汉服,是真的漂亮
阅读本篇博客你将收获
- Python 技术的提升
- 40000+张汉服照片,或者更多
汉服照片采集术
目标数据源分析
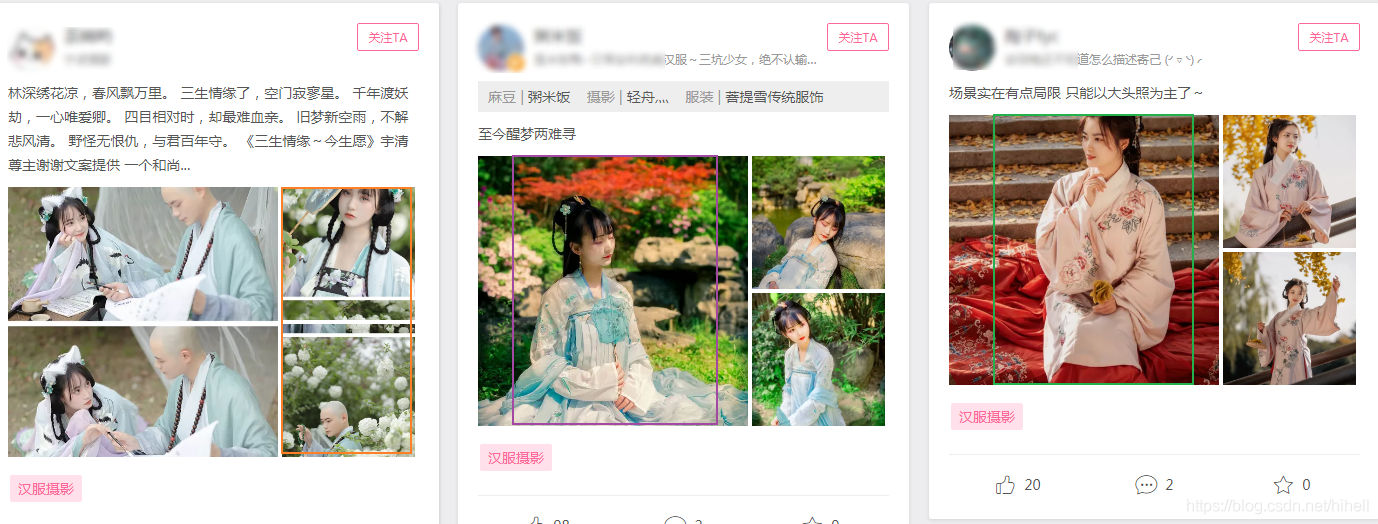
本次要抓取的目标数据参考下图。目标网站为 https://www.hanfuhui.com/,一个以汉服同袍为中心的垂直社区。
本篇博客将要涉及的知识点
- requests 读取 json 数据;
- json 格式数据解析;
- csv 文件存储;
- 文件读取+图片保存。
数据来源分析
-
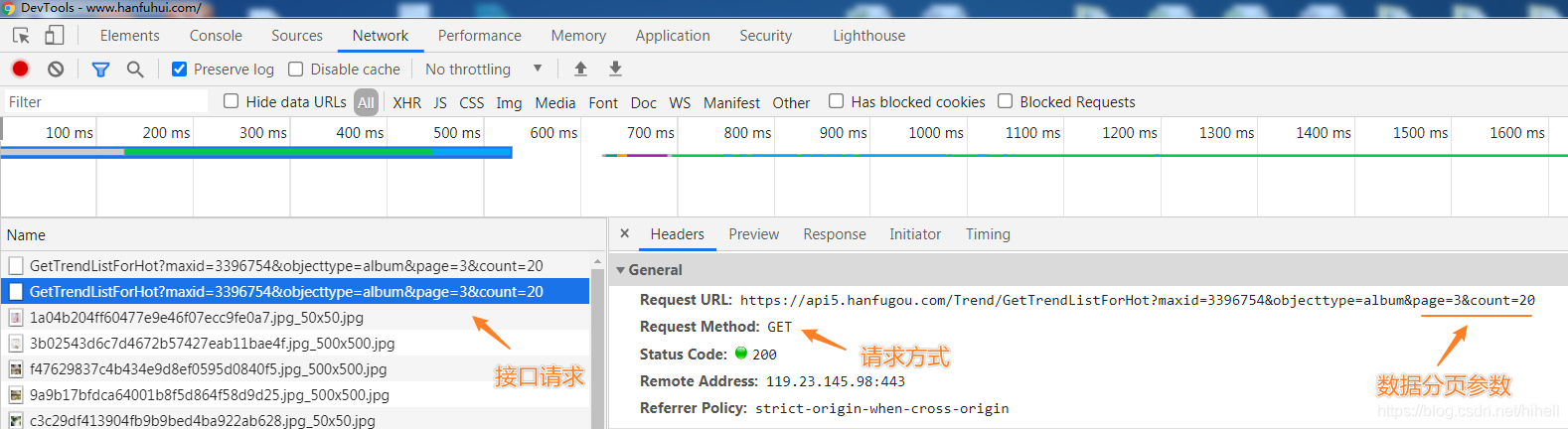
本次抓取的目标数据为异步传输,即通过服务器接口返回,通过浏览器开发者工具查询接口结构如下:
-
数据接口为:https://api5.hanfugou.com/Trend/GetTrendListForHot?maxid=3396754&objecttype=album&page=3&count=20,其中重要的参数为 page 与 count,即页码与每页数据量,测试过程发现,count 值可以任意修改,当超过 100 之后,接口返回数据速度变慢,后续该值设置为 500。
-
接口响应的数据格式为 JSON,如下图所示,接口成功状态为 Status,接口核心数据在 Data 中。
-

-
关于 JSON 格式数据的更多学习,可以寻找相应的资料扩展学习,也可以从案例入手,逐步掌握,例如跟随《Python 爬虫 120》专栏,在实践中学习。
需求整理
基于上述分析,整理如下需求:
- 批量生成接口地址,用于提取图片地址;
- 为保证效率,将提取到的图片地址批量存储到
csv 文件中; - 读取
csv 文件中的图片地址,拼接可下载链接; - 下载图片。
案例编码
首先使用 requests 进行基础数据抓取,本步骤比较简单,直接展示代码即可。
import requests
from lxml import etree
import time
import re
import random
USER_AGENTS = [
"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.85 Safari/537.36",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0; Acoo Browser; SLCC1; .NET CLR 2.0.50727; Media Center PC 5.0; .NET CLR 3.0.04506)",
"其它 USER_AGENT 自己搜集即可"
]
def run(url):
try:
headers = {"User-Agent": random.choice(USER_AGENTS)}
res = requests.get(url=url, headers=headers)
json_text = res.json()
data = json_text["Data"]
img_srcs = []
for item in data:
img_srcs.extend(item["ImageSrcs"])
long_str = "\n".join(img_srcs)
save(long_str)
except Exception as e:
print(e)
def save(long_str):
try:
with open(f"./imgs.csv", "a+") as f:
f.write("\n"+long_str)
except Exception as e:
print(e)
