昨天日常睡前刷B站,看到一个很糟心的话题
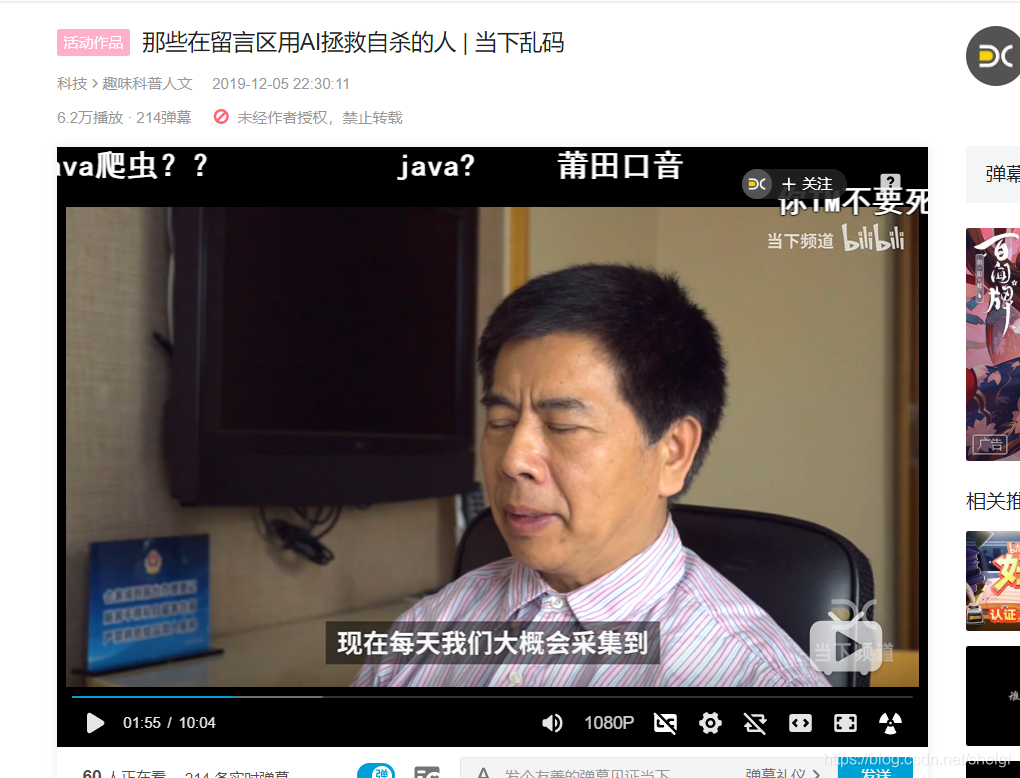
确实,抑郁很不好受。深夜常常一个人翻来覆去睡不着,眼泪不受控制的往下流,仿佛被世界抛弃,又或是突然的情绪爆发……经历很长一段时间后我走出了这个阴影,但是对某些人我可能会愧疚一辈子,我只能默默关注着她发的微博,但是不能去给她任何希望,所以每次看着她这么痛苦都会深深自责



负面情绪完全是她生活的主旋律,然后还看到其他类似的人
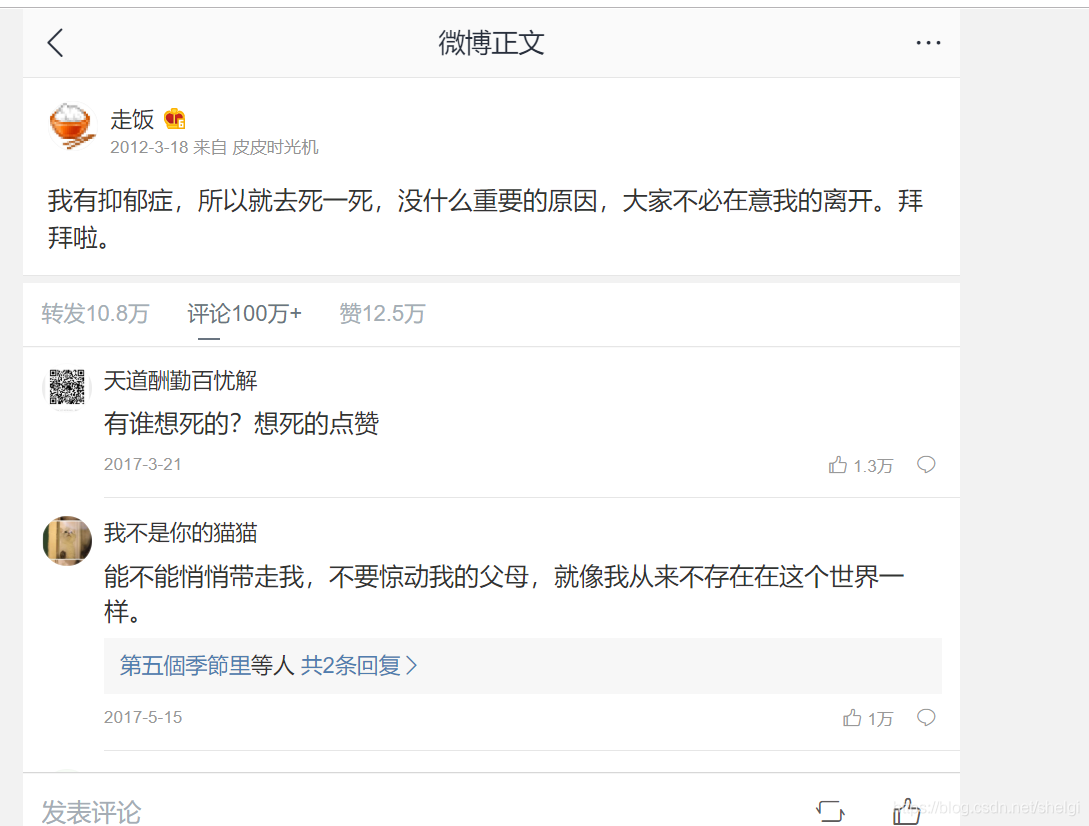
所以我就去到处找相关的项目,希望能用我们学的知识去帮助这些需要我们关心的人。
走饭微博的评论网址
去看这下面的评论,可以看到很多这样对生活很不乐观的人,不想让悲剧发生,所以我们要爬取所有评论,设计算法找到那些有放弃自己倾向的人
代码
然后半夜的时候我找了相关的各种链接,然后在一个公众号找到了相关的内容,具体的项目在GitHub,大家可以去这里查看。
具体的代码我也贴在这里
爬虫部分
import json
import requests
import time
import os
from lxml import etree
"""
爬取微博评论
"""
headers = {
'Referer': 'https://weibo.com/1648007681/yark9qWbM?type=comment',
'X-Requested-With': 'XMLHttpRequest',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.97 Safari/537.36',
'Cookie': '填自己的cookie',
}
def download_pic(url, nick_name):
pic_file_path = os.path.join(os.path.abspath(''), 'pic')
if not url:
return
if not os.path.exists(pic_file_path):
os.mkdir(pic_file_path)
resp = requests.get(url)
if resp.status_code == 200:
with open(pic_file_path + f'/{nick_name}.jpg', 'wb') as f:
f.write(resp.content)
time.sleep(2)
def write_comment(comment, pic_url, nick_name):
f = open('comment.txt', 'a', encoding='utf-8')
