fashion_mnist=keras.datasets.fashion_mnist
(x_train_all,y_train_all),(x_test,y_test)=fashion_mnist.load_data()
print(x_train_all.shape)
print(y_train_all.shape)
print(x_test.shape)
print(y_test.shape)
x_train,x_valid=x_train_all[5000:],x_train_all[:5000]
y_train,y_valid=y_train_all[5000:],y_train_all[:5000]
print(x_train.shape)
print(y_train.shape)
print(x_valid.shape)
print(y_valid.shape)
from sklearn.preprocessing import StandardScaler
scaler=StandardScaler()
x_train_scaled=scaler.fit_transform(x_train.astype(np.float32).reshape(-1,1)).reshape(-1,28,28)
x_valid_scaled=scaler.fit_transform(x_valid.astype(np.float32).reshape(-1,1)).reshape(-1,28,28)
x_test_scaled=scaler.fit_transform(x_test.astype(np.float32).reshape(-1,1)).reshape(-1,28,28)
def show_imgs(n_rows,n_cols,x_data,y_data,class_names):
assert len(x_data)==len(y_data)
assert n_rows*n_cols<=len(x_data)
plt.figure(figsize=(n_cols*2,n_rows*1.6))
for row in range(n_rows):
for col in range(n_cols):
index=n_cols*row+col
plt.subplot(n_rows,n_cols,index+1)
plt.imshow(x_data[index],cmap="binary",interpolation="nearest")
plt.axis("off")
plt.title(class_names[y_data[index]])
plt.show()
