正好今天有个任务又是做爬虫的,那就接着昨天的劲头继续讲一下爬虫
任务:
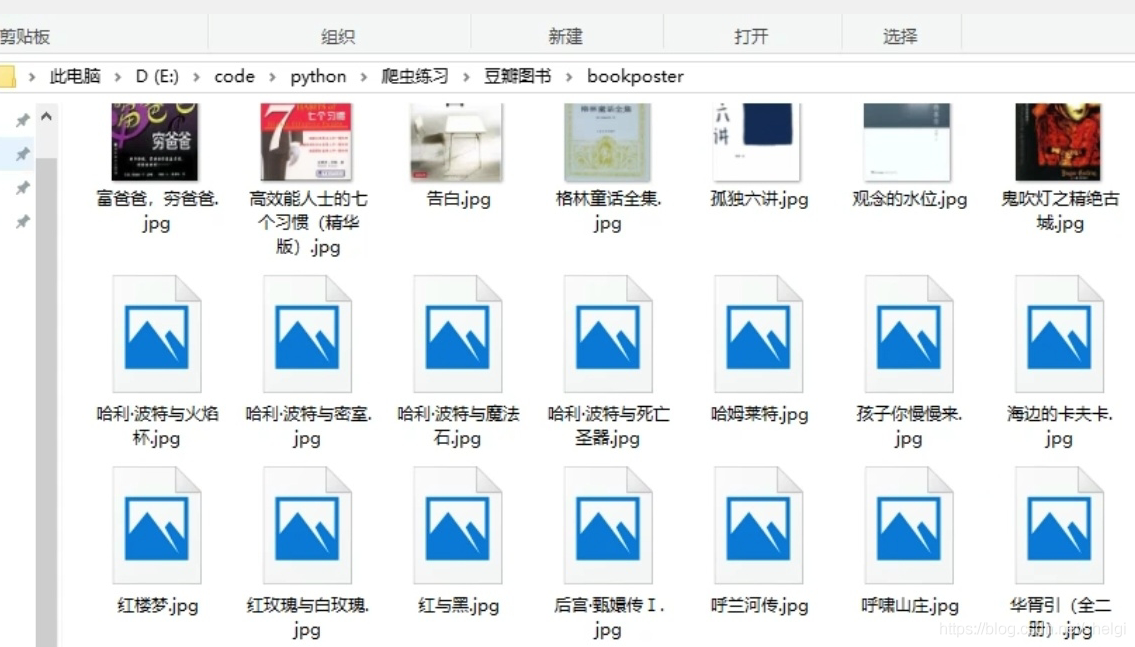
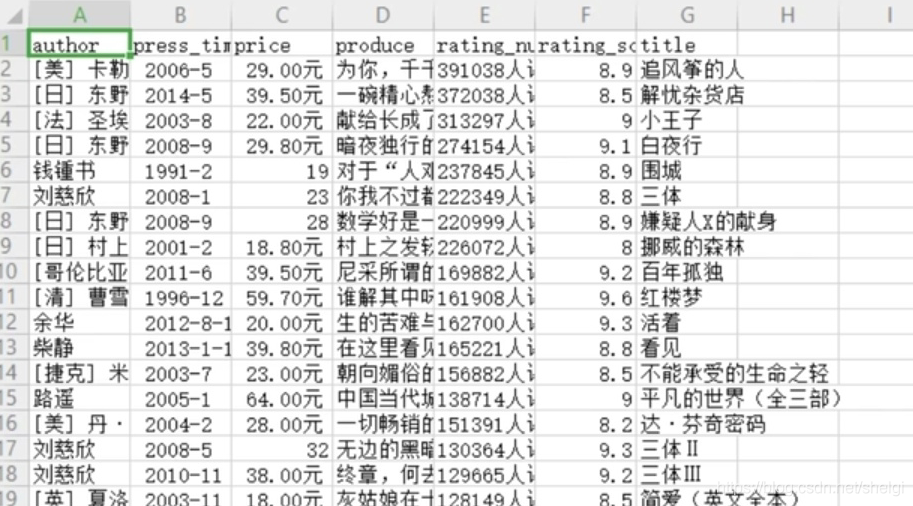
基本上任务就是爬取豆瓣TOP250图书的信息,写入文件并且把图片下载下来
爬虫分析

- 可以看到就在每页就可以得到我们所有需要的信息,不用再进去详情页爬取了。
- 然后就是翻页问题每一页的url:https://book.douban.com/top250?start=(页数-1)*25
- 写入文件就用csv就好
- 解析就用xpath,我觉得xpath和re用起来更熟一点,当然css选择器也很好用,所以掌握三四种解析方式就基本够用了。
代码部分:
import requests
from lxml import etree
import csv
import os
def get_informations(url):
res=requests.get(url,headers=headers)
selector=etree.HTML(res.text)
infos=selector.xpath('//tr[@class="item"]')
for info in infos:
image=info.xpath("td/a[@class='nbg']/img/@src")[0]
pic_list.append(image)
name=info.xpath('td/div/a/@title')[0]
names.append(name)
book_infos=info.xpath('td/p/text()')[0]
author=book_infos.split('/')[0]
publisher=book_infos.split('/')[-3]
date=book_infos.split('/')[-2]
price=book_infos.split('/')[-1]
num=info.xpath('td/div/span[3]/text()')[0]
rate=info.xpath('td/div/span[2]/text()')[0]
coments=info.xpath('td/p/span/text()')
coment=coments[0] if len(coments)!=0 else "空"
writer.writerow((author,date,price,coment,num,rate,name))
def get_image():
savePath = './豆瓣图书250图片'
if not os.path.exists(savePath):
os.makedirs(savePath)
for i in range(len(pic_list)):
html = requests.get(pic_list[i], headers=headers)
if html.status_code == 200:
with open(savePath + "/%s.jpg" % names[i], "wb") as f:
f.write(html.content)
elif html.status_code == 404:
continue
def main():
for url in urls:
get_informations(url)
get_image()
if __name__ == '__main__':
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.75 Safari/537.36'}
urls = ['https://book.douban.com/top250?start={}'.format(str(i)) for i in range(0, 226, 25)]
fp = open(r"./豆瓣图书.csv", 'wt', newline="", encoding="utf-8")
writer = csv.writer(fp)
writer.writerow(('author', 'press_time', 'price', 'produce', 'rating_num', 'rating_score', 'title'))
pic_list = []
names = []
main()
fp.close()
print("文件和图片都爬取完毕!")
