包含4个数据:
- tokens_ids:分词后每个词语在vocabulary中的id,补全符号对应的id为0,[CLS]和[SEP]的id分别为101和102。应注意的是,在中文BERT模型中,中文分词是基于字而非词的分词。
- mask:真实字符/补全字符标识符,真实文本的每个字对应1,补全符号对应0,[CLS]和[SEP]也为1。
- seq_len:句子长度
- label?:将label_list中的元素利用字典转换为index标识。
转换特征中一个元素的例子是:
输入:剧情有的承接欠缺,画面人设很棒。????3
tokens_ids:[101, 1196, 2658, 3300, 4638, 2824, 2970, 3612, 5375, 8024, 4514, 7481, 782, 6392, 2523, 3472, 511, 0,...,0]
mask:[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,...,0]
label:3
seq_len:17?
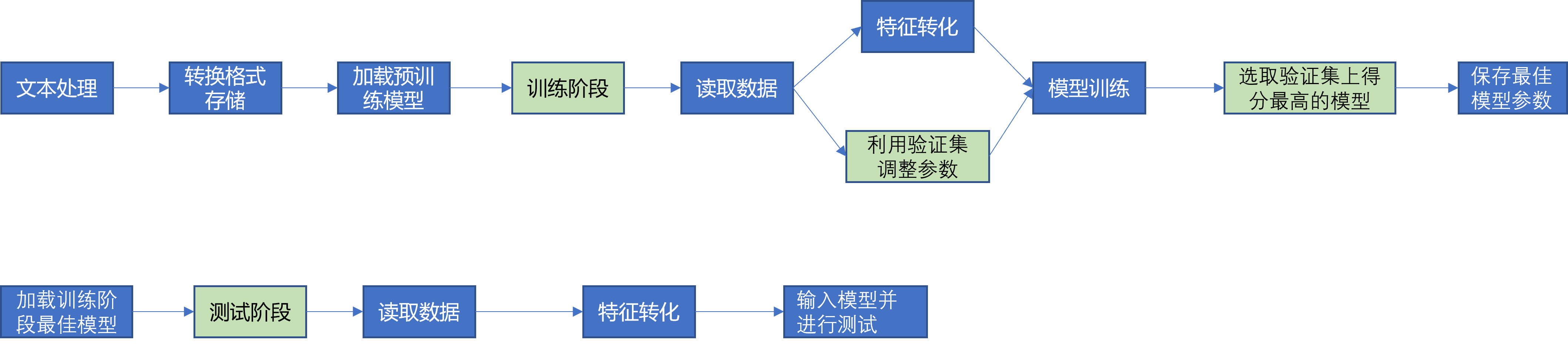
2.模型训练
完成读取数据、特征转换之后,将特征送入模型进行训练。
训练算法为BERT专用的Adam算法
训练集、测试集、验证集比例为6:2:2
每100轮会在验证集上进行验证,并给出相应的准确值,如果准确值大于此前最高分则保存模型参数,否则flags加1。如果flags大于1000,也即连续1000轮模型的性能都没有继续优化,停止训练过程。
for epoch in range(config.num_epochs):
print('Epoch [{}/{}]'.format(epoch + 1, config.num_epochs))
for i, (trains, labels) in enumerate(train_iter):
outputs = model(trains)
model.zero_grad()
loss = F.cross_entropy(outputs, labels)
loss.backward()
optimizer.step()
if total_batch % 100 == 0:
# 每多少轮输出在训练集和验证集上的效果
true = labels.data.cpu()
predic = torch.max(outputs.data, 1)[1].cpu()
train_acc = metrics.accuracy_score(true, predic)
dev_acc, dev_loss = evaluate(config, model, dev_iter)
if dev_loss < dev_best_loss:
dev_best_loss = dev_loss
torch.save(model.state_dict(), config.save_path)
improve = '*'
last_improve = total_batch
else:
improve = ''
time_dif = get_time_dif(start_time)
msg = 'Iter: {0:>6}, Train Loss: {1:>5.2}, Train Acc: {2:>6.2%}, Val Loss: {3:>5.2}, Val Acc: {4:>6.2%}, Time: {5} {6}'
print(msg.format(total_batch, loss.item(), train_acc, dev_loss, dev_acc, time_dif, improve))
model.train()
total_batch += 1
if total_batch - last_improve > config.require_improvement:
# 验证集loss超过1000batch没下降,结束训练
print("No optimization for a long time, auto-stopping...")
flag = True
break
if flag:
break
test(config, model, test_iter)
?训练结果:
1245it [00:00, 6290.83it/s]Loading data...
