今天正好爬虫实验需要用scrapy框架简单爬一个网站的所有新闻信息


讲一下实现
本来很久之前就想写一个讲scrapy框架使用的博客,但是平时写的爬虫都不太需要用到框架,所以也就一直搁下来,正好今天讲一下。
首先两个最重要的命令:
1.创建scrapy爬虫项目:scrapy startproject +名字
2.创建spider:scrapy genspider +名字
然后就会建立一个下面这样的目录结构
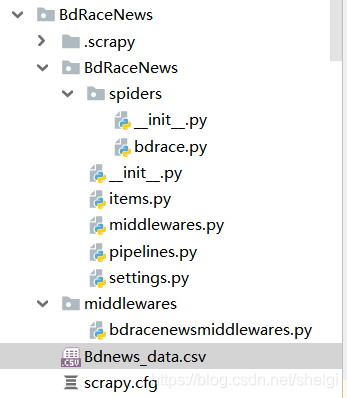
1.编写items
简单解释就是Scrapy.Field()这个域就可以定义我们想要返回的字典类型中的对应的值
import scrapy
class BdracenewsItem(scrapy.Item):
title=scrapy.Field()
text=scrapy.Field()
time=scrapy.Field()
2.编写pipelines
实现把得到的数据保存到csv和mysql
import pandas as pd
from sqlalchemy import create_engine
class BdracenewsPipeline(object):
def __init__(self):
self.engine=create_engine('mysql+pymysql://root:1234@127.0.0.1:3306/爬虫数据')
def process_item(self, item, spider):
data=pd.DataFrame(dict(item))
data.to_sql('Bdnews_data',self.engine,if_exists='append',index=False)
data.to_csv("./Bdnews_data.csv",mode='a+',index=False,sep='|',header=False)
