MyPyClass类
def GetRadarChart(values,features,bottom,top,title='多维雷达图',issave=False,savepath='./RadarChart.jpg',isshow=True):
'''获得一个多维雷达图
Parameters:
----------
values:list列表
用于存放int类型的多维雷达图数据
features:list列表
用于存放str类型对应每个数据的特征说明
bottom:float浮点
雷达图圆心位置的起始值即数据下限
top:float浮点
雷达图半径长度即数据上限
title:str字符串 可选
雷达图标题 默认为 '多维雷达图'
issave:bool布尔类型
是否需要保存 默认为 False
savapath:str字符串类型
保存路径 默认为 ./RadarChart.jpg
isshow:bool布尔类型
是否需要显示雷达图 默认为 True
'''
plt.rcParams['font.sans-serif'] = 'Microsoft YaHei'
plt.rcParams['axes.unicode_minus'] = False
plt.style.use('ggplot')
N = len((values))
angles = np.linspace(0, 2 * np.pi, N, endpoint=False)
angles = np.concatenate((angles, [angles[0]]))
attribute = np.concatenate((values, [values[0]]))
fig = plt.figure()
ax = fig.add_subplot(111, polar=True)
ax.set_thetagrids(angles[0:N] * 180 / np.pi, features)
ax.plot(angles, attribute, 'o-', linewidth=2, label=title)
ax.fill(angles, attribute, 'b', alpha=0.5)
ax.set_ylim(bottom, top)
plt.title(title)
ax.grid(True)
if issave:
plt.savefig(savepath)
if isshow:
plt.show()
主程序
import MyPyClass
import requests
import json
import os
from tqdm import tqdm
hero_list=[]
