����:������ Raymond ת����ע������
Email:colorant at 163.com
BLOG:http://blog.csdn.net/colorant/
Dryad��������������2007��ͷ�����,Tez�ĺ���˼����Դ��Dryad,����������Dryad�Ŀ�Դʵ�ְɡ�������ÿ���������Ȥ����Ŀ�ǻ���Tezʵ�ֵ�,����˳������Դ,ѧϰ��һ��Dryad�����ۻ���
?
== Ŀ������ ==
?
Dryad�����Ŀ��͵�ʱ�Ⱥ���ֵĸ��ֲַ�ʽ������һ��,��Ϊ�˼��ģ�ֲ�ʽ��̵��Ѷ�,�ṩ���û�һ����ͨ�õķֲ�ʽ�����ܡ��������ֲ�ʽ�����ܽ������������,����������û�����Ҫ���Ƿֲ�ʽ�������漰���ڶ��������,������Դ����,��������,ϵͳ�ݴ��ȵ�,��ֻ��Ҫ��ע������������
?
== ����˼�� ==
?
���չٷ�����,Dryad��һ��ͨ�õĴֿ����ȵķֲ�ʽ�������Դ��������,������˵�Ĵֿ�����,��Ȼָ��������������ݽ��д���������Ӧ��ģʽ,��Ȼ�����������ȿɴ��С��
?
Dryad�ĺ�������ģ����Vertex����ڵ��Channel����ͨ�����������,�û�ͨ��ʵ���Զ����Vertex�ڵ���ִ�ж��Ƶ�������,���ڵ�֮��ͨ��������ʽ������ͨ����������,�û�������������ͨ����˳��ִ�е�,����ֲ�ʽ��ص�������Dryad�����ʵ�֡�
?
?
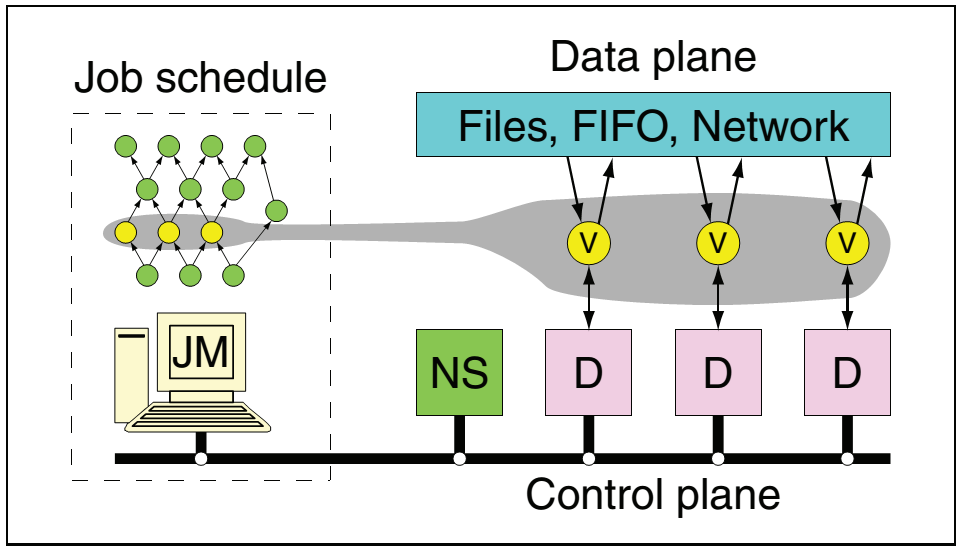
��ͼ��ʾ����Dryad��ϵͳ�ܹ���ͼ��Dryad����ҵ����ģ��JM��Ӧ�ó����ڲ�ά����һ������DAGͼģ�͵ļ���ڵ�������ϵͼ,��ҵ����ģ��ͨ������������NS����ȡ���õķ������б�,����ͨ������Щ�����������е��ػ�����Daemon�����Ⱥ�ִ�м���ڵ�Vertex����������ڵ�֮��ͨ�������ļ�,�ܵ�,�������ʽ������ͨ���������ݡ�
?
�����Ͽ�,������ĸ�����˵,Dryad��MapReduceʮ������,����ͬ�ľ���MapReduce���û�����ΪMap��Reduce������,��Dryad���ֻ�в��ֽε�Vertexһ�����������һ��ǡǡ��������MapReduce����Ĺؼ���
?
