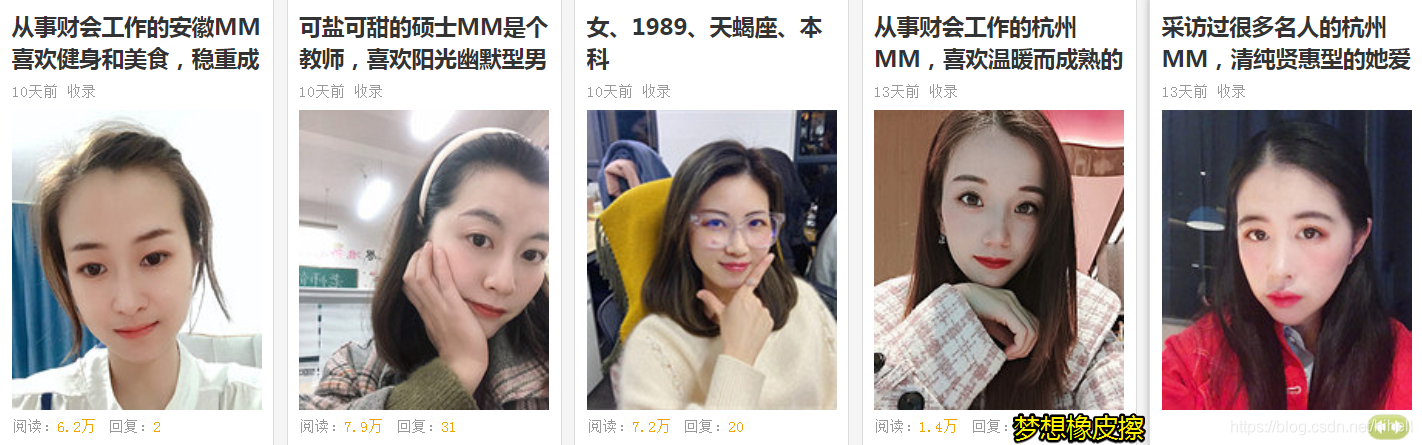
import requests
from lxml import etree
from fake_useragent import UserAgent
import time
def save(src, title):
try:
res = requests.get(src)
with open(f"imgs/{title}.jpg", "wb+") as f:
f.write(res.content)
except Exception as e:
print(e)
def run(url):
ua = "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.85 Safari/537.36"
headers = {
"User-Agent": ua,
"Host": "www.19lou.com",
"Referer": "https://www.19lou.com/r/1/19lnsxq-233.html",
"Cookie": "_Z3nY0d4C_=37XgPK9h"
}
try:
res = requests.get(url=url, headers=headers)
text = res.text
html = etree.HTML(text)
divs = html.xpath("//div[@class='pics']")
for div in divs:
src = div.xpath("./img/@data-src")[0]
title = div.xpath("./img/@alt")[0]
save(src, title)
except Exception as e:
print(e)
if __name__ == '__main__':
urls = ["https://www.19lou.com/r/1/19lnsxq.html"]
for i in range(114, 243):