hero_infos=[]
url = 'https://game.gtimg.cn/images/lol/act/img/js/heroList/hero_list.js?v=06'
ua = MyPyClass.GetUserAgent()
with requests.get(url, headers={'User-agent': ua}) as response:
content = response.text
hero_list = json.loads(content)['hero']
for hero in hero_list:
hero_dict={
'name':hero['name'],
'id':hero['heroId'],
'attack':hero['attack'],
'magic':hero['magic'],
'defense':hero['defense'],
'difficulty':hero['difficulty']}
hero_infos.append(hero_dict)
for hero_info in hero_infos:
hero_name=hero_info['name']
hero_id=hero_info['id']
path='D:/LOL皮肤/'
if not os.path.exists(path):
os.mkdir(path)
if not os.path.exists(path+hero_name):
os.mkdir(path+hero_name)
os.chdir(path+ hero_name)
attribute = [int(hero_info['attack']), int(hero_info['magic']), int(hero_info['defense']), int(hero_info['difficulty'])]
attribute_name = ['物理攻击力', '魔法攻击力', '防御力', '操作难度']
MyPyClass.GetRadarChart(values=attribute, features=attribute_name, bottom=0, top=10, title=hero_name + '四维数据图', issave=True, isshow=False,savepath=path+hero_name+'/'+hero_name+'四维数据图.jpg')
hero_info_url='https://game.gtimg.cn/images/lol/act/img/js/hero/'+hero_id+'.js'
