Ŀ¼
ǰ��
һ��HMM����
����HMM����
����HMM��������������
1.���ʼ�������
2. ѧϰ����
3.Ԥ������
�ġ�HMM�еIJ�������
1.ǰ���㷨
2.�����㷨
�塢HMMʵ��
�ܽ�
ǰ��
��һ���Ѿ�����������ģ��,�ᵽ�������Ʒ����,�������ص���ܵ��������Ʒ�ģ��,����������������Ƶ����⡣�������ɷ�ģ��(Hidden Markov model, HMM)��һ�ֽṹ��Ķ�̬��Ҷ˹��������ģ��,��Ҳ��һ������������ͼģ�͡����ǵ��͵���Ȼ�����д�����ע�����ͳ�ƻ���ѧģ��,���½��ص�������־���Ļ���ѧϰģ�͡�
һ��HMM����
HMM��Ϊ���������ģ��,�㷺Ӧ���ڸ���AI�����С�����,HMM�������֮��������Ϊ������ʶ�����������ѧϰ����֮ǰ,��������ʶ��ϵͳ������HMMģ��,Ҳ���Ǿ����еľ����ˡ�����,HMM���ı�����Ҳ���źܶ��Ӧ�������ķִʡ�
����֮��,����HMM���ں���ѧϰRNNģ����˵���űȽϴ������,��Ϊ�����ߺ�����,����Լ���ΪHMM�Ǵ�ͳ������ģ��,RNNΪ�������ѧϰ������ģ�͡�
��������������ʲô����������������HMMģ�͡�ʹ��HMMģ��ʱ���ǵ�����һ��������������:
- ���ǵ������ǻ������е�,����ʱ������,���Ʊ���ı������µȵ�,����״̬���С�
- ���ǵ�����������������,һ�����������ǿ��Թ۲��,���۲�����;����һ�������Dz��ܹ۲쵽��,������״̬����,���״̬���С�
��������������,��ô�������һ�������HMMģ�������Խ����������������ʵ���������Ǻܶ�ġ�����:˵����˵�����������ǹ۲�����,��ʵ�ʱ������˼����״̬����,�Ƕ������ߵ�������Ǵ���һϵ���������ж�˵������Ҫ��������ݡ�
��һ����������Ӿ���Ͷ����ȷ�����ӡ�
����������������ͬ�����ӡ���һ������������ƽ����������(���������ΪD6),6����,ÿ����(1,2,3,4,5,6)���ֵĸ�����1/6���ڶ��������Ǹ�������(���������ΪD4),ÿ����(1,2,3,4)���ֵĸ�����1/4�������������а˸���(���������ΪD8),ÿ����(1,2,3,4,5,6,7,8)���ֵĸ�����1/8,��ͼ��ʾ:
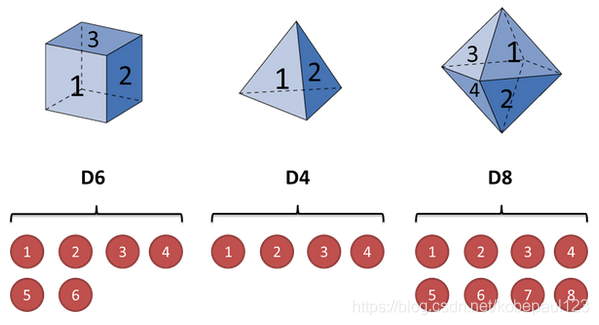
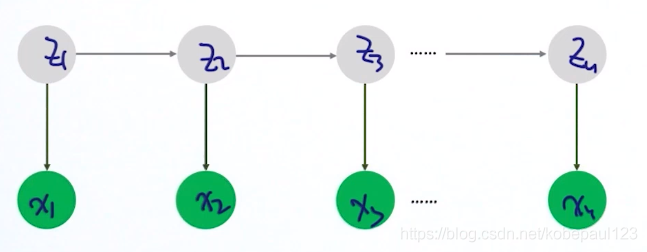
�������ɷ�ģ��ʾ��ͼ������ʾ:

ͼ��,��ͷ��ʾ����֮���������ϵ,˵��������ʾ:
Ҳ����˵������ʱ��,�۲����(����)��������״̬����(��������),ͬʱ ʱ�̵�״̬
ʱ�̵�״̬ ��������
��������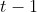 ʱ�̵�״̬
ʱ�̵�״̬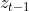 ������������Ʒ���,��ϵͳ����һʱ�̽��ɵ�ǰ״̬(����)������
������������Ʒ���,��ϵͳ����һʱ�̽��ɵ�ǰ״̬(����)������
����HMM����
�������������,���Եõ��������ɷ�ģ�͵Ķ��塣
�������Ʒ�ģ���ǹ���ʱ��ĸ���ģ��,������һ�����ص������ɷ���������ɲ��ɹ۲��״̬�������,���ɸ���״̬����һ���ɹ۲��������еĹ���,���ص������ɷ���������ɵ�״̬����,��Ϊ״̬����(Ҳ�����������е�D6,D8��);ÿ��״̬����һ���۲�,���ɴ˲����Ĺ۲��������,��Ϊ�۲�����(Ҳ�����������е�1,6��)�����е�ÿ��λ���ֿ��Կ�����һ��ʱ�̡�
?
�������ɷ�ģ������ʼ�ĸ��ʷֲ���״̬ת�Ƹ��ʷֲ��Լ��۲�����ֲ�ȷ�����������ʽ����,������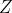 �����п��ܵ�״̬�ļ���,
�����п��ܵ�״̬�ļ���,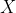 �����п��ܵĹ۲�ļ���,����:
�����п��ܵĹ۲�ļ���,����:
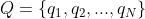
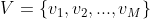
����,N�ǿ��ܵ�״̬��,M�ǿ��ܹ۲������������?�dz���Ϊ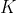 ��״̬����,�Ƕ�Ӧ�Ĺ۲�����:
��״̬����,�Ƕ�Ӧ�Ĺ۲�����:
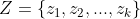
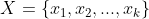
����Ȼ���Ƶ���,���������ɷ�ģ����,��3���������,�ֱ���״̬ת�Ƹ��ʾ���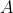 ,�۲���ʾ���
,�۲���ʾ���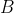 ,�Լ���ʼ״̬��������
,�Լ���ʼ״̬��������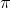 ��
��
״̬ת�Ƹ��ʾ���Ϊ:

����,
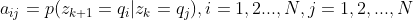
����ʱ������״̬ ������������״̬
������������״̬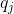 �ĸ��ʡ�
�ĸ��ʡ�
�۲���ʾ���Ϊ:
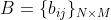
����,
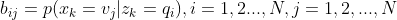
����ʱ������״̬������������״̬�ĸ��ʡ�
��ʼ״̬��������Ϊ:
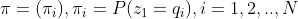
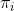 Ϊʱ��
Ϊʱ��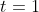 ����״̬�ĸ��ʡ�
����״̬�ĸ��ʡ�
�ɴ�,�����Ƶ�����ʼ״̬��������,״̬ת�Ƹ��ʾ����۲���ʾ������ܾ���һ���������ɷ�ģ�͡�������״̬����,�����۲�����,Ҳ����Ϊ�������Ʒ�ģ�͵���Ҫ�������HMM��������Ԫ���ű�ʾΪ:
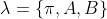
�Ӷ�����,���Է����������ɷ�ģ������������������:
- �����ɷ�����Լ���,���������ص������ɷ���������ʱ��t��״ֻ̬��������ǰһʱ�̵�״̬,������ʱ�̵�״̬���۲���,Ҳ��ʱ���ء�
- �۲�����Լ���,����������ʱ�̵Ĺ۲�ֻ�����ڸ�ʱ�̵������ɷ�����״̬,�������۲⼰״̬�ء�
����HMM��������������
����������������ӡ���Ͷ����ȷ������,�����������Ʒ�ģ����ص������㷨�Լ����ֻ������⡣
1.���ʼ�������
����ģ���۲�����,�����ڸ�ģ���¹۲��������ֵĸ���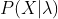 ��
��
ͨ����˵,����֪�������м���(����״̬����),ÿ��������ʲô(ת������),���������������Ľ��(�۲�����),�õ������������ĸ��ʡ�
��������������岻��,��Ϊ�������Ľ���ܶ�ʱ��Ӧ��һ���Ƚϴ�ĸ��ʡ���������Ŀ����ʵ�Ǽ��۲쵽�Ľ������֪��ģ���Ƿ��Ǻϡ�����ܶ�ν������Ӧ�˱Ƚ�С�ĸ���,��ô��˵��������֪��ģ�Ͳ������п����Ǵ��ġ�
2. ѧϰ����
��֪�۲�����,����ģ������,ʹ���ڸ�ģ���¹۲����и������,���ü�����Ȼ���Ƶķ������Ʋ�����
ͨ����˵,����֪�������м���(����״̬����),��֪��ÿ��������ʲô(ת������),�۲�ܶ�������ӵĽ��(�۲�����),�뷴�Ƴ�ÿ��������ʲô(ת������)��
����������Ҫ,��Ϊ���������������ܶ�ʱ������ֻ�пɼ����,��֪��HMMģ����IJ���,������Ҫ�ӿɼ�������Ƴ���Щ����,���ǽ�ģ��һ����Ҫ���衣
3.Ԥ������
��֪ģ���۲�����,��Ը����۲�������������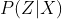 ����״̬����,�������۲�����,�����п��ܵĶ�Ӧ��״̬���С�
����״̬����,�������۲�����,�����п��ܵĶ�Ӧ��״̬���С�
ͨ����˵,����֪�������м���(����״̬����),ÿ��������ʲô(ת������),���������������Ľ��(�۲�����),��֪��ÿ���������Ķ�����������(����״̬��)��
�������,������ʶ��������,�����������⡣�ýⷨ�����������Ȼ״̬·��,˵ͨ����,������һ����������,ʹ����������в����۲����ĸ����������˵,��֪��������������,������,������,����������Ҳ֪��������ʮ�εĽ��(1 6 3 5 2 7 3 5 2 4),�Ҳ�֪��ÿ��������������,����֪�����п��ܵ��������С���ʵ��������ķ�������������п��ܵ���������,Ȼ���ÿ�����ж�Ӧ�ĸ��������,������Ǵ�����Ѷ�Ӧ�����ʵ����������������ˡ���������ɷ�������,��Ȼ���С�������Ļ�,��ٵ�����̫��,���ǵ�Ԥ��״̬�������,�㷨��ʱ�临�Ӷ���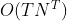 �ġ�
�ġ�
�������ǵó�����,�����㷨�����ﲢ��ʵ��,���Ǿ�������ǰ������㷨�����Ƕ��ǻ��ڶ�̬�滮˼�������
�ġ�HMM�еIJ�������
Forward/Backward�㷨�ڹ���HMM�����а��ݺ���Ҫ�Ľ�ɫ�����仰˵,�ڹ���HMM����������,���õ�Forward/Backward�㷨�Ľ��������,���������ȸ���ҽ���ʲô��ǰ������㷨��
1.ǰ���㷨
ǰ���㷨���������ڶ�̬�滮���㷨,Ҳ��������Ҫͨ���ҵ��ֲ�״̬���ƵĹ�ʽ,����һ�����Ĵ�����������Ž���չ��������������Ž⡣
�������ȶ���һ��ǰ����ʡ�
ǰ�����:�����������Ʒ�ģ��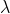 ,����ʱ,�۲�����Ϊ������״̬Ϊ�ĸ���Ϊǰ�����,��Ϊ:
,����ʱ,�۲�����Ϊ������״̬Ϊ�ĸ���Ϊǰ�����,��Ϊ:
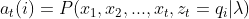
��Ȼ�Ƕ�̬�滮,���Լ����Ѿ��õ���ʱ��ʱ��������״̬��ǰ�����,�������ǾͿ��Ե��Ƶij�ʱ��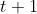 ʱ��������״̬��ǰ����ʡ�
ʱ��������״̬��ǰ����ʡ�
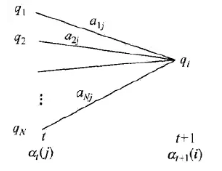