3.编写爬虫
这是最重要的一步,之前做的所有都建立在我们编写的爬虫能爬取到我们所需要的数据。
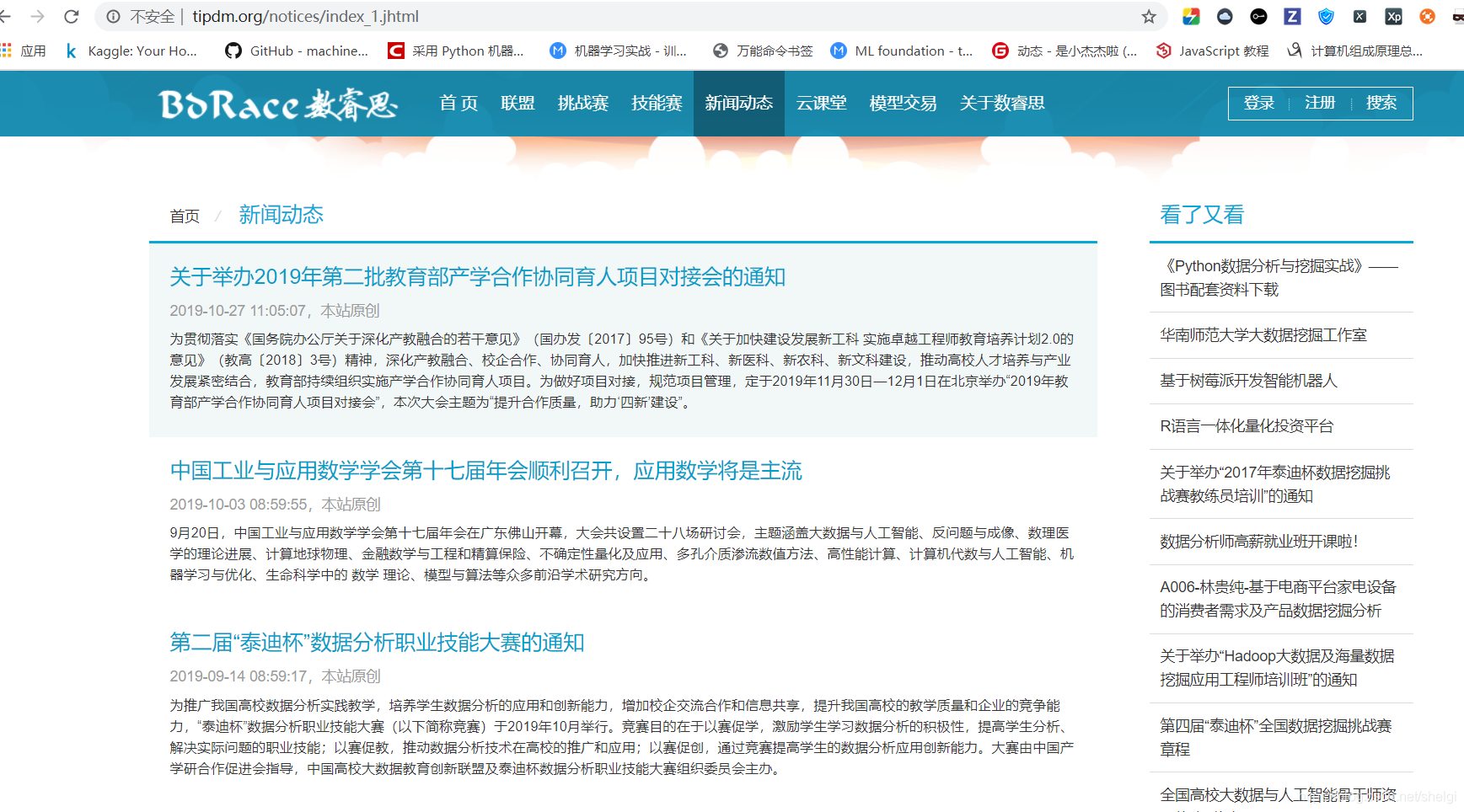
这是需要爬取的页面,我们要先确定爬虫思路
- 1.爬取所有的页面里面的所有的新闻链接
- 2.解析每一个新闻页面中的标题,内容,时间信息
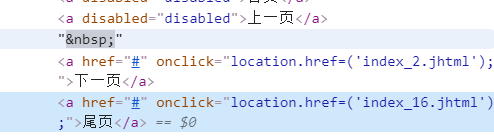
观察到了每个网页的url规律,自己构建url,为了偷懒也不去网页中提取尾页页数了,直接定为16
def parse(self, response):
last_page_num=16
append_urls=['http://www.tipdm.org/notices/index_%d.jhtml'%i for i in range(1,last_page_num+1)]
for url in append_urls:
yield Request(url,callback=self.parse_url,dont_filter=True)
然后得到的所有页面的链接,再去得到每条新闻的链接
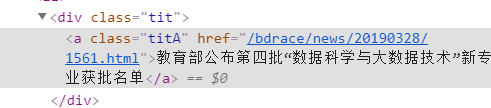
href后面跟着的就是每条新闻详情页面的链接,所以我们就遍历所有页面然后把这些链接都解析出来,最后把提取的链接加上host得到实际url
def parse_url(self,response):
urls=response.xpath("//div[@class='tit']/a/@href").extract()
for page_url in urls:
text_url='http://www.tipdm.org'+page_url
yield Request(text_url,callback=self.parse_text,dont_filter=True)
