语义分割简介
图像语义分割是计算机视觉中十分重要的领域。它是指像素级地识别图像,即标注出图像中每个像素所属的对象类别。

上图为语义分割的一个实例,其目标是预测出图像中每一个像素的类标签。
图像语义分割是图像处理和计算机视觉技术中关于图像理解的重要的一环。语义分割对图像中的每一个像素点进行分类,确定每个点的类别(如属于背景、边缘或身体等)
需要和实例分割区分开来。语义分割没有分离同一类的实例;它关心的只是每个像素的类别,如果输入对象中有两个相同类别的对象,则分割本身不会将它们区分为单独的对象。

图像语义分割应用
1、自动驾驶汽车: 我们需要为汽车增加必要的感知,以了解他们所处的环境,以便自动驾驶的汽车可以安全行驶;
2、医学图像诊断: 机器可以增强放射医生进行的分析,大大减少运行诊断测试所需的时间;
3、无人机着陆点判断等
eg:对街道景的语义分割
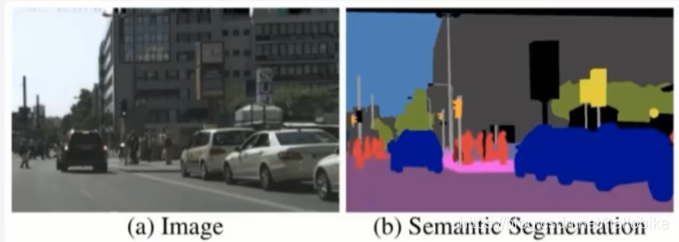
语义分割的实质
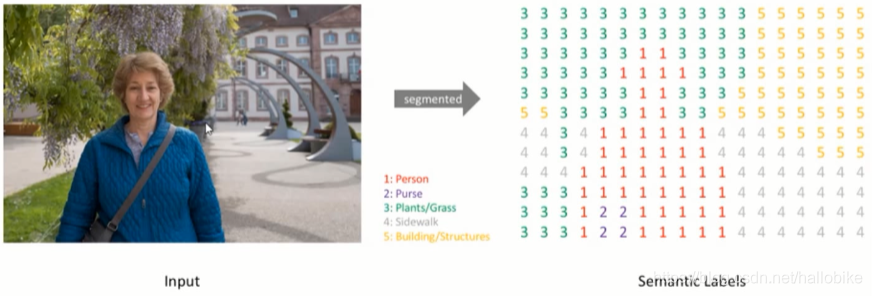
语义分割的目标
一般是指将一张RGB图像(height×width×3)或是灰度图(height×width×1)作为输入,输出的是分割图,其中每一个像素包含了其类别的标签(height×width×1)

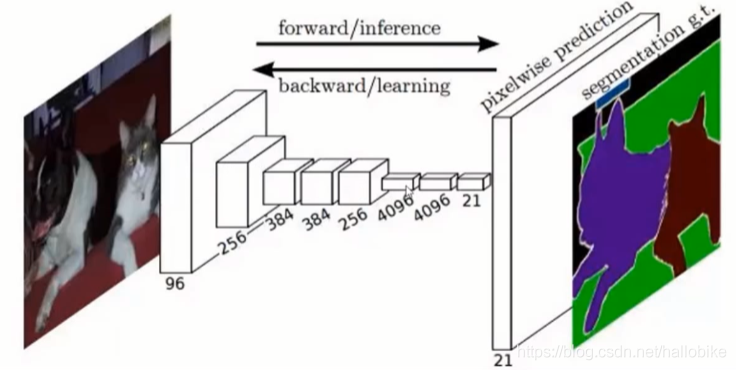
图像语义分割的实现
目前在图像分割领域比较成功的算法,有很大一部分都来自于同一个先驱:Long等人提出的Fully Convolutional Network(FCN),或者叫全卷积网络。
FCN将分类网络转换成用于分割任务的网络结构,并证明了在分割问题上,可以实现端到端的网络训练。
FCN成为了深度学习解决分割问题的奠基石。
图像语义分割的实现
分类网络结构尽管表面上来看可以接受任意尺寸的图片作为输入,但是由于网络结构最后全链接层的存在,使其丢失了输入的空间信息,因此,这些网络并没有办法直接用于解决诸如分割等稠密估计的问题。
基于这一点考虑,FCN用卷积层和池化层代替了分类网络中的全链接层,从而使得网络结构可以适应像素级的稠密估计任务。
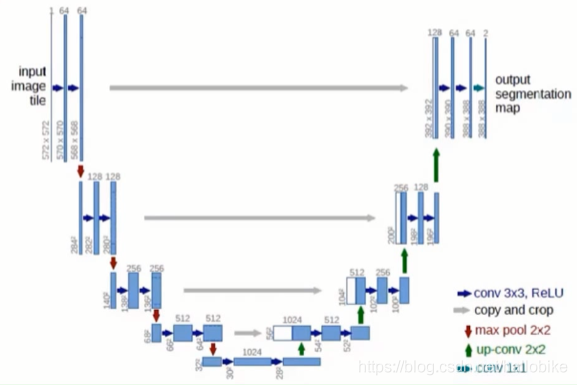
语义分割的UNET网络结构
UNET是2015年诞生的模型,它几乎是当前segmentation项目中应用最广泛的模型。
UNET能从更少的训练图像中进行学习。当它在少于40张图的生物医学数据集上训练时,IOU的值仍能达到92%。
cs