class_names=['t-shirt', 'trouser', 'pullover', 'dress', 'coat', 'sandal', 'shirt', 'sneaker', 'bag', 'ankle boot']
show_imgs(5,5,x_train,y_train,class_names)

model=keras.models.Sequential()
model.add(keras.layers.Flatten(input_shape=[28,28]))
model.add(keras.layers.Dense(300,activation="relu"))
model.add(keras.layers.Dense(100,activation="relu"))
model.add(keras.layers.Dense(10,activation="softmax"))
model.compile(loss="sparse_categorical_crossentropy",optimizer="adam",metrics=["acc"])
model.summary()

这里网络信息中params中的数字怎么来的呢?
y=wx+b 然后根据矩阵相乘的规则从(None,784)到(None,300)中间的矩阵就是(784,300)然后偏置项b的大小是300,所以784300+300=235500,这是个小细节稍微提一下。
import datetime
current_time = datetime.datetime.now().strftime("%Y%m%d-%H%M%S")
logdir = os.path.join('logs', current_time)
output_model=os.path.join(logdir,"fashionmnist_model.h5")
callbacks=[
keras.callbacks.TensorBoard(log_dir=logdir),
keras.callbacks.ModelCheckpoint(output_model,save_best_only=True),
keras.callbacks.EarlyStopping(patience=5,min_delta=1e-3)
]
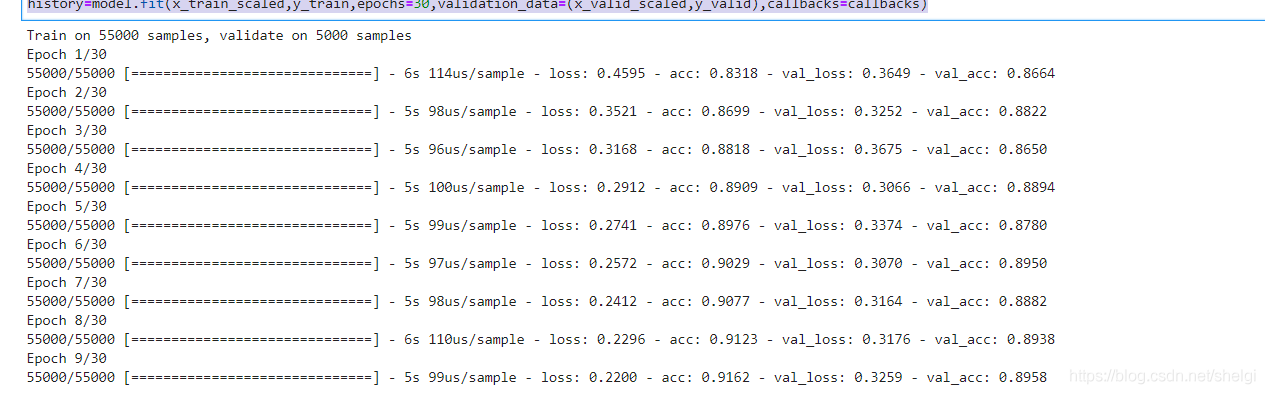
history=model.fit(x_train_scaled,y_train,epochs=30,validation_data=(x_valid_scaled,y_valid),callbacks=callbacks)
