public boolean wordBreak(String s, List<String> wordDict) {
return dfs(s, wordDict, 0);
}
public boolean dfs(String s, List<String> wordDict, int start) {
if (start == s.length())
return true;
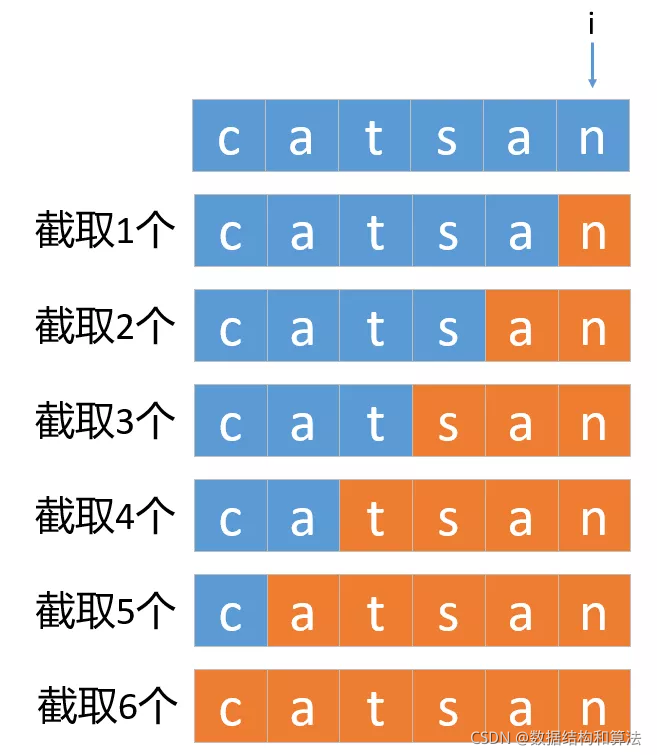
for (int i = start + 1; i <= s.length(); i++) {
if (!wordDict.contains(s.substring(start, i)))
continue;
if (dfs(s, wordDict, i))
return true;
}
return false;
}
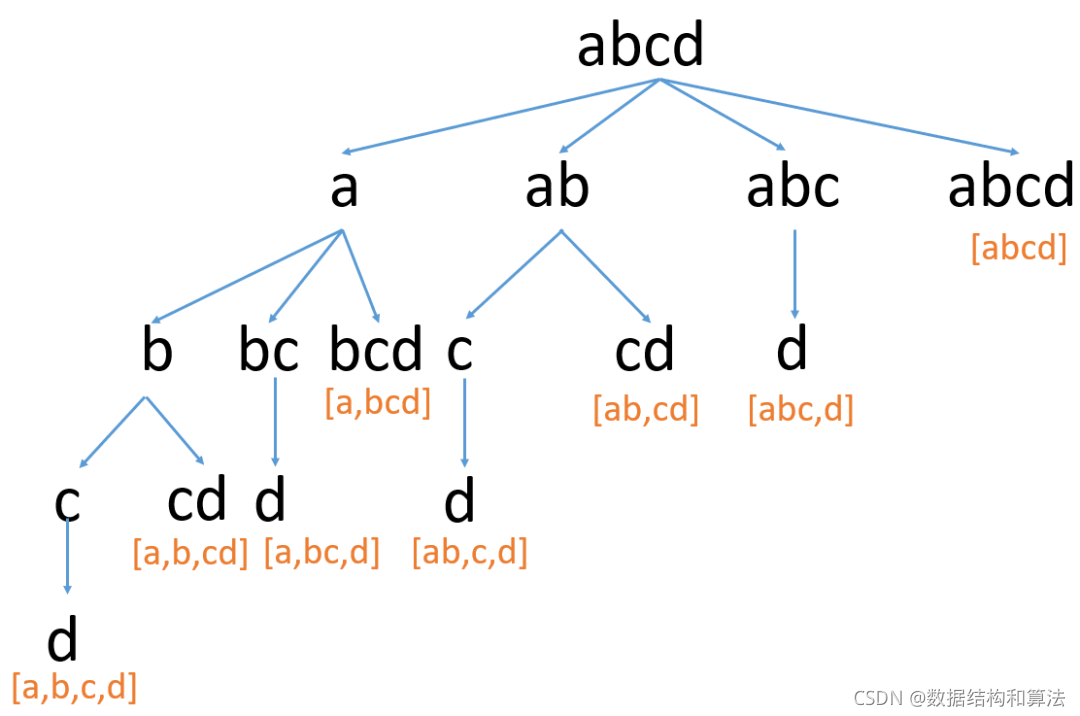
实际上上面代码运行效率很差,这是因为如果字符串s比较长的话,这里会包含大量的重复计算,我们还用上面的图来看下
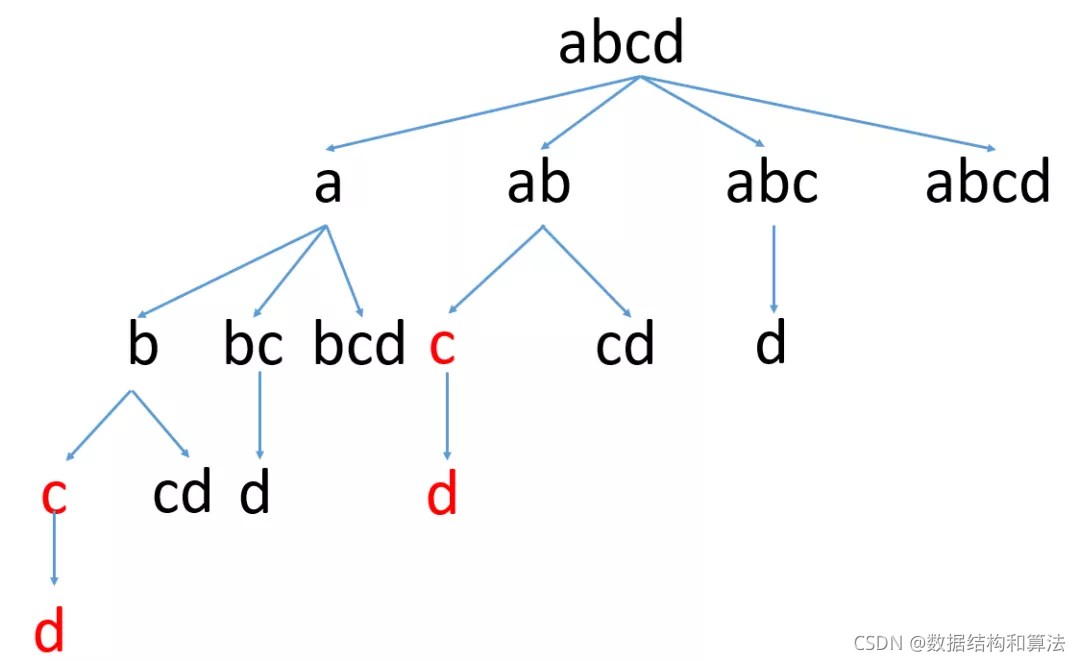