����ͼ���Ի���ʱ��tʱ��������״̬��ǰ�����,�ٳ��Զ�Ӧ��״̬ת�Ƹ���,��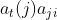 ������ʱ���۲
������ʱ���۲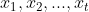 ,����ʱ������״̬
,����ʱ������״̬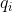 �ĸ���,�ɴ����Ե��Ƶ����ǰ�����
�ĸ���,�ɴ����Ե��Ƶ����ǰ�����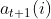 ���۲����и���
���۲����и���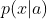 ������IJ���Ϊ:
������IJ���Ϊ:
(1)����ǰ����ʹ�ʽ,���趨 �ij�ֵ:
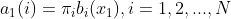
(2)����ǰ����ʹ�ʽ��ǰ����ʽ��е���,��˶�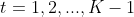 ,��:
,��:
![a_{t+1}(i)=[\sum_{j=1}^{N}a_{t}(j)a_{ji}]b_i(x_{t+1}),i=1,2,...,N](https://latex.codecogs.com/gif.latex?a_%7Bt+1%7D%28i%29%3D%5B%5Csum_%7Bj%3D1%7D%5E%7BN%7Da_%7Bt%7D%28j%29a_%7Bji%7D%5Db_i%28x_%7Bt+1%7D%29%2Ci%3D1%2C2%2C...%2CN)
(3)�������е�ǰ����ʽ�����͵õ����յĽ��,��Ϊ:
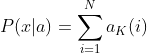
���ڵ���ʱ��T,һ����N��״̬����������Ǹ��۲�,�������յĽ��Ҫ����Щ���ʼ�����(��Ϊÿ����״̬�����ܲ���������Ҫ�Ĺ۲�ֵ,���Զ�Ҫ������)������ÿ�ε��ƶ�����ǰһ�εĻ����Ͻ��е�,���Խ����˸��Ӷ�(����ֻ���������ڵ�����ʱ���)��ÿ��ʱ��㶼�� ��״̬,������������ʱ��֮��ĵ�������
��״̬,������������ʱ��֮��ĵ������� �μ��㡣��ÿ�ε��ƶ�����ǰһ�εĻ���������,����ֻ���ۼ�
�μ��㡣��ÿ�ε��ƶ�����ǰһ�εĻ���������,����ֻ���ۼ� ��,�������帴�Ӷ���
��,�������帴�Ӷ���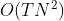 �������֮ǰ�ᵽ�ı����㷨��ָ�������Ӷ��Ѿ��������ࡣ
�������֮ǰ�ᵽ�ı����㷨��ָ�������Ӷ��Ѿ��������ࡣ
2.�����㷨
���������ǰ����ʷdz�����,Ҳ�ǻ�����̬�滮��˼��,Ψһ��������ѡ��ľֲ�״̬��ͬ,�����㷨�õ��ǡ�������ʡ�,��ô�����������ζ������?�������һ��:
���ȸ���������ʶ���:
�������:�����������ɷ�ģ��,������ʱ��״̬Ϊ��������,�����IJ��ֹ۲�����Ϊ
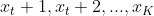 �ĸ���Ϊ�������,����:
�ĸ���Ϊ�������,����:
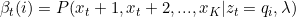
������ʵĶ�̬�滮���ƹ�ʽ��ǰ��������෴�ġ������Ѿ��õ���ʱ��������״̬�ĺ������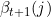 ,����������Ҫ���Ƴ�ʱ��ʱ��������״̬�ĺ�����ʡ�
,����������Ҫ���Ƴ�ʱ��ʱ��������״̬�ĺ�����ʡ�
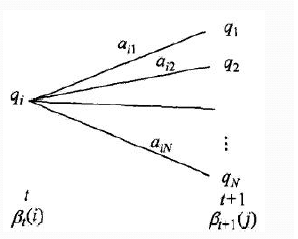
����ͼ,���Լ�����۲�״̬������Ϊ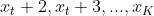 ,ʱ����״̬Ϊ,ʱ������״̬Ϊ�ĸ���Ϊ
