梯度下降算法
致力于找到损失函数极值点,学习即是改进模型参数,以便通过大量训练步骤将损失最小化。
梯度的输出由若干偏导数构成的向量,每个分量对应于函数对输入向量的相应分量的偏导:
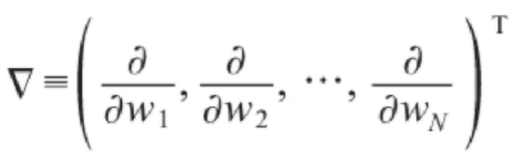
梯度的输出向量表明了在每个位置损失函数增长最快的方向,可以理解为函数在每个位置向哪个方向移动可以增长函数值。
随机初始化,初始化一批值,需要计算梯度值,找到损失值变化最快的方向。
每一次移动的距离,叫做学习速率。学习速率小,迭代次数多,训练慢;学习速率大,会错过极值点,后面会在极值点附近来回抖动。
不用担心局部极值点,是随机初始化的,总能找到最小的极值点。
感知器
线性回归模型是单个神经元:1、计算输入特征的加权和;2、使用一个激活函数计算输出。
缺陷:
要求数据必须线性可分,异或问题无法找到一条直线分割两个类
多个神经元:多层感知器
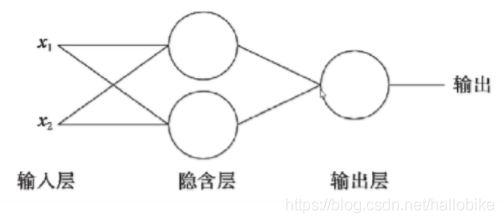
为了使用神经网络解决这种不具备线性可分性的问题,采取在神经网络的输入和输出端之间插入更多的神经元。
激活函数
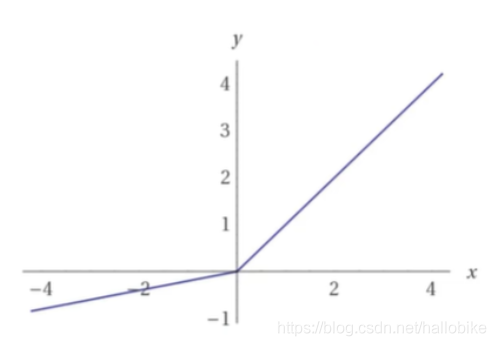
relu:输入信号小于0直接屏蔽,输出0;输入信号大于0,信号原样输出。
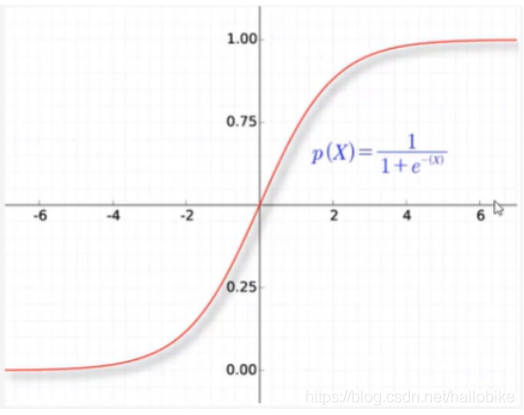
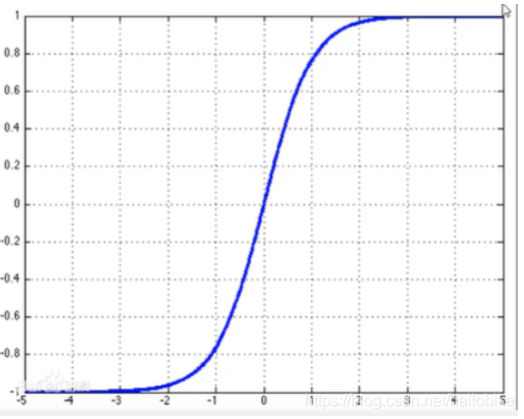
sigmoid:输出结果控制在-1和1之间;靠近0时,输出陡峭,变化快;远大于0远小于0时,输出就趋于稳定,变化小,传入梯度就小。很少用在多层感知机的中间层。
tanh:输出结果映射在-1和1之间
Leak relu:将负值信号传入一点进来,不像relu直接屏蔽。一般用在深层网络里面。
网络结构
"""
Author: LGD
FileName: gradient_descent
DateTime: 2020/10/21 10:41
SoftWare: PyCharm
"""
"""
梯度下降算法
致力于找到损失函数极值点,学习即是改进模型参数,以便通过大量训练步骤将损失最小化
梯度的输出由若干偏导数构成的向量,每个分量对应于函数对输入向量的相应分量的偏导。
梯度的输出向量表明了在每个位置损失函数增长最快的方向,可以理解为函数在每个位置向哪个方向移动可以增长函数值。
随机初始化,初始化一批值,需要计算梯度值,找到损失值变化最快的方向。
每一次移动的距离,叫做学习速率。学习速率小,迭代次数多,训练慢;学习速率大,会错过极值点,后面会在极值点附近来回抖动。
不用担心局部极值点,是随机初始化的,总能找到最小的极值点。
"""
"""
线性回归模型是单个神经元:1、计算输入特征的加权和;2、使用一个激活函数计算输出。
要求数据必须线性可分,异或问题无法找到一条直线分割两个类
多个神经元:多层感知器
为了使用神经网络解决这种不具备线性可分性的问题,采取在神经网络的输入和输出端之间插入更多的神经元。
激活函数:relu(经典,常用)
输入信号小于0直接屏蔽,输出0;
输入信号大于0,信号原样输出。
sigmoid
输出结果控制在-1和1之间;靠近0时,输出陡峭,变化快;远大于0远小于0时,输出就趋于稳定,变化小,传入梯度就小。
很少用在多层感知机的中间层。
tanh
输出结果映射在-1和1之间
Leak relu
将负值信号传入一点进来,不像relu直接屏蔽。一般用在深层网络里面。
"""
import tensorflow as tf
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
data = pd.read_csv("datasets/Advertising.csv")
print(data.head())
plt.scatter(data.TV, data.sales)
plt.show()
plt.scatter(data.radio, data.sales)
plt.show()
plt.scatter(data.newspaper, data.sales)
plt.show()
x = data.iloc[:, 1:-1]
print(x)
y = data.iloc[:, -1]
print(y)
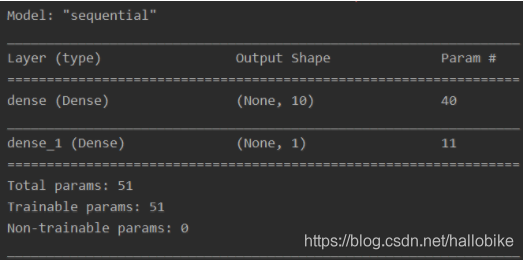
model = tf.keras.Sequential(
[tf.keras.layers.Dense(10, input_shape=(3,), activation='relu'),
tf.keras.layers.Dense(1)]
)
network_structure = model.summary()
print(network_structure)
model.compile(
optimizer='adam',
loss='mse'
)
history = model.fit(x, y, epochs=100)
print(history)
test = data.iloc[:10, -1]
print(test)
test = data.iloc[:10, 1:-1]
result = model.predict(test)
print(result)
cs