urls.append(f"https://www.19lou.com/r/1/19lnsxq-{i}.html")
for url in urls:
print(f"正在抓取{url}")
run(url)
print("全部爬取完毕")
为了提高效率,你可以取消 5 秒等待,也可以采用多线程,不过尝试几秒钟就好了,不要过度抓取哦,毕竟咱们只为学习。
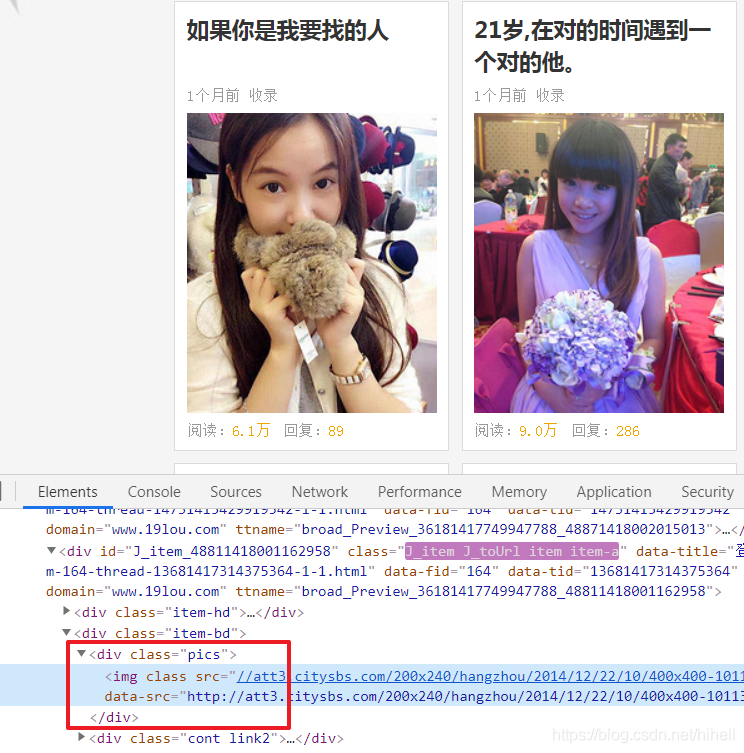
上述代码还存在一个重要知识点,在获取到的源码中图片的 src 属性为 dot.gif(加载图片),data-src 属性存在值。
具体对比如下图所示,上图为直接查看页面源码,下图为服务器直接返回源码。
这部分给我们的爬取提示为,任何数据的解析提取,都要依据服务器直接返回的源码。

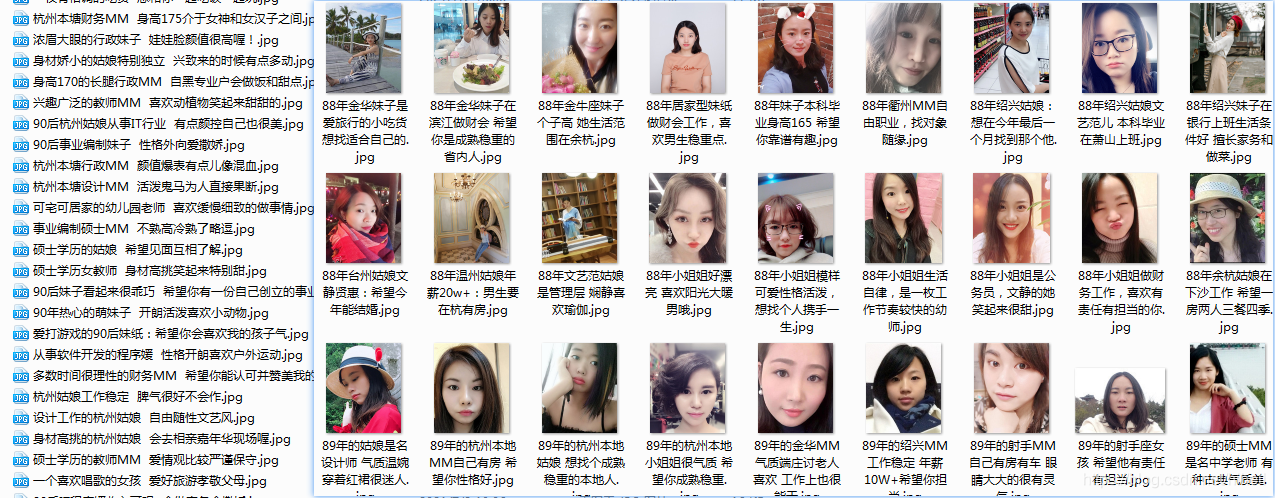
抓取结果展示时间
爬虫 120 例,第 11 例完成,希望本篇博客能带给你不一样的惊喜与知识。相关资料可以在下面直接获取。
完整代码下载地址:https://codechina.csdn.net/hihell/python120,NO11。
以下是爬取过程中产生的各种学习数据,如果只需要数据,可去下载频道下载~。
爬取资源仅供学习使用,侵权删。
抽奖时间
上篇博客获奖的朋友 ID 为 m0_59785054,抓紧联系橡皮哦。

评论数过 100,随机抽取一名幸运读者,
获取 29.9 元《Python 游戏世界》专栏 1 折购买券一份,只需 2.99 元。
今天是持续写作的第 174 / 200 天。可以关注我,点赞我、评论我、收藏我啦。
相关阅读
- 10 行代码集 2000 张美女图,Python 爬虫 120 例,再上征途
- 熊孩子说“你没看过奥特曼”,赶紧用 Python 学习一下,没想到
- 我用 Python 连夜离线了 100G 图片,只为了防止网站被消失
- 5000 张高清壁纸大图(手机用),用 Python 在法律的边缘又试探了一把
- 爬动漫“上瘾”之后,放弃午休,迫不及待的用 Python 薅了腾讯动漫的数据,啧啧啧
cs