softmax¶а·ЦАа
¶ФКэјёВК»Ш№йҪвҫцөДКЗ¶ю·ЦАаОКМв,¶ФУЪ¶а·ЦАаОКМв,ОТГЗҝЙТФК№УГsoftmaxәҜКэ,ЛьКЗ¶ФКэјёВК»Ш№йФЪNёцҝЙДЬөДЦөЙПөДНЖ№гЎЈ
ЙсҫӯНшВзөДФӯКјКдіцІ»КЗТ»ёцёЕВКЦө,КөЦКЙПКЗКдИләҜКэөДЦөЧцБЛёҙФУөДјУИЁәН·ЗПЯРФҙҰАнәуөДТ»ёцЦө,ДЗИзәОҪ«ХвёцКдіцұдОӘёЕВК·ЦІјДШ?ХвҫНКЗsoftmaxІгөДЧчУГЎЈ
softmax№«КҪ:
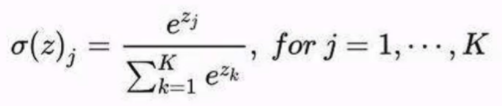
softmaxІгТӘЗуГҝёцСщұҫұШРлКфУЪДіёцАаұр,ЗТЛщУРҝЙДЬөДСщұҫҫщұ»ёІёЗЎЈ
softmaxөДСщұҫ·ЦБҝЦ®әНОӘ1,өұЦ»УРБҪёцАаұрКұ,Ул¶ФКэјёВК»Ш№йНкИ«ПаН¬ЎЈФЪtf.kerasАп,¶ФУЪ¶а·ЦАаОКМвОТГЗК№УГcategorical_crossentropyәНsparse_categorical_crossentropyАҙјЖЛгsoftmaxҪ»ІжмШЎЈ
Fashion MNISTКэҫЭјҜ
КЗҫӯөдөДMNISTКэҫЭјҜөДјтТЧМж»»,MNISTКэҫЭјҜ°ьә¬КЦРҙКэЧЦ(0Ўў1Ўў2өИ)өДНјПс,ХвР©НјПсёсКҪУлұҫАэЧУЦРК№УГөД·юКОНјПсёсКҪПаН¬ЎЈұИіЈ№жMNISTКЦРҙКэҫЭјҜёьҫЯУРМфХҪРФЎЈХвБҪёцКэҫЭјҜ¶јПа¶ФұИҪПРЎ,УГУЪСйЦӨДіёцЛг·ЁДЬ·сИзЖЪХэіЈФЛРРЎЈЛьГЗ¶јКЗІвКФәНөчКФҙъВлөДБјәГЖрөгЎЈ
Fashion MNISTКэҫЭјҜ°ьә¬70000ХЕ»Т¶ИНјПс,әӯёЗ10ёцАаұрЎЈ

ұҫАэЧУҪ«К№УГ60000ХЕНјПсСөБ·НшВз,ІўК№УГ10000ХЕНјПсЖА№Аҫӯ№эС§П°өДНшВз·ЦАаНјПсөДЧјИ·ВКЎЈҝЙТФҙУTensorFlowЦұҪУ·ГОКFashion MNIST,Ц»РиөјИләНјУФШКэҫЭјҙҝЙЎЈ
import tensorflow as tf
import matplotlib.pyplot as plt
import numpy as np
(train_image, train_label), (test_image, test_label) = tf.keras.datasets.fashion_mnist.load_data()
train_shape = train_image.shape
print(train_shape)
test_shape = test_image.shape
print(test_shape)
plt.imshow(train_image[0])
plt.show()
print(train_image[0])
print(np.max(train_image[0]))
print(train_label)
train_image = train_image / 255
test_image = test_image / 255
model = tf.keras.Sequential()
model.add(tf.keras.layers.Flatten(input_shape=(28, 28)))
model.add(tf.keras.layers.Dense(128, activation='relu'))
model.add(tf.keras.layers.Dense(10, activation='softmax'))
model.summary()
model.compile(
optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['acc']
)
history = model.fit(train_image, train_label, epochs=5)
model.evaluate(test_image, test_label)
sparse_categorical_crossentropyјЖЛгsoftmaxҪ»ІжмШұкЗ©К№УГКэЧЦЛіРтұд»ҜЦөКұК№УГХвёцәҜКэЎЈ
categorical_crossentropyјЖЛгsoftmaxҪ»ІжмШұкЗ©К№УГ¶АИИұаВлКұҫНК№УГХвёцәҜКэЎЈ¶АИИұаВл:КЗКэЦө»ҜөД·Ҫ·Ё;ұИИзёшИэёціЗКРұаВл,beijing[1, 0, 0], shanghai[0, 1, 0], shenzhen[0, 0, 1]ЎЈҫНКЗ¶АИИұаВл
train_label_onehot = tf.keras.utils.to_categorical(train_label)
print(train_label_onehot[-1])
test_label_onehot = tf.keras.utils.to_categorical(test_label)
print(test_label_onehot)
model = tf.keras.Sequential()
model.add(tf.keras.layers.Flatten(input_shape=(28, 28)))
model.add(tf.keras.layers.Dense(128, activation='relu'))
model.add(tf.keras.layers.Dense(10, activation='softmax'))
model.summary()
model.compile(
optimizer='adam',
loss='categorical_crossentropy',
metrics=['acc']
)
history = model.fit(train_image, train_label_onehot, epochs=5)
predict = model.predict(test_image)
print(predict.shape)
print(predict[0])
print(np.argmax(predict[0]))
print(test_label[0])
cs