for index, i in enumerate(comment):
if ':' not in i and '回复' not in i and i != '':
w_comment = "".join(i.split(':')[1:])
print(w_comment)
w_comment = i.strip().replace('\n', '')
f.write(w_comment.replace('等人', '').replace('图片评论', '')+'\n')
download_pic(pic_url[index], nick_name[index])
if __name__ == '__main__':
params = {
'ajwvr': 6,
'id': '3424883176420210',
'page': 1,
'_rnd': int(round(time.time() * 1000))
}
URL = 'https://weibo.com/aj/v6/comment/big'
for num in range(1,25,1):
print(f'====== 正在读取第 {num} 页 ========')
params['page'] = num
params['_rnd'] = int(round(time.time() * 1000))
print(params['_rnd'])
resp = requests.get(URL, params=params, headers=headers)
resp = json.loads(resp.text)
if resp['code'] == '100000':
html = resp['data']['html']
html = etree.HTML(html)
data = html.xpath('//div[@node-type="comment_list"]')
for i in data:
nick_name = i.xpath('.//div[@class="WB_text"]/a[1]/text()')
text = i.xpath('.//div[@class="WB_text"]')
text = [i.xpath('string(.)') for i in text]
pic_url = i.xpath('.//div[@class="WB_face W_fl"]/a/img/@src')
print(len(nick_name),len(text),len(pic_url))
write_comment([i.strip() for i in text], pic_url, nick_name)