���û�ʹ�õĽǶ���˵,MapReduceǿ�ƶ�����Map��Reduce������,�Լ�����֮����������������ʽ���û�����ͨ����������ģ��������������������,�����ĺô���,�����û���̽ӿ�,���ͱ���Ѷ�,ͬʱ������ģ�͵Ļ�����MapReduce��ܿ����Զ���ɸ��ֵ����Ż����ݴ��������������ǹ̶��ı��ģ����ȻҲ����һ���̶�������������ͨ����,����MRģ�������еļ���ڵ�ֻ�ܽ���ͳһ��ʽ��һ����������,Ҳֻ�����һ������,�����Ƿ���Ҫ,�û�����������ƥ���Map��Reduce����ɵȵȡ�
?
Ϊ�˾߱������ͨ����,Dryad��ģ���ϲ����������,�ӿ�ܵĽǶ���Ҳ�������������ڵ�֮������ݽ�����ʽ,�����ɾ������Ҫ�ͨѶ�ļ���ڵ��Լ��������ݵĸ�ʽ�������⡣��������һ���̶��ϵ�Ȼ�������û��ı���Ѷ�,����Ϳ�����Ҫ��Ծ������ڵ��ʵ��,��д����Channel����ͨ����ʵ��(��Ȼ����ͨ��ʵ��һЩͨ�õ�����ͨ�����û�ƥ��ʹ���������������)���Ǵ����ĺô�Ҳ���Զ�����,���Ǹ������ı��ģ�͡�
?
�û��Զ����������ͼ
?
Dryad�ĺ�������֮һ,�������û��Լ�����DAG��������ͼ,����������ǻ���������ԭ����߱���ʵ�ֵĿ����Ժͼ�ֵ��MapReduceͨ�����ص�����,���û���̡���֮�෴,Dryad����ͨ���ʵ����ӵı�̸��Ӷ�,��¶���û��������ĵ��ȱ�̽ӿ�,���û��ܹ�����Ч���Ż�������,�Ӷ��ﵽ�����������ܵ�Ŀ�ġ�
?
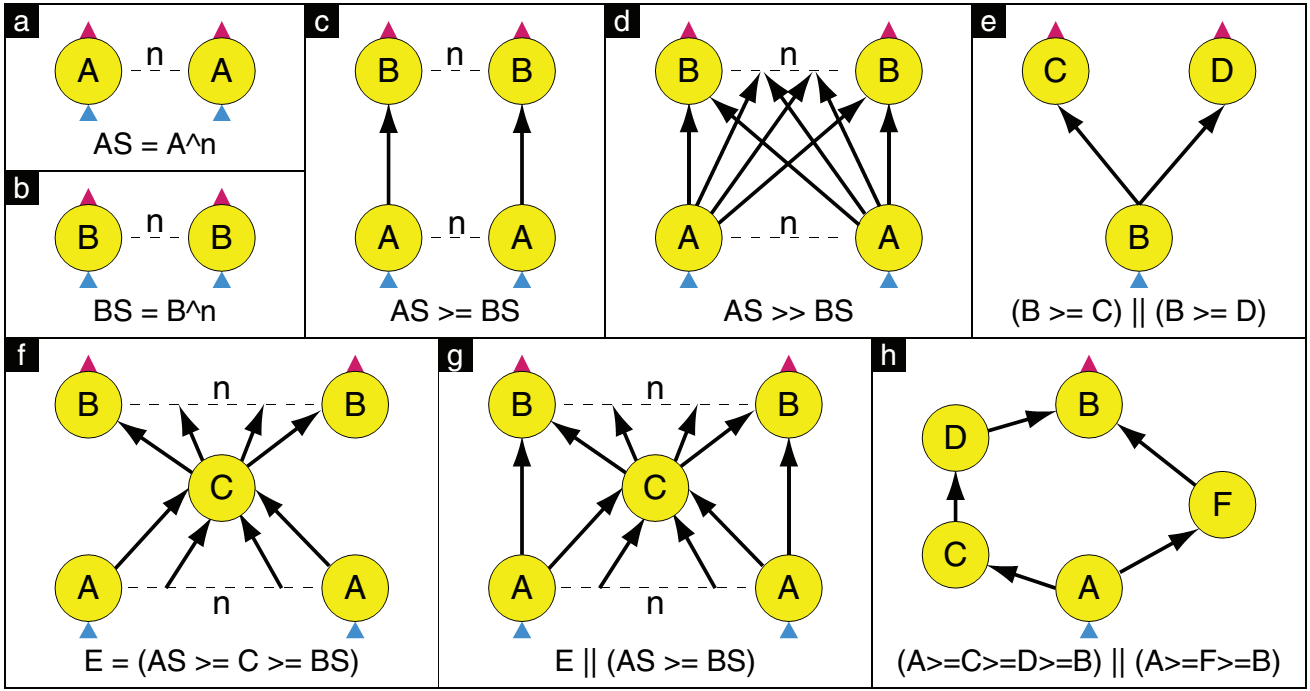
Dryad���п�ʵ����һ����ͼ����������(graph description language)����������������ͼ,�����IJ���ԭ�����������ͼ��ʾ:
?
