今天室友说想去看电影,听说少年的你口碑还不错,结果刚准备买票发现场场爆满,这部电影真的有这么好看吗?或者更多是因为粉丝效应呢。于是决定爬取短评看看大家怎么评价
开始写爬虫
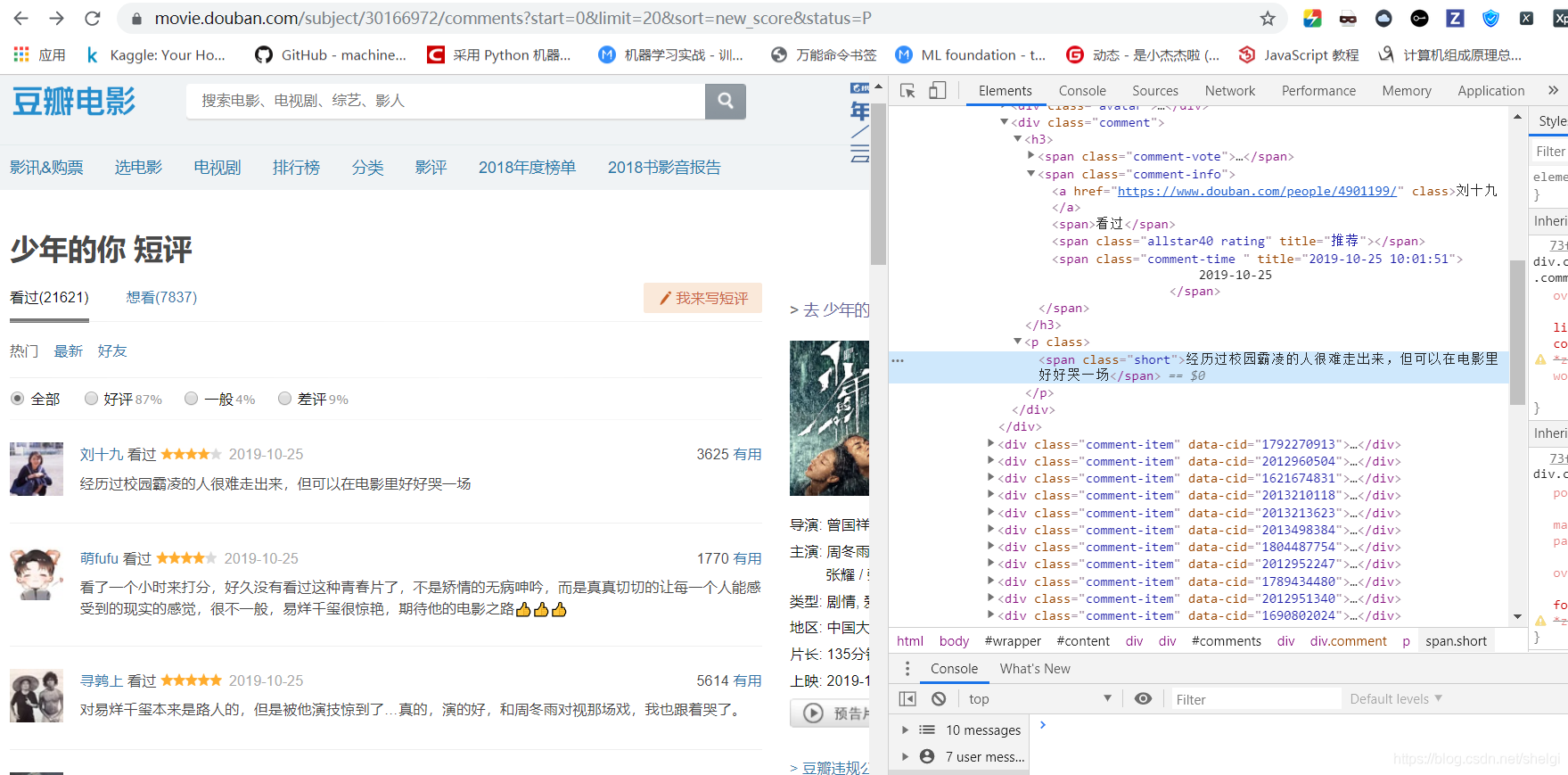
首先这是目标网页,然后为了简单决定用最快的提取办法,我一直觉得爬虫不一定需要多复杂,往往简单的几行代码就能完成我们的需求。
决定用requests爬取10页,然后正则提取,数据存到csv中。
直接上代码
import requests
import pandas as pd
import re
def get_content(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.120 Safari/537.36',
'Host': 'movie.douban.com',
'Referer': 'https: // movie.douban.com / subject / 30166972 /'
}
response=requests.get(url,headers=headers)
response.encoding = 'utf-8'
html=response.text
content=re.findall(r"<span class=\"short\">(.*?)</span>",html)