time.sleep(5)
具体实现方法就是去找网页,很简单就可以找到评论的json页
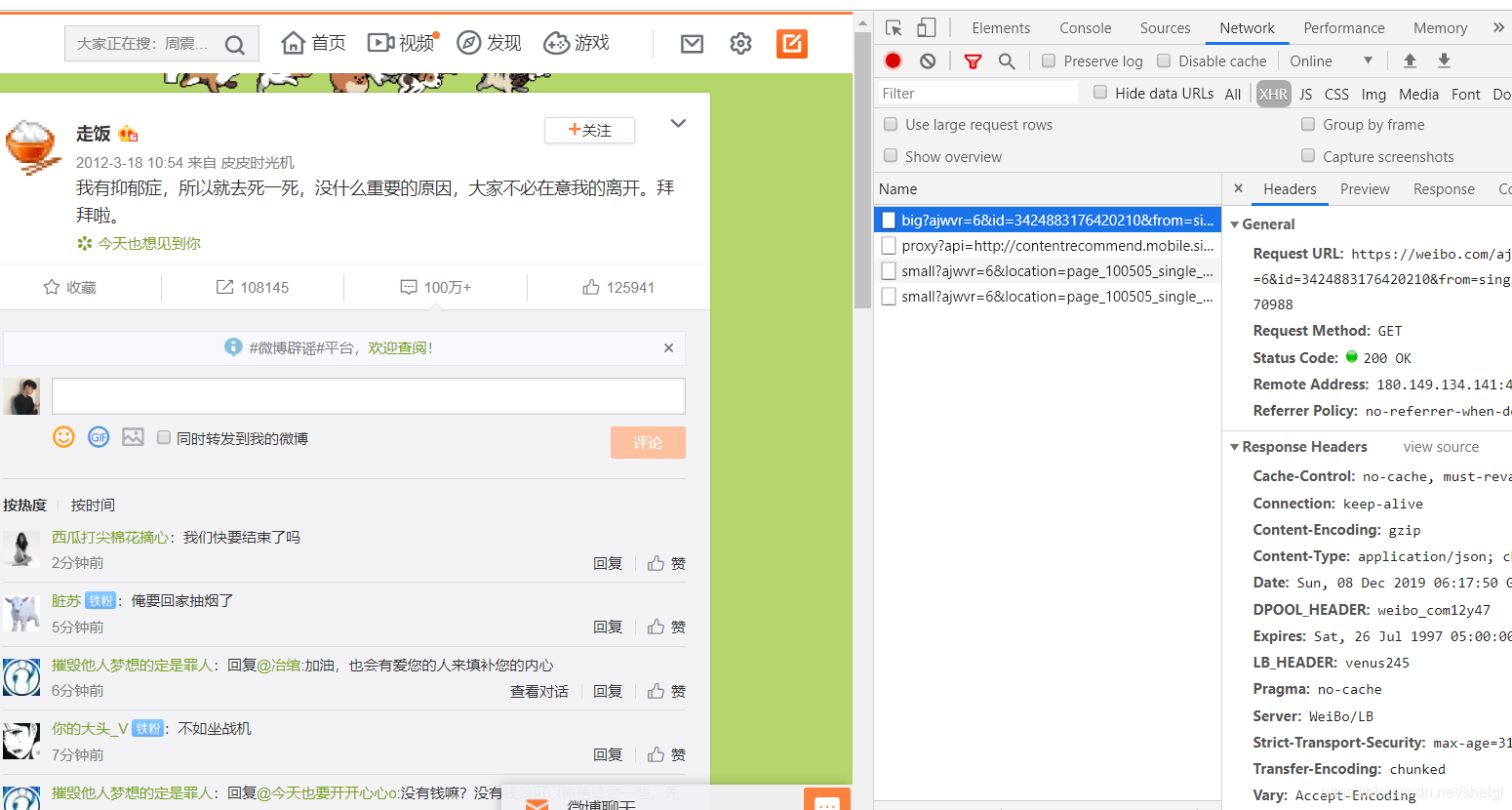

请求再解析网页,得到数据存入txt就行

分析判断部分
import sys
import numpy as np
import segment
from sklearn.model_selection import cross_val_score
from sklearn.metrics import classification_report
from sklearn import metrics
from sklearn.externals import joblib
seg = segment.segment()
print('(1) load texts...')
pos_train_filename = r'data\source\normal.txt'
neg_train_filename = r'data\source\die.txt'
pos_eval_filename = r'data\source\normal_test.txt'
neg_eval_filename = r'data\source\die_test.txt'
origin_pos_train = open(pos_train_filename, encoding='UTF-8').read().split('\n')
origin_neg_train = open(neg_train_filename, encoding='UTF-8').read().split('\n')
origin_pos_eval = open(pos_eval_filename, encoding='UTF-8').read().split('\n')
origin_neg_eval = open(neg_eval_filename, encoding='UTF-8').read().split('\n')
pos_train_dir, pos_train_label_dir = seg.seg_lines_list(1, pos_train_filename)
neg_train_dir, neg_train_label_dir = seg.seg_lines_list(0, neg_train_filename)
pos_test_dir, pos_test_label_dir = seg.seg_lines_list(1, pos_eval_filename)
neg_test_dir, neg_test_label_dir = seg.seg_lines_list(0, neg_eval_filename)