?
����һ�������DAG������:
?
GraphBuilder XSet =moduleX^N;
GraphBuilder DSet =moduleD^N;
GraphBuilder MSet =moduleM^(N*4);
GraphBuilder SSet =moduleS^(N*4);
GraphBuilder YSet =moduleY^N;
GraphBuilder HSet =moduleH^1;
GraphBuilder XInputs= (ugriz1 >= XSet) || (neighbor >= XSet);
GraphBuilder YInputs= ugriz2 >= YSet;
GraphBuilder XToY =XSet >= DSet >> MSet >= SSet;
for (i = 0; i <N*4; ++i)
{ XToY = XToY || (SSet.GetVertex(i) >=YSet.GetVertex(i/4));}
GraphBuilder YToH =YSet >= HSet;
GraphBuilderHOutputs = HSet >= output;
GraphBuilder final =XInputs || YInputs || XToY || YToH || HOutputs;
?
�������빹����DAGͼ������ʾ
?

?
��̬�Ż�������
?
Dryad����һ���ص��������û���̬�ĸı�DAG��������ͼ,����ͨ���ڼ���ڵ��з���ʵ�������������ݵ������Ϣ����ҵ����ģ����ʵ�ֵġ�֮������Ҫ��ô��,����Ϊ�ںܶ������,���ŵĵ������˽ṹ����ȡ����ʵ�ʵ���������,�м���������ߵ�ʱ�����л���,������ڱ�̵�ʱ����߳���������ʱ����ǰ�������Žṹ��
?
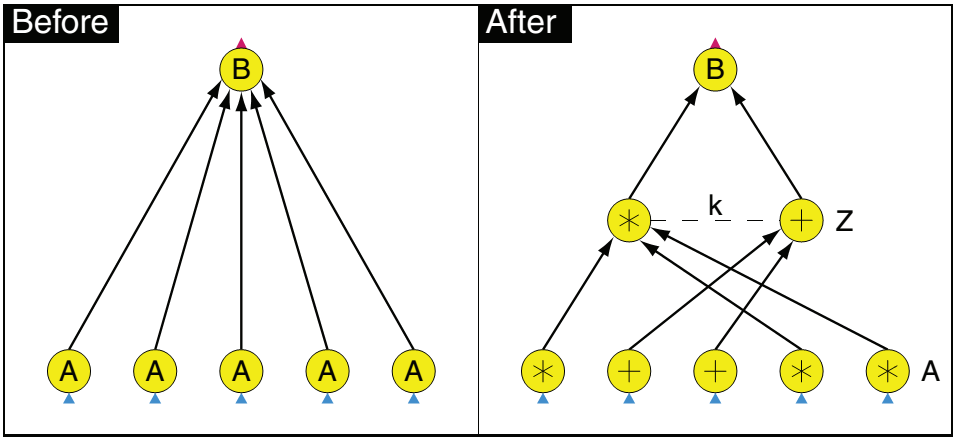
?