name=re.findall("<a href=\".*?/\" class=\"\">(.*?)</a>",html)
return content,name
def main():
name=[]
content=[]
for i in range(10):
url = 'https://movie.douban.com/subject/30166972/comments?start={}&limit=20&sort=new_score&status=P'.format(i*20)
i,j=get_content(url)
for x in range(len(i)):
content.append(i[x])
name.append(j[x])
data=pd.DataFrame({'评论人':name,'评论':content})
data.to_csv('./少年的你评论.csv',encoding='utf-8')
if __name__ == '__main__':
main()
最后的成果图
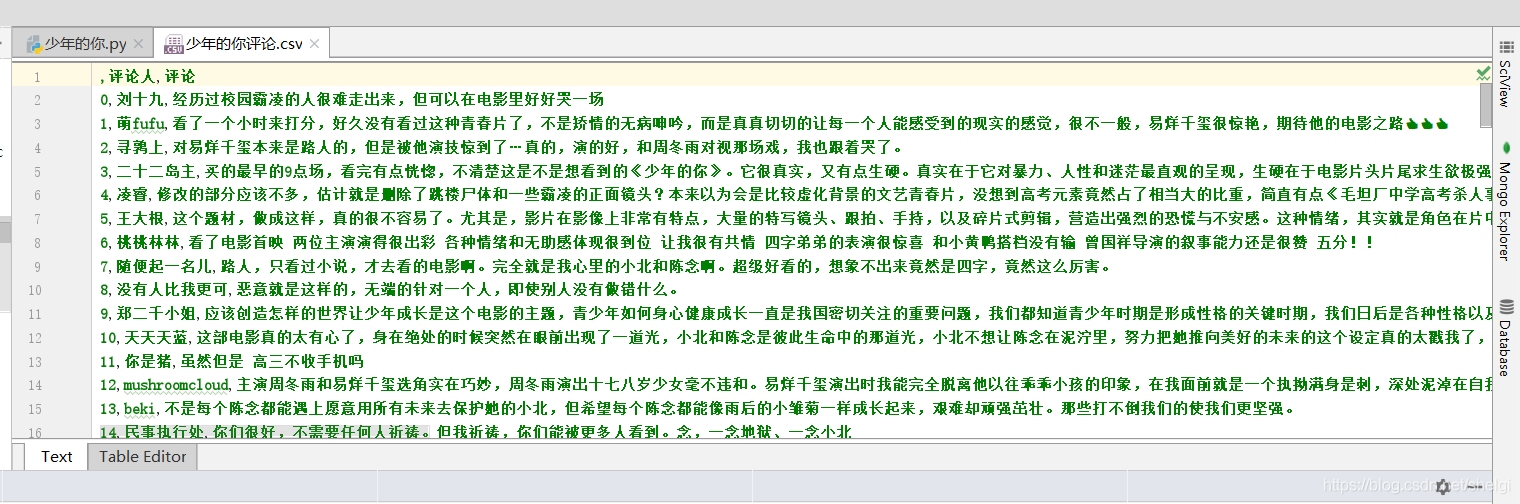
发现真的好评很多,而且每个评论写的都很用心,不像是那种虚假的,所以还是很推荐大家去观赏的。
cs