,ʱ����״̬Ϊ,ʱ������״̬Ϊ�ĸ���Ϊ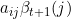 ���ɴ˿����õ��Ƶķ�����ú������
���ɴ˿����õ��Ƶķ�����ú������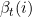 ,���۲����и���
,���۲����и���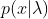 ,������������㷨���㷨����:
,������������㷨���㷨����:
����:�������ɷ�ģ��,�۲�����
���:�۲����и���
(1)��ʼ��ʱ���ĸ�������״̬�������:
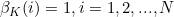
(2)���ݺ�����ʹ�ʽ�Ժ�����ʽ��е���,��˶�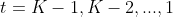 ,��:
,��:
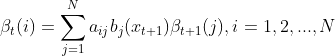
(3)�������е�ǰ����ʽ�����͵õ����յĽ��,��Ϊ:
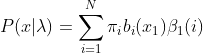
�塢HMMʵ��
����������һ����ʵ������������������HMMģ�͡�����һ�����������ģ��,������Դ����ġ�ͳ��ѧϰ��������
����������3������,ÿ�������ﶼ�к�ɫ�Ͱ�ɫ������,��������������������ֱ���:
| ���� | 1 | 2 | 3 |
| ������ | 5 | 4 | 7 |
| ������ | 5 | 6 | 3 |
��������ķ����Ӻ��������,��ʼ��ʱ��,�ӵ�һ�����ӳ���ĸ�����0.2,�ӵڶ������ӳ���ĸ�����0.4,�ӵ��������ӳ���ĸ�����0.4����������ʳ�һ�����,����Żء�Ȼ��ӵ�ǰ����ת�Ƶ���һ�����ӽ��г�������:�����ǰ����ĺ����ǵ�һ������,����0.5�ĸ�����Ȼ���ڵ�һ�����Ӽ�������,��0.2�ĸ���ȥ�ڶ������ӳ���,��0.3�ĸ���ȥ���������ӳ��������ǰ����ĺ����ǵڶ�������,����0.5�ĸ�����Ȼ���ڵڶ������Ӽ�������,��0.3�ĸ���ȥ��һ�����ӳ���,��0.2�ĸ���ȥ���������ӳ��������ǰ����ĺ����ǵ���������,����0.5�ĸ�����Ȼ���ڵ��������Ӽ�������,��0.2�ĸ���ȥ��һ�����ӳ���,��0.3�ĸ���ȥ�ڶ������ӳ��������ȥ,ֱ���ظ�����,�õ�һ�������ɫ�Ĺ۲�����:?X={��,��,��}��
�����������,�۲���ֻ�ܿ��������ɫ����,ȴ���ܿ������Ǵ��ĸ�������ȡ���ġ�
�������������ݵĽ���:
�۲⼯����:V={��,��},M=2
״̬������:Q={1,2,3},N=3
���۲����к�״̬���г�Ϊ3��
��ʼ״̬����: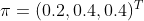
״̬ת�ƾ���:
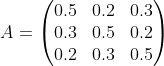
�۲�״̬����:
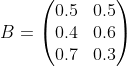
�������ǽ�����ʼ���������
����֮ǰ��˵���㷨,���ȼ���ʱ��1����״̬��ǰ�����:
ʱ��1�Ǻ�ɫ��,����״̬�Ǻ���1�ĸ���Ϊ:

ʱ��1�Ǻ�ɫ��,����״̬�Ǻ���2�ĸ���Ϊ:
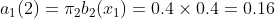
ʱ��1�Ǻ�ɫ��,����״̬�Ǻ���1�ĸ���Ϊ:
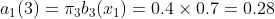
���ڿ��Կ�ʼ����,���ȵ���ʱ��2����״̬��ǰ�����:
ʱ��2�ǰ�ɫ��,����״̬�Ǻ���1�ĸ�����:
![a_{2}(1)=[\sum_{j=1}^{3}a_{1}(j)a_{j1}]b_1(x_{2})=0.077](http://style.iis7.com/uploads/2021/09/10305060384.gif)
ʱ��2�ǰ�ɫ��,����״̬�Ǻ���2�ĸ�����:
![a_{2}(2)=[\sum_{j=1}^{3}a_{1}(j)a_{j2}]b_2(x_{2})=0.1104](http://style.iis7.com/uploads/2021/09/10305160385.gif)
ʱ��2�ǰ�ɫ��,����״̬�Ǻ���3�ĸ�����:
![a_{2}(3)=[\sum_{j=1}^{3}a_{1}(j)a_{j3}]b_3(x_{2})=0.0606](http://style.iis7.com/uploads/2021/09/10305260386.gif)
��������,�������ǵ���ʱ��3����״̬��ǰ�����:
ʱ��3�Ǻ�ɫ��,����״̬�Ǻ���1�ĸ�����:
![a_{3}(1)=[\sum_{j=1}^{3}a_{2}(j)a_{j1}]b_1(x_{3})=0.04187](http://style.iis7.com/uploads/2021/09/10305360387.gif)
ʱ��3�Ǻ�ɫ��,����״̬�Ǻ���2�ĸ�����:
![a_{3}(2)=[\sum_{j=1}^{3}a_{2}(j)a_{j2}]b_2(x_{3})=0.03551](http://style.iis7.com/uploads/2021/09/10305560388.gif)
ʱ��3�Ǻ�ɫ��,����״̬�Ǻ���3�ĸ�����:
![a_{3}(2)=[\sum_{j=1}^{3}a_{2}(j)a_{j3}]b_3(x_{3})=0.05284](http://style.iis7.com/uploads/2021/09/10305660389.gif)
������������۲�����:X={��,��,��}�ĸ�����:
?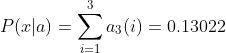
�ܽ�
��HMM��,���������,һ����ģ�ͱ����IJ���,����һ���������� �����Һ���ͬʱ����������������,���Բ��õ�һ�ַ�����:������һ����������dz���(constant),�Ӷ���������һ�����,�Դ����ơ���������,��ģ�Ͳ��������dz���,���Ʊ���;�������dz���,����ģ�Ͳ���;?��ģ�Ͳ��������dz���,���Ʊ���;�������dz���,����ģ�Ͳ���...��?һֱѭ��������Ϊֹ��
�����Һ���ͬʱ����������������,���Բ��õ�һ�ַ�����:������һ����������dz���(constant),�Ӷ���������һ�����,�Դ����ơ���������,��ģ�Ͳ��������dz���,���Ʊ���;�������dz���,����ģ�Ͳ���;?��ģ�Ͳ��������dz���,���Ʊ���;�������dz���,����ģ�Ͳ���...��?һֱѭ��������Ϊֹ��
����HMM,�������ܽ�:
- HMM�Ǻ����е�����ģ��,�㷺Ӧ��������ʶ�������
- HMMҲ�������ڴ��Ա�ע��ʵ��ʶ����ı�������
- HMM��inference����ʵ�����Ƕ������е�Ԥ�����,Ҫ�õ�ά�ر��㷨
- ά�ر��㷨ʵ�����Ƕ�̬�滮�㷨
- HMM�IJ�������ʵ������ģ��ѵ������,��Ҫ�������ͬ�IJ���
- HMM�IJ������ƹ���Ҫ�õ�EM�㷨,����EM�㷨�Ľ�������ڳ�ʼ���������ͬ�ij�ʼ���ܿ��ܴ�����һ����Ч��
- HMM�IJ���������,�м����ؼ���ģ����F/B�㷨,Forward�㷨,Backward�㷨��
����һ�¿�ʼ,�����������һ�����е�����ģ�ͽ������������(CRF),���ı������õ÷dz��ࡣ
�ο�:
̰��ѧԺnlp
�������ɷ�ģ��(HMM)���
�������ɷ�ģ������ϸ���� HMM(Hidden Markov Model)
���ʦ-��ͳ��ѧϰ������
cs