����ͼʾ��һ��Aggregation���͵IJ���,��ʵ��ִ�е�ʱ��,����ͨ�����ݵı�������Ϣ,���Զ�̬����ԭ�е�����ͼ��(A->B)����һ�����ļ���ڵ�(A->Z->B),���罫ͬһ�������ϵ����ݻ��ܵ�ͬһ���м�ڵ�����һ��Aggregation,Ȼ�����ύ��ԭ����ͼ�еĺ����ڵ㴦��������,Ҳ����ͨ����ȡʵ�ʵ����ݹ�ģ��Ϣ,��̬������������ڵ�IJ��������������ʵ����������ȵȡ�
?
��Ȼ,��Щ��̬�����Ĵ�����������Ҫ�û������Լ���ҵ������ʵ��,�����һ���̶��϶��û���˵Ҳ����Ҫ���������Ŭ����
?
== ʵ�� ==
?
Dryad�ľ���ʵ���Ƿ��Ż�����,ʵ���������,һ�������������ǿ�Դ��Ŀ,��һ�����Ҹ���Ҳ���˽���������������ϵ,����Ҳ����̸����,�����пտ��Խ��Tez�����Դ�汾��ʵ�����������һ�¡�
?
== ˼�� ==
?
Dryad�ı��ģ�������MapReduce��˵��Ȼ�������,����ͬʱҲ�����˸��ߵı���ż�������,��Ϊ�������̺ͽ������̸��������,��Ż��кܶ���MapReduce�����õĸ��ֿ�ܼ����Ż���������ͨ�õĴ�����������Dryad�Ŀ����Ӧ��,��������������Ʊ��ܵ�Ӱ��,������û����벻���Լ������Щ�Ż������Ļ�,Ӧ��Ҳ���Ӧ�ó����ʵ�����ܲ���һ����Ӱ�졣��ñ�Hadoop2����Yarn�����֧�ָ���ͨ�õı��ģ��,����Ҫ��MapReduceһ��,��Yarn�Ļ����Ϲ����Լ���ģ����صĵ���ģ��,��Ȼ��Ҫ�����ܴ��Ŭ��,��Ȼ���ܰ�Dryad��ģ����Yarn����Դ����ģ��ֱ�ӶԱ�,�Ͼ�Dryad�ı��ģ�ͻ�����MapReduceһ��,���ڸ��߲�εĸ��
?
�������Է���,Dryad��DAGͼ�������Թ�Ȼ���,�������ೣ��case�ij�����Ҳ�Ե�����,���粢���ȵ����õ�����,���������Ӧ�ÿ����Զ�����,���ֳ��ô������̵�DAG����ͼҲ��Թ̶�,���Ҳ����ҪһЩ�߲��װ�����,���繹����Dryad�ϵ�Nebula,�û�ʹ�ýű����Ե���ʽ���,Dryad���ڶ�ʹ��ϸ�ںͶ�̬�Ż���������װ��Nebula�ķ���������(����Filter/Aggregate��),���˼���Spark��RDD�ķ�����װ����DAGScheduler��ҵ������ز�����˼��ܽӽ�,����¶���û��Ľӿ���Ҫ��ʲô,������Ҫ��ô����
?
��������DryadLINQ��LINQ��Dryad�ϵ�ʵ��,���ﱩ¶���û���Ҳ�Ǹ��߲��Ӧ�ýӿ�,ǰ���ᵽ�ĸ�����Ҫ���������ͬ������DryadLINQ�Ŀ����������
?
��Paper����������,��ʱ��Dryad�ڲ���,����,HA�ȵȴ��ģ��Ⱥ��Ҫ���ǵ����ⷽ��Ĵ�����ʽ���ܼ�ª,��Ȼ������ô����ķ�չ,Ӧ������Щ������и��ƺͷ�չ,Ŀǰ�ľ�������Ͳ��ö�֪��
?
Dryad�Ŀ�Դʵ��Tez�����ٵ�������Ҳ������,Tez�ṩ�˸���ͨ�õ�channel��ʵ��(�����MapReduce��Ӧ��ģʽ��ͨ��)�����û�����Ѷ�,��ʹ��Tez��Ȼ��ʹ��MapReduceҪ����,Tez���ȶ��Ժ������Ż�������ȻҲ���кܳ���·Ҫ�ߡ���Stinger�Ȼ���Tez���ϲ�����Ȼ��ϣ���ڽ���Tez�ڵ��������ṩ���Ż��ռ���������ܵ�ͬʱ,ͨ�����Ӹ��ı�̽ӿ�����֤�����ԡ�
cs