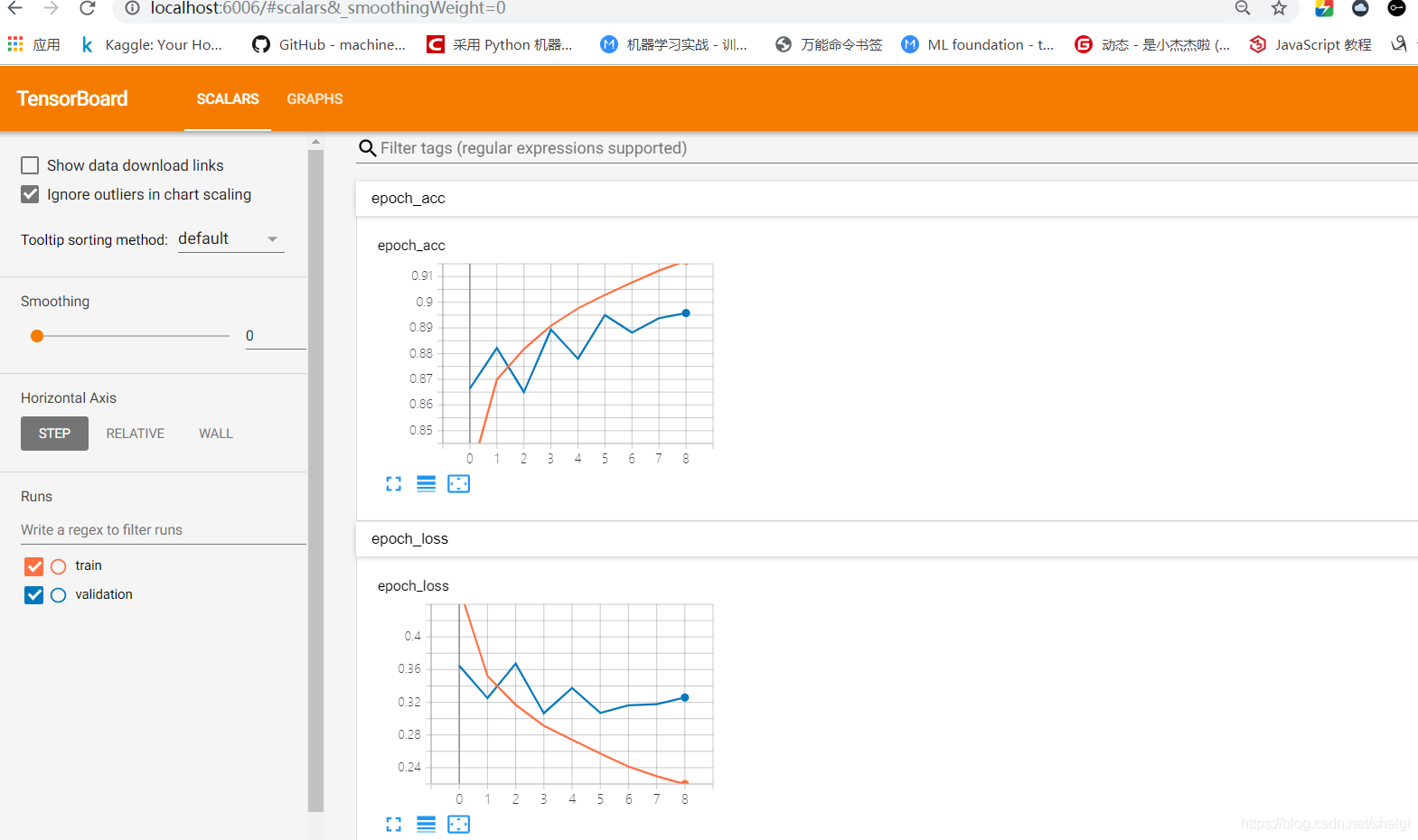
之前我用自己命名的文件夹使用TensorBoard和ModelCheckpoint运行会出错,搜了一下好像是windows上的bug,上面的这是一种解决方法,然后打开tensorboard看一下。

最好的模型也保存为h5文件,方便调用
def plot_learning_curves(history):
pd.DataFrame(history.history).plot(figsize=(8,5))
plt.grid()
plt.gca().set_ylim(0,1)
plt.show()
plot_learning_curves(history)
这是自己绘制每次训练的变化情况,和上面的差不多

loss,acc=model.evaluate(x_test_scaled,y_test,verbose=0)
print("在测试集上的损失为:",loss)
print("在测试集上的准确率为:",acc)
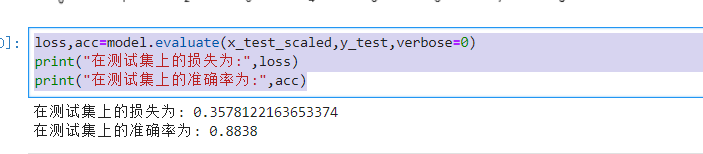
y_pred=model.predict(x_test_scaled)
predict = np.argmax(y_pred,axis=1)
show_imgs(3,5,x_test,predict,class_names)
show_imgs(3,5,x_test,y_test,class_names)
预测的结果
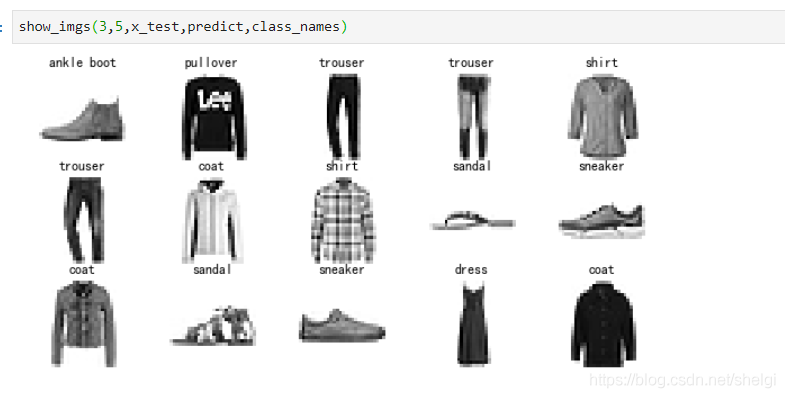
真实的结果
4.总结:
看了上面的例子,使用tf.keras搭建模型写法就是
model=keras.models.Sequential()
model.add(...)
model.add(...)
...
model.compile(...)
model.fit(...)
model=keras.models.Sequential([
...
...
...
])
inputs=...
hidden1=...(inputs)
....
class ...:
...
不过对于模型中的参数,比如损失函数的选择(“sparse_categorical_crossentropy"与"categorical_crossentropy"或者"binary_crossentropy”)什么时候需要用到哪种损失函数最适合、每一层网络中的激活函数的选择、优化器的选择……都需要了解其中的含义才能在适当的场合使用,这里我没有给出使用超参数搜索得到最优模型参数的例子,下次应该会写一个关于超参数搜索的例子。
cs