xpath的使用可以自己去百度,这里就不讲太多了,多用几次其实xpath很简单的
最后提取每个新闻详情页中的标题,内容,时间

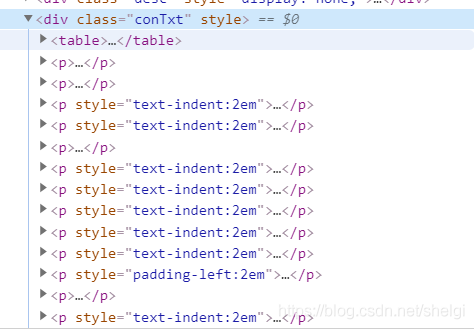
内容是所有p标签
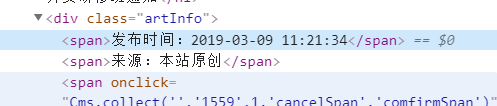
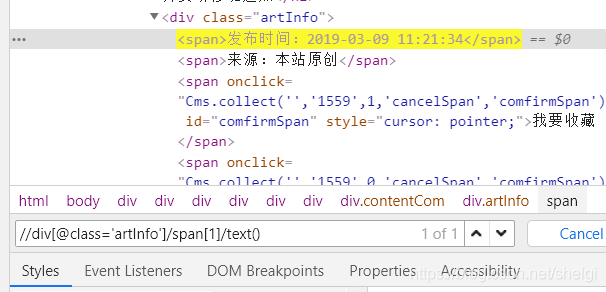
by the way,检查自己写的xpath对不对很简单,f12,选择elements,然后ctrl+F
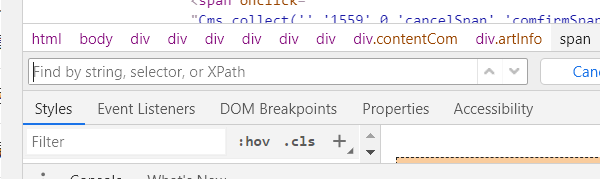
把自己写的输进去,如果找得到会提示的
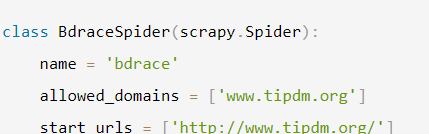
这是爬虫部分的代码
import scrapy
from scrapy.http import Request
from ..items import BdracenewsItem
class BdraceSpider(scrapy.Spider):
name = 'bdrace'
allowed_domains = ['www.tipdm.org']
start_urls = ['http://www.tipdm.org/']
def parse(self, response):
last_page_num=16
append_urls=['http://www.tipdm.org/notices/index_%d.jhtml'%i for i in range(1,last_page_num+1)]
for url in append_urls:
yield Request(url,callback=self.parse_url,dont_filter=True)
def parse_url(self,response):
