ЧчХЯ:БхРскН Raymond ЧӘФШЗлЧўГчіцҙҰ
Email:colorant at 163.com
BLOG:http://blog.csdn.net/colorant/
ёь¶аВЫОДФД¶БұКјЗ?http://blog.csdn.net/column/details/cloudpaper.html
?
== ДҝұкОКМв ==
?
TAOөДДҝұкОКМвКЗ№№ҪЁТ»ёцФЪFacebookХвСщҙу№жДЈөДЙзҪ»Аа·ЦІјКҪУҰУГ·юОсЦР,ДЬ№»ҙУәЈБҝПа№ШБӘөДКэҫЭЦРёЯР§өДЙъіЙҫ«И·¶ЁЦЖ»ҜДЪИЭөДКэҫЭІЦҝвЎЈЖдУҰУГіЎәПҫЯУРИ«ЗтРФ,әЈБҝ¶ҜМ¬ұд»ҜКэҫЭ,ёЯІў·ўІйСҜөИМШРФЎЈ
?
== әЛРДЛјПл ==
?
FacebookөДЙзҪ»НшВз·юОсөДКэҫЭДЈРНКЗ»щУЪ¶ФПуәН¶ФПуЦ®јдөД№ШБӘАҙ№№ҪЁөДЎЈКэҫЭЦчТӘұнПЦОӘ¶ФПуәН№ШБӘБҪАа,¶ФПуИзУГ»§,НјЖ¬,МыЧУ,ЖАВЫ,Т»ҙОcheckinөИөИ,№ШБӘҫНКЗёчЦЦ¶ФПуЦ®јдөД№ШПө,ЕуУС°ў,ЛӯөДМыЧУ°ў,Хл¶ФДДёцМыЧУөДЖАВЫАІөИөИЎЈЛщУР¶ФПуәН№ШБӘ¶јУРТ»ёцIDЧЦ¶ОЧчОӘОЁТ»ұкК¶ЎЈ
?
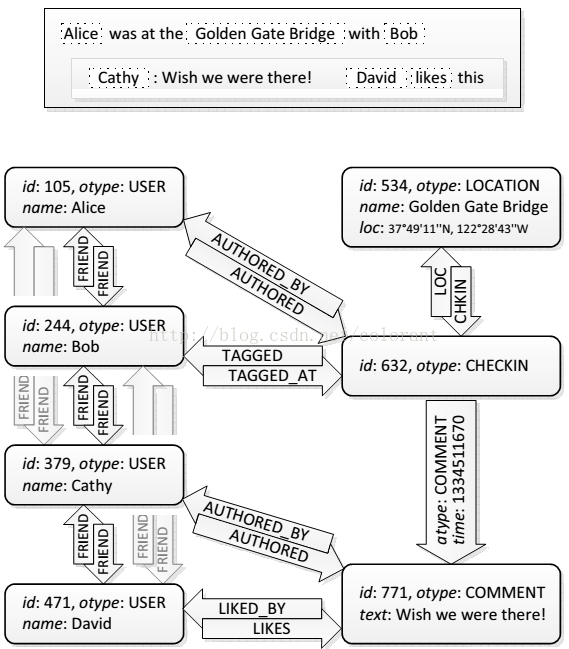
?
ФЪХвЦЦУҰУГДЈРНПВ,ёчЦЦАлЙўөДКэҫЭЦ®јд¶јУРЦЪ¶аөД№ШБӘ№ШПө,ДСТФјтөҘөД·ЦАаҙҰАн,ЧоЦХөДУҰУГХ№ПЦТІЗ§ұдНт»Ҝ,ТтҙЛЦЪ¶аөД№ӨЧчІ»КЗФЪёьРВКэҫЭКұНкіЙ,¶шЦ»ДЬФЪІйСҜКұФЩҪшРРҙҰАн,ЛщТФКЗТ»ёцread dominateөД№эіМЎЈ
?
FacebookФӯУРөДҝтјЬҝҝУҰУГіМРт·ЦұрУлMySQLәНMemcached·юОсЖчҪ»»ҘАҙ№ЬАнәН»әҙжКэҫЭЎЈОКМвФЪУЪmemcachedІ»ДЬУРР§өДАыУГЙПХвЦЦ¶ФПу№ШБӘДЈРНөДРЕПў,ёчёцclientТІІ»ДЬУРР§өШИ«ҫЦ№ж»®№ЬАнcache,ФЪКэҫЭёьРВәуөДТ»ЦВРФ·ҪГжТІҙжФЪҪПёЯөДҙъјЫЎЈ
?
TAOТАҫЙТФMySQLОӘөЧІгКэҫЭҝвАҙҙжҙўКэҫЭ,КэҫЭТФID»®·ЦөҪЦЪ¶аөДshardЙП,ГҝёцMySQL·юОсЖчёәФр№ЬАнИфёЙёцShard,TAOөД»әҙжІгЦР,¶аМЁCache·юОсЖчЧйіЙТ»ёцTier,Т»ёцTier°ьә¬БЛЦ§іЦЛщУРTAOІЩЧчЗлЗуЛщРиөДРЕПўЎЈҝН»§¶ЛіМРтНЁ№эАаЛЖөДShardЛг·ЁУлМШ¶ЁөДCache·юОсЖчНЁС¶,УЙCache·юОсЖчНкіЙКэҫЭөД¶БРҙЗлЗуТФј°УлMySQLКэҫЭҝвөДҪ»»ҘЎЈ
?