170004it [00:28, 6068.60it/s]
42502it [00:07, 6017.43it/s]
42502it [00:06, 6228.82it/s]
Time usage: 0:00:42
Epoch [1/5]
Iter: ? ? ?0, ?Train Loss: ? 1.8, ?Train Acc: ?3.12%, ?Val Loss: ? 1.7, ?Val Acc: ?9.60%, ?Time: 0:02:14 *
Iter: ? ?100, ?Train Loss: ? 1.5, ?Train Acc: 25.00%, ?Val Loss: ? 1.4, ?Val Acc: 20.60%, ?Time: 0:05:10 *
...
Iter: ? 5300, ?Train Loss: ?0.75, ?Train Acc: 65.62%, ?Val Loss: ? 1.0, ?Val Acc: 50.07%, ?Time: 2:45:41 *
Epoch [2/5]
Iter: ? 5400, ?Train Loss: ? 1.0, ?Train Acc: 62.50%, ?Val Loss: ? 1.0, ?Val Acc: 51.02%, ?Time: 2:48:46?
...
Iter: ? 7000, ?Train Loss: ?0.77, ?Train Acc: 75.00%, ?Val Loss: ? 1.0, ?Val Acc: 52.84%, ?Time: 3:38:26?
No optimization for a long time, auto-stopping...
Test Loss: ? 1.0, ?Test Acc: 50.89%
Precision, Recall and F1-Score...
? ? ? ? ? ? ? precision ? ?recall ?f1-score ? support
? ? ? ? ? ?1 ? ? 0.6157 ? ?0.5901 ? ?0.6026 ? ? ?3706
? ? ? ? ? ?2 ? ? 0.5594 ? ?0.1481 ? ?0.2342 ? ? ?3532
? ? ? ? ? ?3 ? ? 0.4937 ? ?0.5883 ? ?0.5369 ? ? ?9678
? ? ? ? ? ?4 ? ? 0.4903 ? ?0.5459 ? ?0.5166 ? ? 12899
? ? ? ? ? ?5 ? ? 0.6693 ? ?0.6394 ? ?0.6540 ? ? 12687
? ? accuracy ? ? ? ? ? ? ? ? ? ? ? ? 0.5543 ? ? 42502
? ?macro avg ? ? 0.5657 ? ?0.5024 ? ?0.5089 ? ? 42502
weighted avg ? ? 0.5612 ? ?0.5543 ? ?0.5463 ? ? 42502
Time usage: 0:02:25
从训练结果可以看出准确率和F1分数最多只能达到60%,其实仔细分析评论也可以知道原因:
相近分数的差异性与评论相关性不大,比如两分的评论可能有时候与一分三分是一样的,这就导致很难根据评论准确的预测出分数,但是从测试结果可以明显的看出好评和差评能够明显区分出来,准确率能达到百分之九十。?
3.模型测试
测试的时候与训练同样的原理,也是先将数据转化为特征,送入训练好的模型中,得到结果。
def final_predict(config, model, data_iter):
map_location = lambda storage, loc: storage
model.load_state_dict(torch.load(config.save_path, map_location=map_location))
model.eval()
predict_all = np.array([])
with torch.no_grad():
for texts, _ in data_iter:
outputs = model(texts)
pred = torch.max(outputs.data, 1)[1].cpu().numpy()
pred_label = [match_label(i, config) for i in pred]
predict_all = np.append(predict_all, pred_label)
return predict_all
def main(text):
config = Config()
model = Model(config).to(config.device)
test_data = load_dataset(text, config)
test_iter = build_iterator(test_data, config)
result = final_predict(config, model, test_iter)
for i, j in enumerate(result):
print('text:{}'.format(text[i]))
print('label:{}'.format(j))
?测试结果:

总结?
本项目基于pytorch的 BERT中文文本分类实现豆瓣评分预测,通过以实际数据测试,还是有一定的效果,不得不说目前BERT在自然语言处理任务中效果还是杠杠的!
希望能不断推陈出新,推动NLP进一步发展!!!
今天我们就到这里,明天继续努力!

如果该文章对您有所帮助,麻烦点赞,关注,收藏三连支持下!
创作不易,白嫖不好,各位的支持和认可,是我创作的最大动力!
如果本篇博客有任何错误,请批评指教,不胜感激 !!!
参考:?
如何使用BERT实现中文的文本分类(附代码)
EasyBert,基于Pytorch的Bert应用
cs