这网站名字绝了,当擦哥看到的那一瞬间,我估计他就准备好爬虫代码了。
Python 爬虫 120 例,已完成文章清单
- 10 行代码集 2000 张美女图,Python 爬虫 120 例,再上征途
- 通过 Python 爬虫,发现 60%女装大佬游走在 cosplay 领域
- Python 千猫图,简单技术满足你的收集控
- 熊孩子说“你没看过奥特曼”,赶紧用 Python 学习一下,没想到
- 技术圈的【多肉小达人】,一篇文章你就能做到
- 我用 Python 连夜离线了 100G 图片,只为了防止网站被消失
可爱图片网双线程爬取
这篇博客要对 Python 爬虫进行提速了,实现双线程爬虫。而且在爬取过程中,还有意外收货。
爬取目标分析
爬取目标
- 可爱图片网 https://www.keaitupian.net/
- 图片分类非常丰富,想要抓取的都有,例如 可爱女生,性感美女,不过为了更好的学习技术,我决定只抓卡通动漫分类图片,其它的留给各位大佬读者了。
使用的 Python 模块
- 本次使用
requests,re,threading。 - 新增加线程并行模块
threading。
重点学习内容
- 爬虫基本套路;
- 不确定页码数据爬取;
- 固定线程数爬虫。
列表页与详情页分析
- 列表页抓取卡通动漫图片,故列表页为
https://www.keaitupian.net/dongman/,点击多个页码,可得到如下规则: - https://www.keaitupian.net/dongman/list-1.html
- https://www.keaitupian.net/dongman/list-2.html
- https://www.keaitupian.net/dongman/list-{不定页码}.html
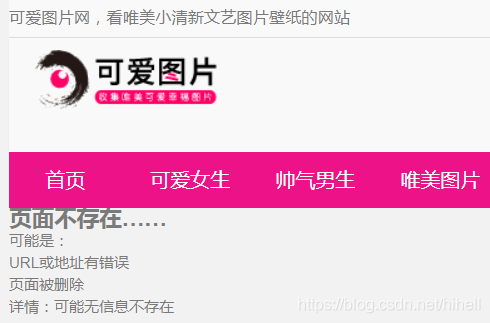
由于列表总页数无法直接获取到,顾使用大数测试,当输入 https://www.keaitupian.net/dongman/list-110.html 时,页面展示为不存在,如下图所示。
实际测试之后,得到该分类下列表页存在 77 页。
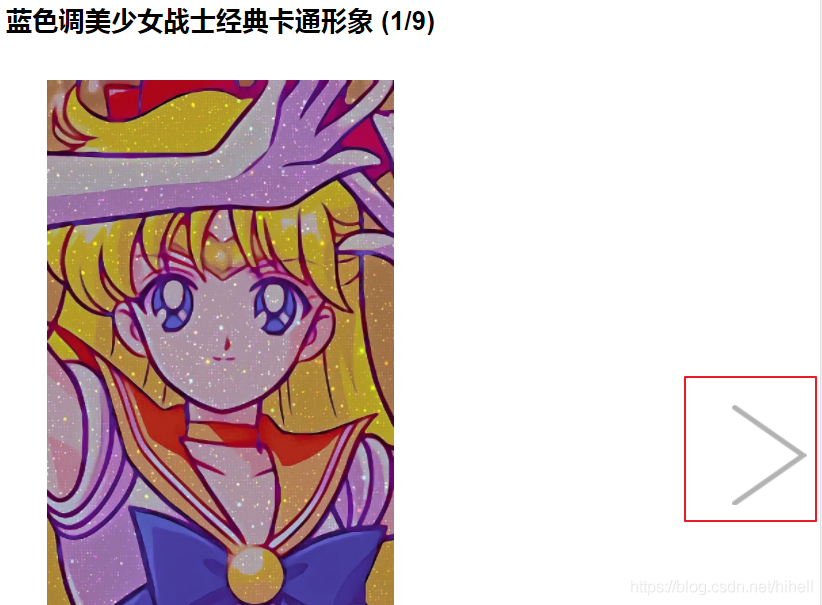
点击任意图片详情页,查看图片页具体内容,发现详情页也存在翻页,而且该翻页可以在列表页之间跳转,例如下图翻页到 9/9 之后,可进入到下一套图中。因此可以直接针对详情页进行数据抓取。
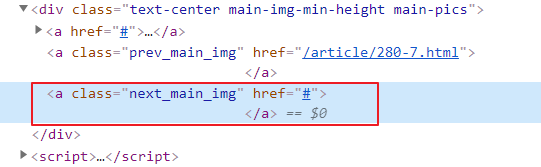
获取列表第 77 页最后一组照片,查看最后一组照片翻页数据代码,发现最后向右侧翻页代码为空,即无法翻页。
最后一页数据查看:https://www.keaitupian.net/article/280-8.html#。
目标网站分析完毕,梳理整体逻辑,出需求。
整理需求逻辑
- 随机选择一详情页地址,作为爬虫起始页面;
- 一线程保存图片;
- 一线程保存下一页地址。
编码时间
抓取目标请求地址
基于上述需求,首先实现循环获取 URL 的线程,该线程主要用于反复爬取 URL 地址,保存至一全局列表中。
需要使用到 threading.Thread 创建线程与启动线程,同时为保证线程之间的数据传递,需要用到线程互斥锁。
锁的声明:
mutex = threading.Lock()
锁的使用:
global urls
mutex.acquire()
urls.append(next_url)
mutex.release()
编写 URL 获取地址代码如下:
import requests
import re
import threading
import time
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36"}
urls = []
mutex = threading.Lock()
def get_image(start_url):
global urls
urls.append(start_url)
next_url = start_url
while next_url != "#":
res = requests.get(url=next_url, headers=headers)
