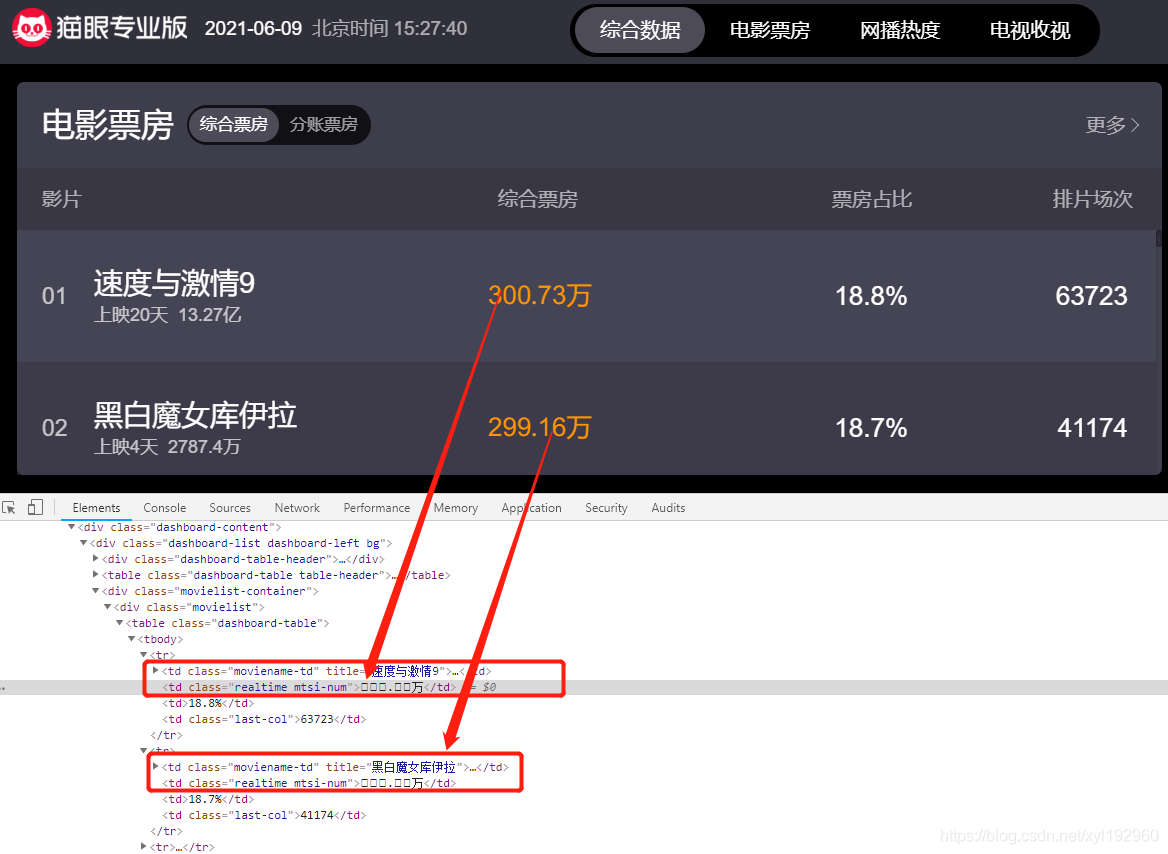
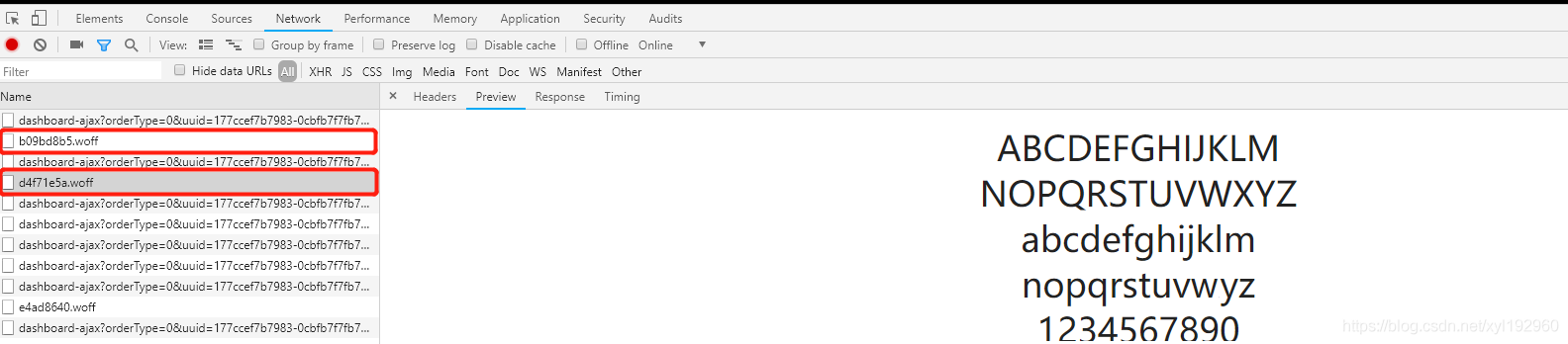
from fontTools.ttLib import TTFont
from xml.etree.ElementTree import parse
font=TTFont('4fd0b539.woff')
font.saveXml('maoyan.xml')
xml=parse('maoyan.xml')
root= xml.getroot()
for i in root:
if i.tag=='glyf':
dict_0 = {}
for j in i:
if j.get('name')=='glyph00000' or j.get('name')=='x':
continue
list_1 = []
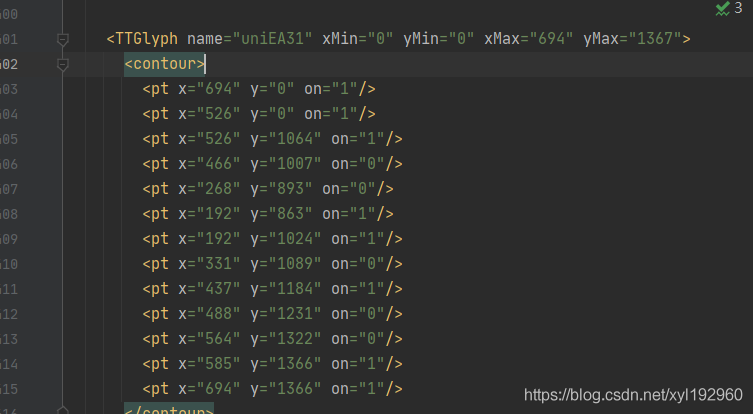
for k in j:
for l in k:
list_1.append(l.get('on'))
dict_0[j.get('name')]=list_1
print(dict_0)
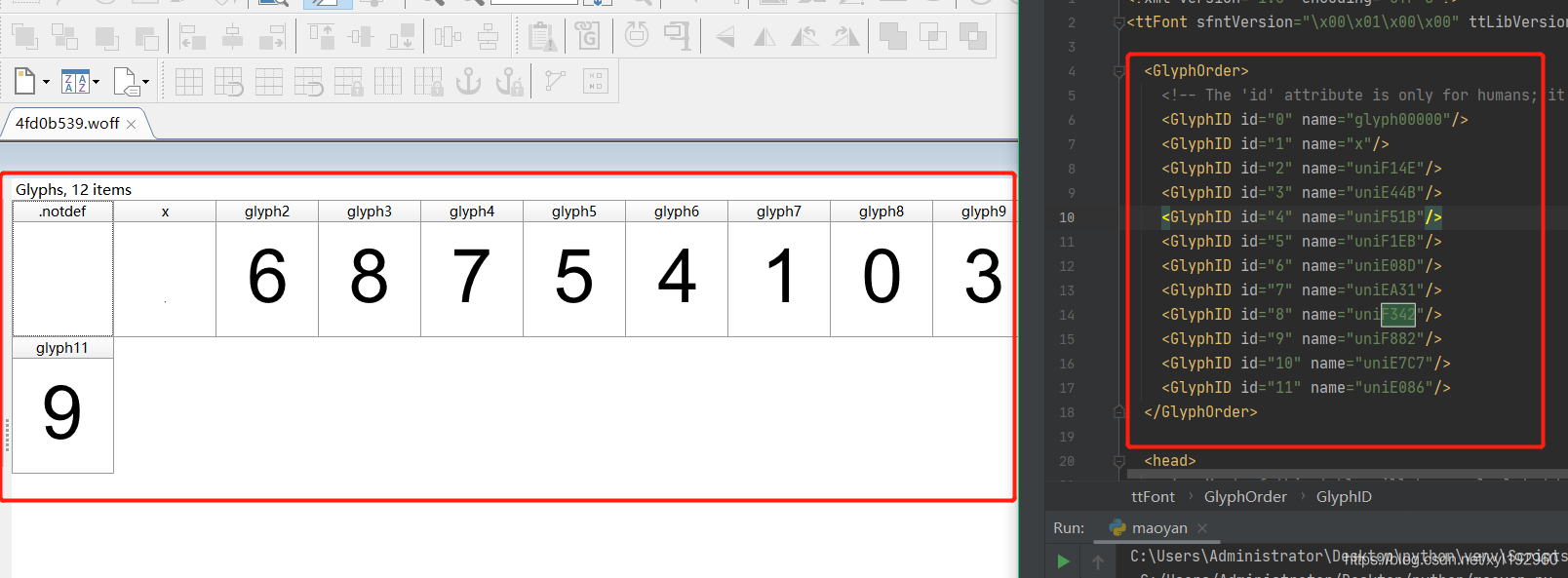
在通过High-Logic FontCreator软件上找到每个字形的代码可以得出on列表所对应的数字:
0: ['1', '0', '1', '0', '0', '1', '0', '1', '0', '1', '0', '1', '0', '0', '1', '0', '0', '1', '0', '1', '0', '1', '0', '0', '1', '0', '1', '0', '0', '1', '0', '0', '1', '0'],
1: ['1', '1', '1', '0', '0', '1', '1', '0', '1', '0', '0', '1', '1'],
