Python爬虫实例――主页新闻爬取
本篇内容知识点:
1.from urllib.request import urlopen,Request
使用urllib库进行网页爬取
2.import pytts3
使用pytts3语音合成库对爬取内容进行语音播报
(WIN10以下系统可能需要下载相应的驱动文件并且对注册表写入相应内容)
3.from datetime import datetime
import time
获取时间戳
4.使用浏览器审查元素功能对网页进行分析
安装:
pip install pyttsx3
根据对搜狗主页 https://www.sogou.com/ 的页面进行的审查元素分析,可知在鼠标在第一次点击搜索框后会加载页面获取新闻内容
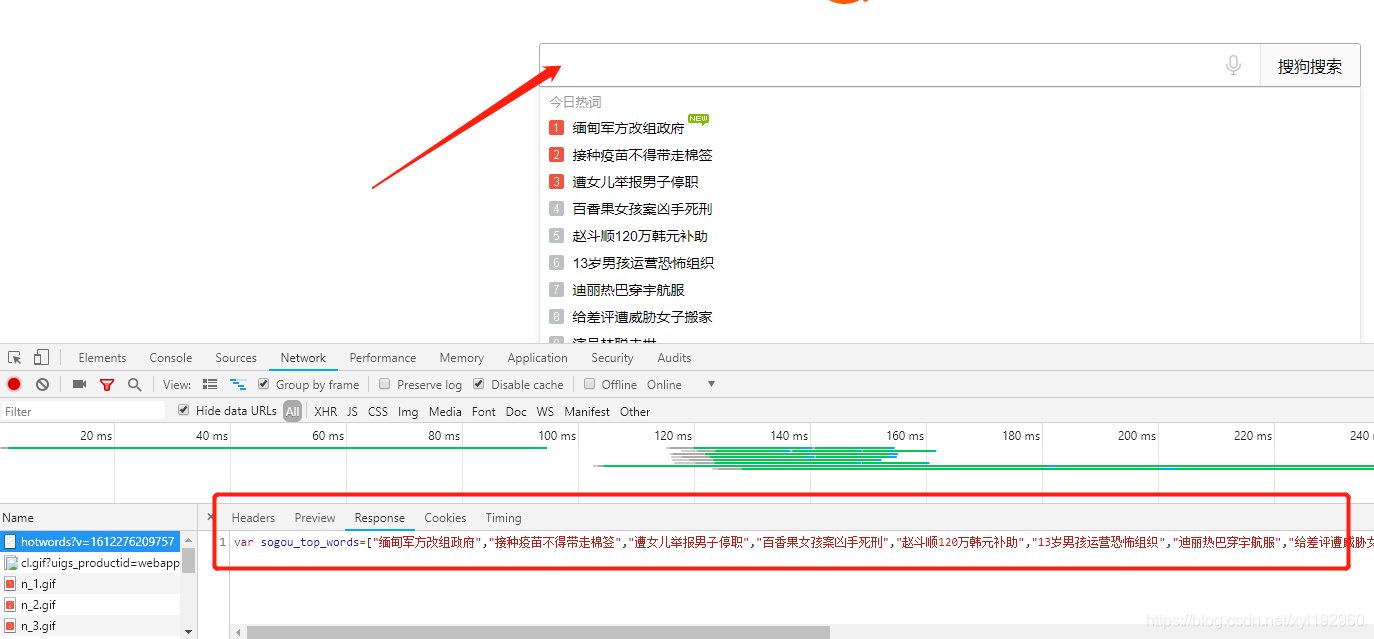
可以得到页面链接

可以看出https://www.sogou.com/suggnew/hotwords 是存放新闻内容的地址 ,v=1612276209757应该是一个时间戳,我们在用小工具对此时间戳进行验证,证实猜测是正确的

得到了我们的目标url就可以进行爬取了
因为多了时间戳的应用,可以继续在MyPyClass类中添加一个获取时间戳的函数,以方便以后使用
import random
from datetime import datetime
import time
def GetUserAgent():
'''从User-Agent列表中随机获得一个user-agent
return:返回一个str类型的user-agent
'''
ua_list = [
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/534.57.2 (KHTML, like Gecko) Version/5.1.7 Safari/534.57.2',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/30.0.1599.101 Safari/537.36',
'Mozilla/5.0 (Windows NT 5.1) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.84 Safari/535.11 SE 2.X MetaSr 1.0',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.122 UBrowser/4.0.3214.0 Safari/537.36'
]
return random.choice(ua_list)
def GetTimeStamp():
'''获得一个时间戳
return:返回一个时间对应时间戳的字典
'''
t = datetime.now().strftime('%Y-%m-%d %H:%M:%S.%f')
timeArray = datetime.strptime(t, "%Y-%m-%d %H:%M:%S.%f")
timeStamp = int(time.mktime(timeArray.timetuple()) * 1000.0 + timeArray.microsecond / 1000.0)
times={'time':timeArray,'timestamp':str(timeStamp)}
return times
from urllib.request import urlopen,Request
import pyttsx3
import MyPyClass
time_dict=MyPyClass.GetTimeStamp()
url='https://www.sogou.com/suggnew/hotwords?v='+time_dict['timestamp']
ua=MyPyClass.GetUserAgent()
request=Request(url,headers={'User-agent':ua})
response=urlopen(request)
content=response.read().decode('gbk').replace("var sogou_top_words=[",'').replace("];",'')
content_list=content.replace('"',"").split(',')
for index,new in enumerate(content_list):
print(index+1,new)
content=index+1,new
speak=pyttsx3.init()
speak.say(content)
speak.runAndWait()
print(url)
print(time_dict['time'])
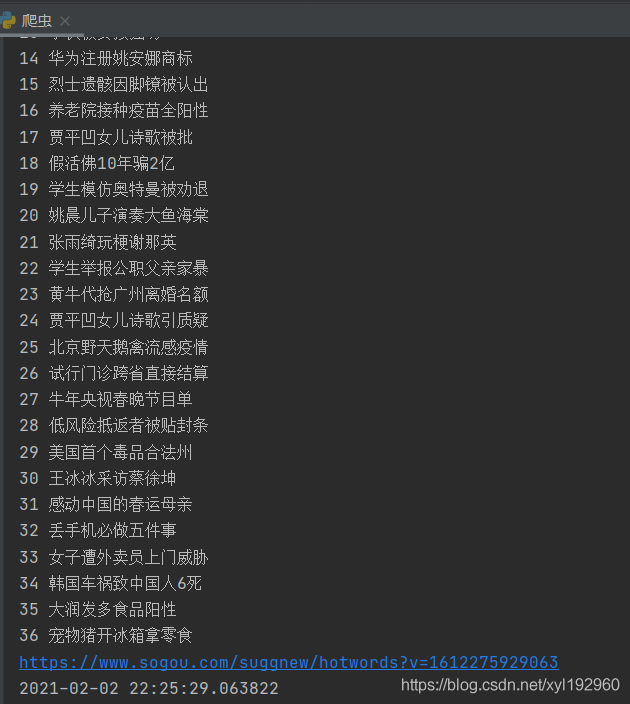
运行结果如图:
由于我们添加了pytts3语音合成库,在打印每一条新闻的时候还会进行语音播报
本篇内容仅供学习参考交流,有错误的地方请大家指正
cs