train_pos = open(pos_train_dir, encoding='UTF-8').read().split('\n')
train_neg = open(neg_train_dir, encoding='UTF-8').read().split('\n')
test_pos = open(pos_test_dir, encoding='UTF-8').read().split('\n')
test_neg = open(neg_test_dir, encoding='UTF-8').read().split('\n')
train_pos_label = open(pos_train_label_dir, encoding='UTF-8').read().split('\n')
train_neg_label = open(neg_train_label_dir, encoding='UTF-8').read().split('\n')
test_pos_label = open(pos_test_label_dir, encoding='UTF-8').read().split('\n')
test_neg_label = open(neg_test_label_dir, encoding='UTF-8').read().split('\n')
origin_train_text = origin_pos_train + origin_neg_train
origin_eval_text = origin_pos_eval + origin_neg_eval
train_texts = train_pos + train_neg
test_texts = test_pos + test_neg
train_labels = train_pos_label + train_neg_label
test_labels = test_pos_label + test_neg_label
all_text = train_texts + test_texts
all_labels = train_labels + test_labels
print('(2) doc to var...')
from sklearn.feature_extraction.text import CountVectorizer, TfidfTransformer
count_v0= CountVectorizer(analyzer='word',token_pattern='\w{1,}')
counts_all = count_v0.