2: ['1', '1', '1', '0', '1', '0', '0', '0', '0', '1', '0', '0', '1', '0', '0', '1', '0', '1', '0', '1', '0', '1', '1', '0', '0', '0', '0', '1', '0', '1', '0', '1', '0', '0', '1', '0', '0', '0', '0', '1'],
3: ['1', '0', '0', '1', '0', '0', '1', '0', '1', '0', '1', '0', '1', '1', '0', '0', '1', '0', '1', '0', '1', '0','1', '0', '1', '0', '0', '1', '1', '0', '1', '0', '1', '0', '1', '0', '0', '0', '0', '1', '0', '0', '1', '0','1', '0', '1', '0', '0', '1'],
4: ['1', '1', '1', '1', '1', '1', '1', '1', '1', '1', '1', '1', '1', '1'],
5: ['1', '0', '0', '1', '0', '1', '0', '0', '0', '1', '0', '0', '1', '1', '1', '1', '1', '1', '1', '0', '0', '1', '0', '1', '0', '1', '0', '1', '0', '1', '0', '1', '0', '1'],
6: ['1', '0', '1', '0', '1', '0', '1', '0', '1', '0', '0', '1', '0', '0', '1', '0', '0', '1', '0', '0', '0', '1','0', '0', '1', '0', '1', '0', '1', '0', '1', '0', '1', '1', '0', '1', '0', '0', '1', '0', '0', '1', '0', '1','0', '1', '0', '1', '0'