作者:刘旭晖 Raymond 转载请注明出处
Email:colorant at 163.com
BLOG:http://blog.csdn.net/colorant/
== 是什么 ==
?
要了解Samza,最好先了解Kafka :?http://blog.csdn.net/colorant/article/details/12081909
?
samza是一个分布式的流式数据处理框架(streaming processing),它是基于Kafka消息队列来实现类实时的流式数据处理的。(准确的说,samza是通过模块化的形式来使用kafka的,因此可以构架在其他消息队列框架上,但出发点和默认实现是基于kafka)
?
== 如何实现 ==
?
作为一个分布式的消息队列系统,kafka已经实现了流式处理框架底层的许多核心基础架构,把消息串联流动起来就是Streaming了。但是要构建一个可用的流式数据处理框架,还是有许多事情要做。例如生产者和消费者进程的管理,作业调度和容错处理,辅助工具和监控管理手段,更友好方便的用户接口等等,本质上说,Samza是在消息队列系统上的更高层的抽象,是一种应用流式处理框架在消息队列系统上的一种应用模式的实现。
?
?
核心思想
?
Samza的一个job的基本处理流程是一个用户任务从一个或多个输入流中读取数据,再输出到一个或多个输出流中,具体映射到kafka上就是从一个或多个topic读入数据,再写出到另一个或多个topic中去。多个job串联起来就完成了流式的数据处理流程。
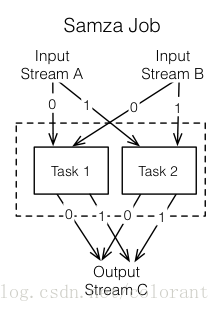
这种模式其实有点像MapReduce的过程,stream输入部分由kafka的partition决定了分区和task数目,类似于一个Map过程,输出时由用户task指定topic和分区(或者框架自动由Key决定分区),这相当于一次shuffle的过程,下一个job读取新的stream时,可以认为是一个reduce,也可以认为是下一个map过程的开始。
?
不同之处在于job之间的串联无需等待上一个job的结束,类实时的消息分发机制决定了整个串联的job是连续不间断的,亦即流式的。
?
调度
?
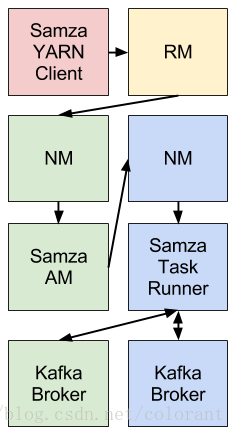
Samza使用Yarn进行资源分配和任务调度(调度模块同样是可以替换的)
?
?
Samza AM负责job调度,Task runner 负责用户task的运行,依靠kafka和YARN的帮助,samza得以实现其 分布式 / 容错性 / 可扩展 / 持久性 等方面的特性。
?
kafka相关
?
由于samza默认实现是基于kafka的,由此kafka的系统设计也给samza带来了一些其它流式处理系统框架所没有或难以实现的特性。比如kafka的message的Pull模式和持久化的设计带来的Buffer缓冲空间,使得每个samza的job可以无需要求实时完成数据处理,加上task的串联是通过对相关消息的订阅来实现的,也就是说串联的task之间可以独立的运行/停止,更不容易发生阻塞在一个处理节点上等问题,相互进度也无需保持严格一致,应用模式上更加灵活,比如可以串联批量处理任务等。
?
状态管理
?
流式处理框架通常需要处理的一个问题就是状态管理,由于数据是连续流动的,本身并不提供任何历史状态信息,在需要依靠历史数据完成相关处理的应用场合(比如窗口类的数据应用,Join类操作等等),就需要一个机制来获取历史数据,samza提供了一个内建per task的Key-valuebased的数据库(基于LevelDB,运行在JVM外部,延续kafka减少JVM内部内存使用的原则)来存储历史数据,同时也可以通过向特定topic写message的方式来log本地数据。
?
不采用外部数据库来存储的原因,一是考虑外部数据库的吞吐率,二是为了减少并发操作带来的复杂性,再有就是在任务失败重起时很难回滚数据。
?
== 小结 ==
?
总体来说,Samza基本上就是一个使用Yarn和kafka的流式数据处理应用程序框架,自身额外提供了本地数据库保存状态信息,代码量并不大(数千行代码),本质上是为了更加方便的使用kafka来处理数据。
?
== Links ==
?
http://samza.incubator.apache.org/
https://github.com/apache/incubator-samza
https://github.com/linkedin/hello-samza
cs