if res is not None:
html = res.text
pattern = re.compile('<a class="next_main_img" href="(.*?)">')
match = pattern.search(html)
if match:
next_url = match.group(1)
if next_url.find('www.keaitupian') < 0:
next_url = f"https://www.keaitupian.net{next_url}"
print(next_url)
mutex.acquire()
urls.append(next_url)
mutex.release()
if __name__ == '__main__':
gets = threading.Thread(target=get_image, args=(
"https://www.keaitupian.net/article/202389.html",))
gets.start()
运行代码,得到待抓取的目标地址,控制台输出如下内容:
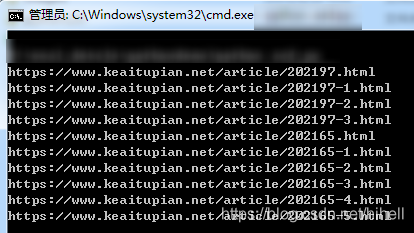
提取目标地址图片
下面即为最后一个步骤,通过上述代码抓取到的链接地址,提取图片地址,并保存图片。
保存图片也为一个线程,该线程对应的 save_image 函数如下:
def save_image():
global urls
print(urls)
while True:
mutex.acquire()
if len(urls) > 0:
img_url = urls[0]
del urls[0]
mutex.release()
res = requests.get(url=img_url, headers=headers)
if res is not None:
html = res.text
pattern = re.compile(
'<img class="img-responsive center-block" src="(.*?)"/>')
img_match = pattern.search(html)
if img_match:
img_data_url = img_match.group(1)
print("抓取图片中:", img_data_url)
try:
res = requests.get(img_data_url)
with open(f"images/{time.time()}.png", "wb+") as f:
f.write(res.content)
except Exception as e:
print(e)
else:
print("等待中,长时间等待,可以直接关闭")
同步在主函数中增加基于该函数的线程,并启动:
if __name__ == '__main__':
gets = threading.Thread(target=get_image, args=(
"https://www.keaitupian.net/article/202389.html",))
gets.start()
save = threading.Thread(target=save_image)
save.start()
完整代码下载地址:https://codechina.csdn.net/hihell/python120,NO7。
代码编写过程中,顺手爬取了一堆图片,可以提前预览一波,看看图,在决定是否运行这段代码。
https://download.csdn.net/download/hihell/19759050
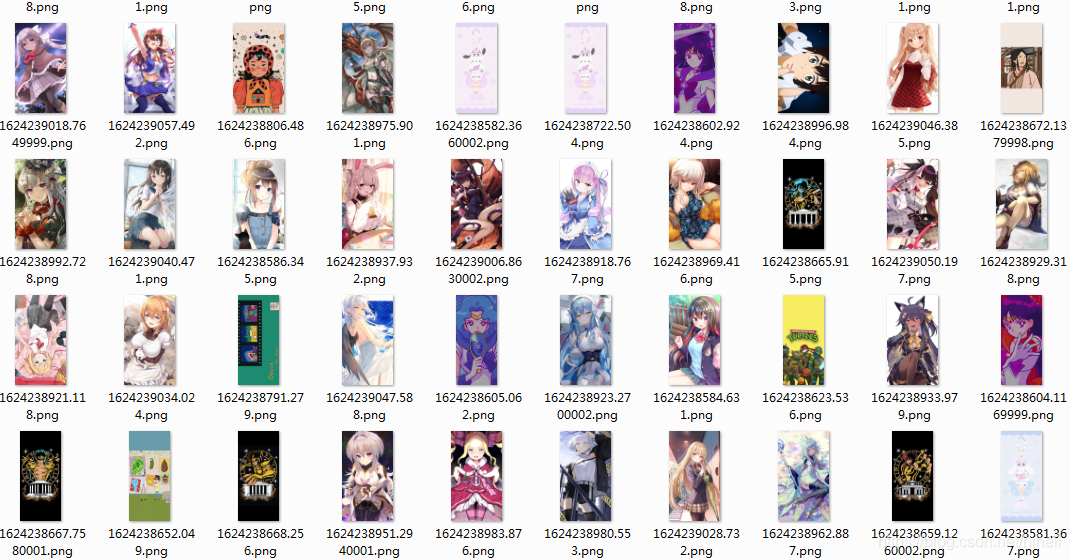
抽奖时间
上一篇文章 《我用Python连夜离线了100G图片,只为了防止网站被消失》 评论数没有达到 100,但是出现了一个热评大佬 幻想家37927,这不得不送一份一折券了,抓紧联系橡皮擦哦~。
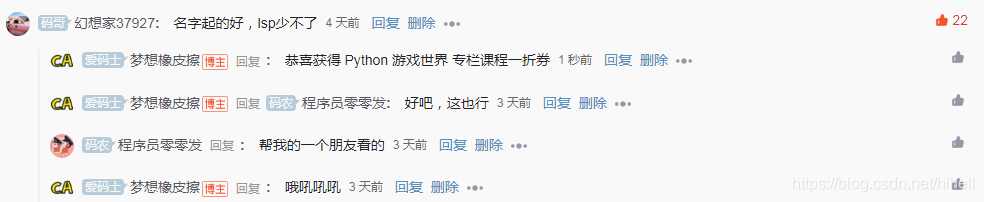
只要评论数过 100
随机抽取一名幸运读者
奖励 29.9 元《Python 游戏世界》 1 折购买券一份,只需 2.99 元
今天是持续写作的第 167 / 200 天。可以点赞、评论、收藏啦。
cs