运行结果
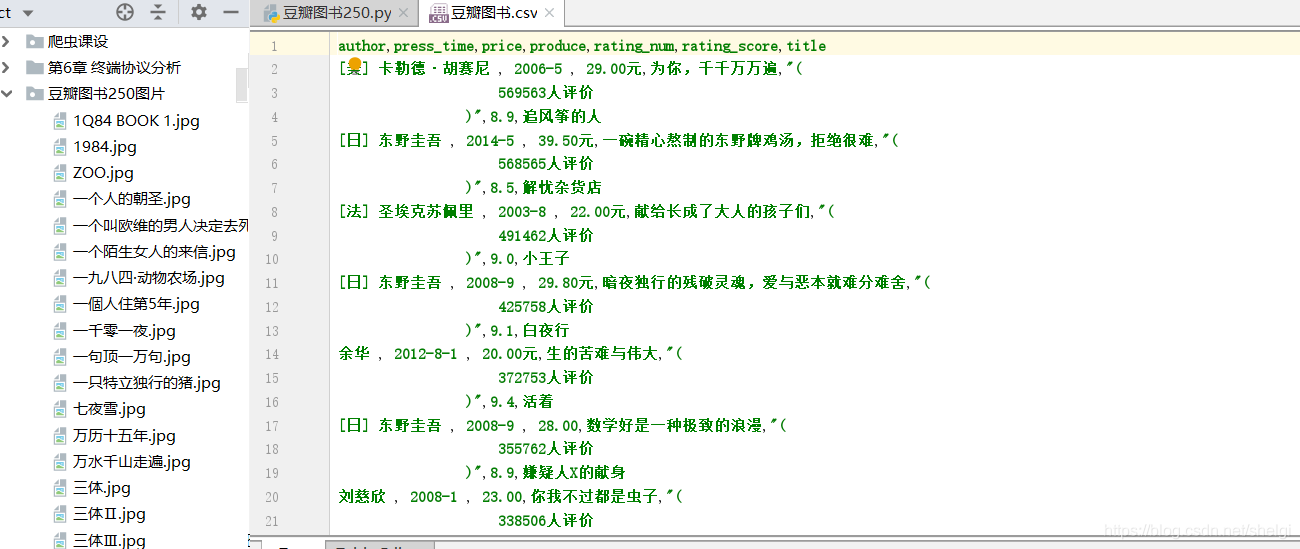
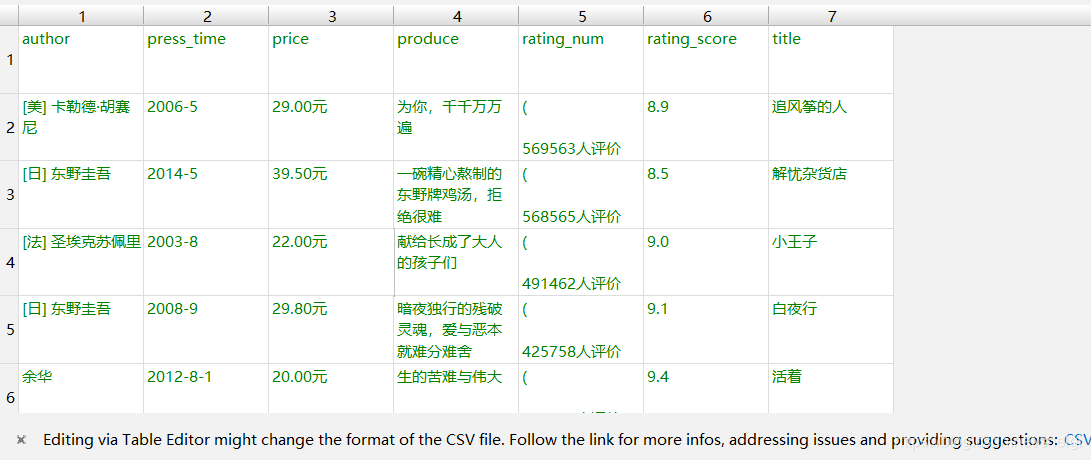

要求完成啦,写下来大概只要十几分钟,有兴趣的也可以自己试试。
cs