== КөПЦ ==
?
ОӘБЛМбёЯІў·ўҙҰАнөДДЬБҰ,TAOөД»әҙжІгКөјКУЙБҪј¶өДTierЧйіЙ(Т»ёцLeaderәН¶аёцFollower),ҝН»§¶ЛУлҫНҪьөДFollower TierНЁС¶,¶шFollowerTierҪ«РҙЗлЗуЧӘ·ўНЁ№эLeader TierНкіЙ,¶БЗлЗуЦчТӘУЙFollower TierНкіЙ,іэ·ЗУРКэҫЭMissІ»ФЪ»әҙжЦРөД,ІЕПтLeader Tier·ўЛНЗлЗуЎЈ
?
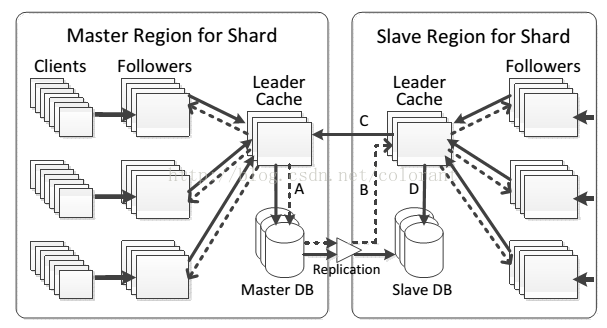
?
ҝЙТФҝҙөҪFollowersІўІ»УлКэҫЭҝвҪ»»ҘЎЈ ОӘБЛККУҰИ«Зт»ҜөДІјҫЦ,јхЙЩИ«ҫЦНшВзНЁС¶СУіЩҙшАҙөДУ°Пм,TAOөДКэҫЭҝвәН»әҙжІгКөјКЙПИзЙПНјЛщКҫ,УЦҪшТ»ІҪ»®·ЦОӘMaster/Slave Region,ГҝёцRegion¶јУРЙПКцөДБҪј«Tier,ЛщУРөДРҙІЩЧчұШРлНЁ№эMaster RegionөДLeaderАҙНкіЙ,ФЩТмІҪН¬ІҪёшSlave RegionөДКэҫЭҝв,¶БІЩЧчФтУЙSlave RegionұҫөШНкіЙ,Из№ыұҫөШКэҫЭҝвГ»УРј°Кұұ»ёьРВ,ФтУРҝЙДЬ¶БИЎөДКЗ№эКұөДКэҫЭЎЈ
?
ТФЙПRegionөД»®·ЦКЗФц¶ФГҝТ»ёцShard,І»Н¬өДShardҝЙДЬУЙІ»Н¬өДMasterёәФр,УЙУЪ№ШБӘөДёьРВІЩЧчҝЙДЬЙжј°¶аёцShard,ОӘБЛјхЙЩНЁС¶ҝӘПъ,ЛщУРөДMaster»№КЗЗгПтУЪ·ЦЕдФЪН¬Т»ёцRegionДЪІҝЎЈ
?
ЦөөГЧўТвөДКЗ,ГҝёцRegion¶јРиТӘУРНкХыөДКэҫЭ,¶шТтОӘКэҫЭБҝҫЮҙу,ЛщТФөҘёцRegionҝЙДЬКЗУЙ¶аёцөШУтЙПҪУҪьөДКэҫЭЦРРДЧйіЙөДЎЈ
?
== Па№ШСРҫҝ,ПоДҝөИ ==
?
УЙУЪ»әҙжІгөДҙжФЪ,УЙRMDBSКэҫЭҝв(ХвАпөДMySQL)ұЈЦӨөДACID·ҪГжөДЦёұк,ФЪТ»¶ЁіМ¶ИЙПұ»јхИхБЛЎЈөұИ»ёщҫЭCAPАнВЫ,ХвТІКЗҙу№жДЈ·ЦІјКҪКэҫЭҝвІ»ҝЙұЬГвөДОКМв,НЁіЈ¶ј»бҪөөНТ»ЦВРФТӘЗуЎЈФЪTAOЦР,ОюЙьCІ»НкИ«КЗіцУЪВъЧгAPөДТӘЗу,әЬҙуТ»Іҝ·ЦөДФӯТтКЗОӘБЛҪвҫцlatencyөДОКМв,АаЛЖУЪХвАпЛөөД:http://dbmsmusings.blogspot.com/2010/04/problems-with-cap-and-yahoos-little.html
?
ЖдЛьИ«Зт№жДЈөДКэҫЭҝв,ИзGoogleөДMegastore,SpannerөИПөНі,НЁ№эPaxos,GPS,ФӯЧУКұЦУөИёчЦЦ»ъЦЖұЈЦӨКэҫЭөД¶БРҙТ»ЦВРФЎЈ¶шҙУЙПГжҝЙТФҝҙөҪTAOФЪКэҫЭТ»ЦВРФ·ҪГж,ІЙУГөДКЗҪҘҪшТ»ЦВРФ,ҙжФЪ¶БИЎ№эКұКэҫЭөИёчЦЦОКМв,ХыМеөД¶аІгҝтјЬТІУРЖҙҙХөДёРҫх,ө«ЧЬМеЙПАҙЛө,Т»ЗР»№КЗОӘБЛЧоҙу»ҜәЈБҝІў·ўЗлЗуПВөДНМНВВКЛщЧцөДНЧРӯЎЈ
cs