content=requests.get(hero_info_url).text
skin_infos=json.loads(content)['skins']
for skin_info in skin_infos:
if skin_info['mainImg']!="":
skin_name=skin_info['name']
skin_url=skin_info['mainImg']
img=requests.get(skin_url,stream=True)
if img.status_code==200:
if '/' in skin_name or ':' in skin_name or '\\' in skin_name or '\"' in skin_name:
skin_name=skin_name.replace('/','')
skin_name=skin_name.replace('\\','')
skin_name=skin_name.replace('\"','“')
skin_name = skin_name.replace(':', ':')
content_size = int(img.headers['Content-Length']) / 1024
with open(skin_name+'.jpg','wb') as f:
for data in tqdm(iterable=img.iter_content(1024),total=content_size,unit='b',desc='正在爬取 '+hero_name+'的皮肤 '+skin_name):
f.write(data)
print('Next')
效果如下

本篇内容仅供学习参考交流,有错误的地方请大家指正
cs

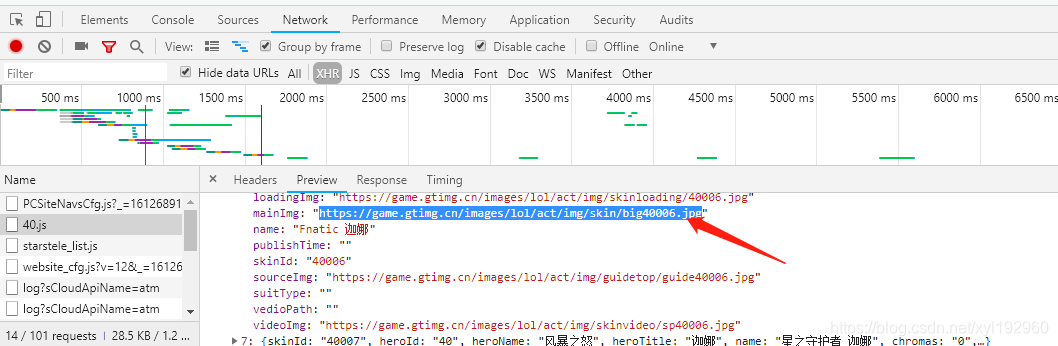
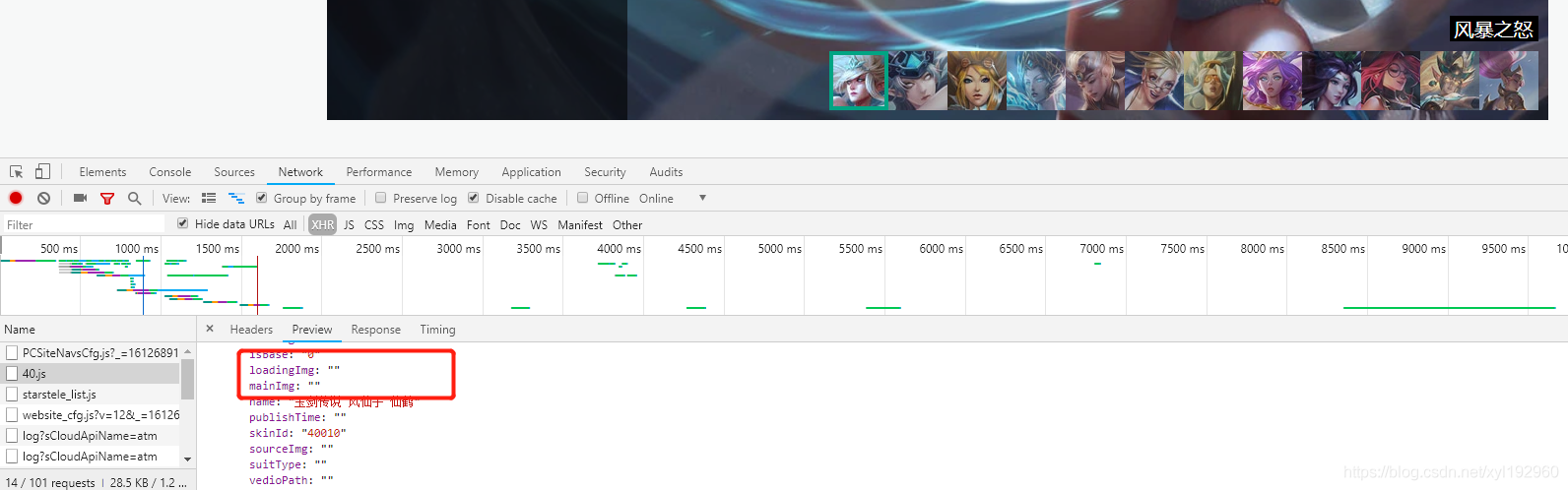
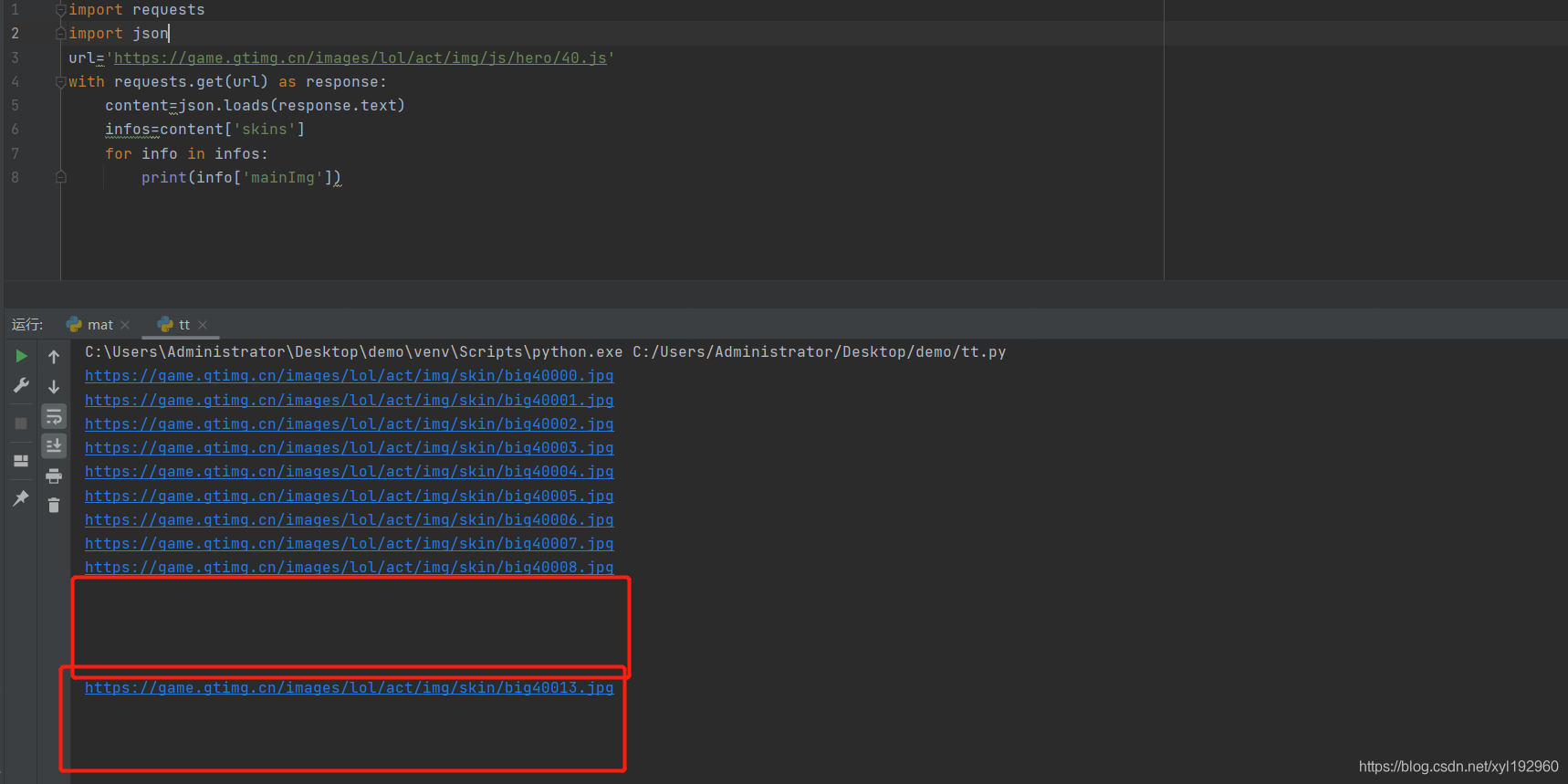 但是发现其中断开了,而且得到的地址也不一定是连续的,因此我们在对得到的数据进行分析,发现有些地方的mainImg为空字符,并且在单个英雄下面的skins皮肤列表中也并不都有这个皮肤,所以我们在正式爬取的时候应该对 mainImg 进行非空判断
但是发现其中断开了,而且得到的地址也不一定是连续的,因此我们在对得到的数据进行分析,发现有些地方的mainImg为空字符,并且在单个英雄下面的skins皮肤列表中也并不都有这个皮肤,所以我们在正式爬取的时候应该对 mainImg 进行非空判断