urls=response.xpath("//div[@class='tit']/a/@href").extract()
for page_url in urls:
text_url='http://www.tipdm.org'+page_url
yield Request(text_url,callback=self.parse_text,dont_filter=True)
def parse_text(self,response):
item=BdracenewsItem()
item['title']=response.xpath("//div[@class='contentCom']/h1/text()").extract()
text=response.xpath("//div[@class='conTxt']//p/text()").extract()
texts=""
for string in text:
texts=texts+string+"\n"
item['text']=[texts.strip()]
item['time']=response.xpath("//div[@class='artInfo']/span[1]/text()").extract()
yield item
4.编写settings
这一步就比较简单了,需要使用的模板去掉注释,然后改成自己想要的就行。
这部分就不贴代码了,把上面要求的几个地方改一下就行
5.运行爬虫
scrapy crawl +name
这里的name就是你genspider创建的名字
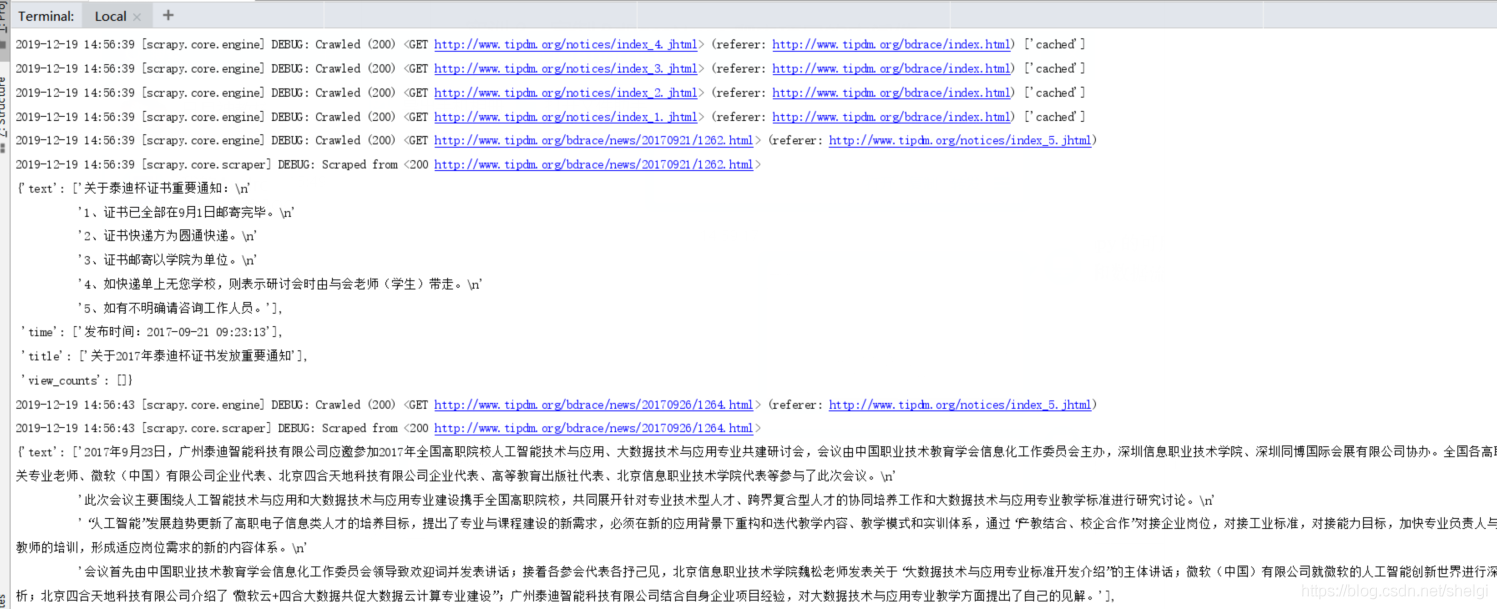
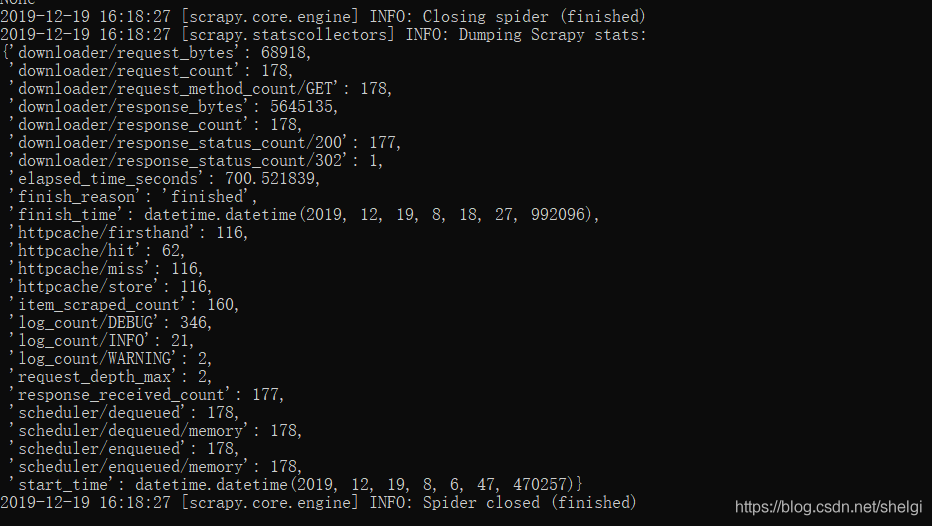
结果
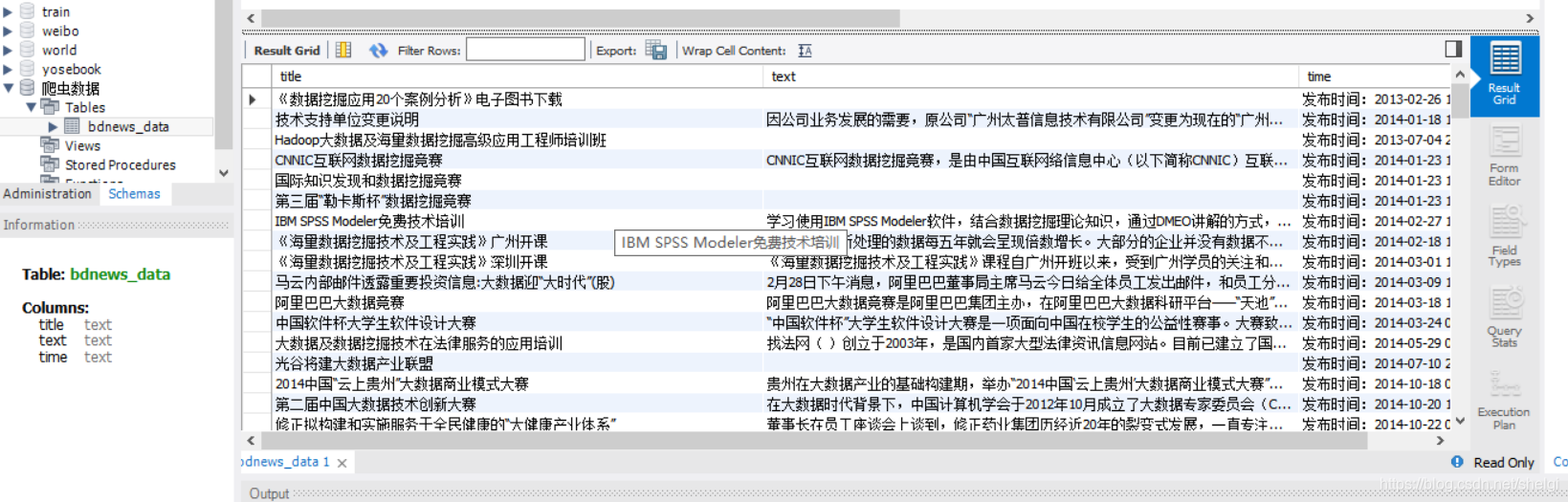

不过,什么都会也没用,世界本就不公,只能努力坚持变得更强,总有一天会得到回报。
cs