if __name__ == '__main__':
urls = []
for i in range(1, 10):
print(f"正在爬取第{i}批数据")
run(f"https://api5.hanfugou.com/Trend/GetTrendListForHot?maxid=3396754&objecttype=album&page={i}&count=500")
print("全部爬取完毕")
上述代码缺少接口状态验证逻辑,相关注释已经标注在指定位置,如有必要,可进行扩展。
第一步保存的数据由 40000+,已经满足后续使用,接下来编写获取图片相关逻辑代码。

通过 csv 文件获取的图片连接,直接请求,得到的是一张名称为 hanfuhui-pi-404 的图片,即该请求存在问题。
后续再次测试过程,发现部分图片连接可访问,部分返回 404 图,存在差异化。此处不在进行特殊化处理。
通过页面详情页,获取图片地址,得到如下规律。
当图片地址为 https://pic.hanfugou.com/android/2020/2/30/3b2c6bc54cfa4656a81b4f9b4167e2c3.jpg 时,下载失败,在此基础上,增加图片大小限制,即 https://pic.hanfugou.com/android/2020/2/30/3b2c6bc54cfa4656a81b4f9b4167e2c3.jpg_700x.jpg 得到正确的图片,仅降低了清晰度。
图片抓取代码如下
使用如下代码,需要提前在代码文件目录建立 hanfu 目录,用于存放图片。
由于图片地址的请求协议为 https,顾需要在 requests 发起请求的方法中,新增加一个参数 verify,并设置为 False,该参数表示请求数据时,不验证网站的 ca 证书。
def save_img(img_src):
try:
url = img_src
headers = {"User-Agent": random.choice(USER_AGENTS)}
res = requests.get(url=url, headers=headers, verify=False)
data = res.content
with open(f"./hanfu/{int(time.time())}.jpg", "wb+") as f:
f.write(data)
except Exception as e:
print(e)
if __name__ == '__main__':
with open("./imgs.csv","r") as f:
while True:
img_url = f.readline().strip()
if img_url is None:
break
real_url = f"{img_url}_700x.jpg"
save_img(real_url)
代码编写完毕,接下来就是等待程序给我们进货的时间了,出去喝茶啦。
抓取结果展示时间
本次抓取的数据,已经上传到 CSDN 下载频道,源码分享在代码频道。
完整代码下载地址:https://codechina.csdn.net/hihell/python120,NO13。
以下是爬取过程中产生的各种各种图片,如果只需要数据,可去下载频道下载~(硬盘空间有限,剩下的交给你了)
爬取资源仅供学习使用,侵权删。
抽奖时间
评论数过 100,随机抽取一名幸运读者,
获取 29.9 元《Python 游戏世界》专栏 1 折购买券一份,只需 2.99 元。
今天是持续写作的第 177 / 200 天。
可以关注我,点赞我、评论我、收藏我啦。
更多精彩
- Python 爬虫 100 例教程导航帖(已完结)
cs