作者:刘旭晖 Raymond 转载请注明出处
Email:colorant at 163.com
BLOG:http://blog.csdn.net/colorant/
== 目标问题 ==
?
MillWheel的设计目标是提供一个大规模分布式的低延迟流式数据处理框架,基本的要求包括:
?
- 数据的及时可用性 - 也就是低延迟啦,尽可能避免不必要的中间缓冲层造成的数据延迟
- 全局可用的数据持久性API - 主要用来处理各种需要数据Buffer的场合,如Window, join类操作
- 能处理乱序到达的数据 - 即数据非严格按照来源时间戳排序到达
- 保证数据满足严格一次投递(exactly-once delivery)要求 - 也就是说对应用程序而言,数据不会遗漏,也不会重复接收,减轻应用程序的实现负担
?
== 核心思想 ==
?
数据流程
?
和其它的Streaming Processing系统 (e.g. storm) 类似 ,MillWheel的数据处理流程框架基本上就是一个由用户自定义的处理单元(MillWheel里叫computation)按照一定的拓扑结构连接在一起的一个有向图
?
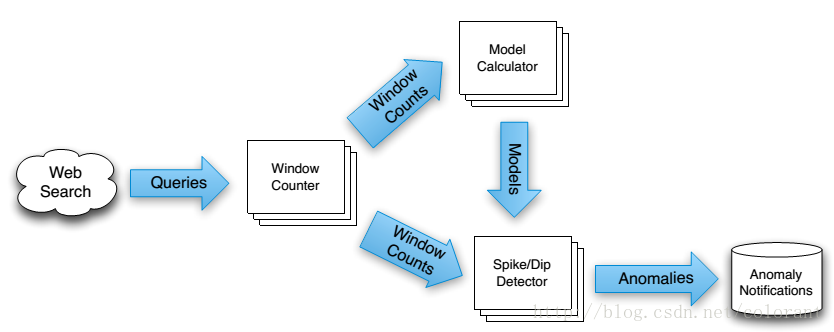
?
computation之间的数据流以(key,value, timestamp) 这样的三元组为单位组成,每个computation都可以按Key的范围动态的分布在多个的节点上运行。
?
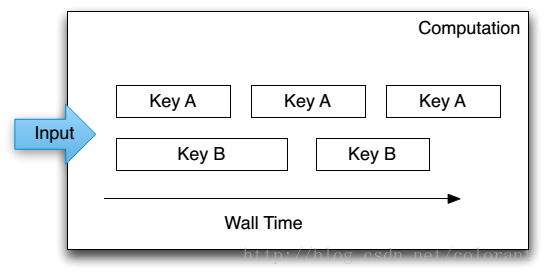
来自同一个KEY的数据按照时间戳顺序由一个处理节点单独处理,来自不同key的数据则可以并发在不同的节点上处理,到这里为止,和其它的流式处理系统基本大同小异
?
乱序数据的处理
?
MillWheel中区别于其它相似系统的根本,大概是它的Low WaterMarks(低水位?)这样一个概念,其核心思想是针对分布式环境下,各个数据来源由于网络延迟或其它种种原因,同类数据不能保证严格按照时间戳顺序到达处理节点,因此有必要知道什么时候特定时间范围的数据在处理节点上已经完全获取完毕。以保证各种依赖于时间顺序或数据完整性才能正常工作的应用的运行。
?
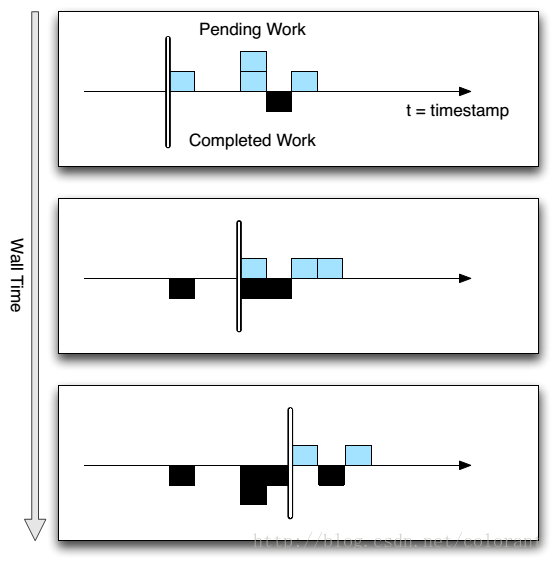
?
Low WaterMarks基于数据处理单元之间的数据流来定义,它标识了当前数据流中最老的未被处理的数据包的时间戳,也就是说它试图保证在当前数据流中,不会再产生时间戳上更老的数据包。后续的节点基于low watermarks信息就可以判断当前已接收数据是否完备。
?
时间戳的最早来源来自数据输入模块 (MillWheel中叫Injector),injector自身因各种数据来源的不同,有各自的时间戳生成方式,因此很可能不能绝对保证不违反Low WaterMarks的要求,这时候系统框架可以忽略后续违反低水位要求的数据包,也可以由应用程序自行处理这些例外数据包。
?
数据持久化
?
对于一个流式处理框架来说,常常要遇到的问题就是如何获取历史数据用于各种window类运算或其它依赖于历史状态的运算,很容易想到的解决方案就是将历史数据持久化后在后续运算中在获取出来,此外数据持久化也是防止节点崩溃以及容错处理的一种有效手段
?
在MillWheel中,当持久化作为Exactly-oncedelivery的实现手段之一使用时(用来记录已经处理过的数据,以及崩溃恢复历史状态等)数据的持久化可以由框架在数据流输出时(upstream backup)全局自动完成。如果应用程序本身对Exactly-once delivery没有要求,也可以按需仅对部分数据流进行持久化。这一点,相对Spark?streamming来说,使用起来更加灵活一些
?
MillWheel使用Big Table/Spanner等系统作为持久化的手段,主要针对一次写,多次读这样的应用模式。
?
数据处理模式
?
MillWheel的数据处理单元主要对用户提供了两种数据处理的应用模式:
?
一是按数据包三元组触发用户处理函数,就是来一个包处理一次了。比较接近Storm的概念
?
二是按时间窗口或绝对时间(Wall time)触发用户处理函数,这种模式类似于Spark Streaming这样的小批量处理方式
?
这两种模式也可以在一个处理单元内部混合使用,简单来说比如按数据包触发计数,然后按时间窗口触发,在特定时间间隔向下游发送计数包之类。从应用模式上来说,相对比较灵活
?
?
== 小结 ==
?
总体而言,MillWheel的总体思路类似于其它开源流式处理系统,但是强化了对数据严格一次投递的要求以及对乱序数据的有效处理,同时在数据持久性方面提供了较大的灵活性。这些方面的要求和实现,应该说与Google在以往的各种框架中一贯表现出来的学术严谨性保持了一致。
cs