我们看到红色的就是重复计算,这里因为字符串比较短,不是很明显,当字符串比较长的时候,这里的重复计算非常多。我们可以使用一个变量,来记录计算过的位置,如果之前判断过,就不在重复判断,直接跳过即可,代码如下
public boolean wordBreak(String s, List<String> wordDict) {
return dfs(s, wordDict, new HashSet<>(), 0);
}
public boolean dfs(String s, List<String> wordDict, Set<Integer> indexSet, int start) {
if (start == s.length())
return true;
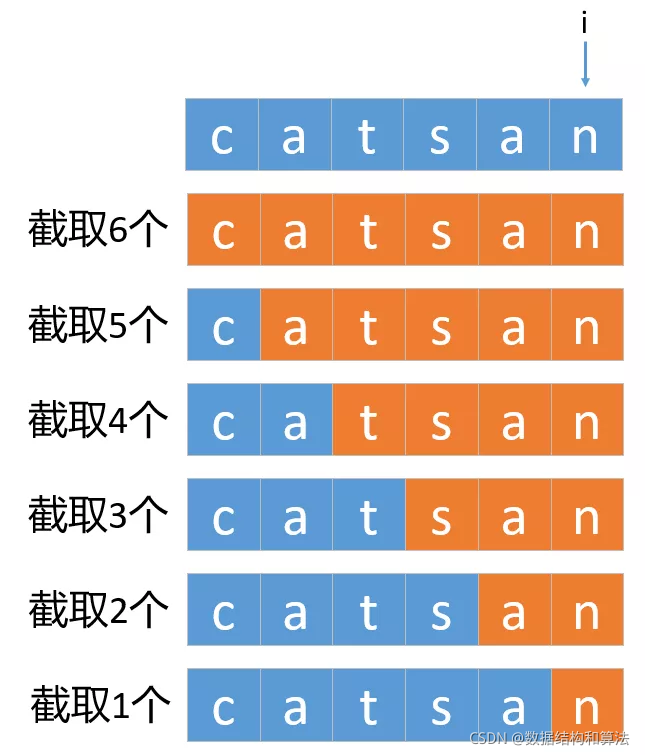
for (int i = start + 1; i <= s.length(); i++) {
if (indexSet.contains(i))
continue;
if (wordDict.contains(s.substring(start, i))) {
if (dfs(s, wordDict, indexSet, i))
return true;
indexSet.add(i);
}
}
return false;
}

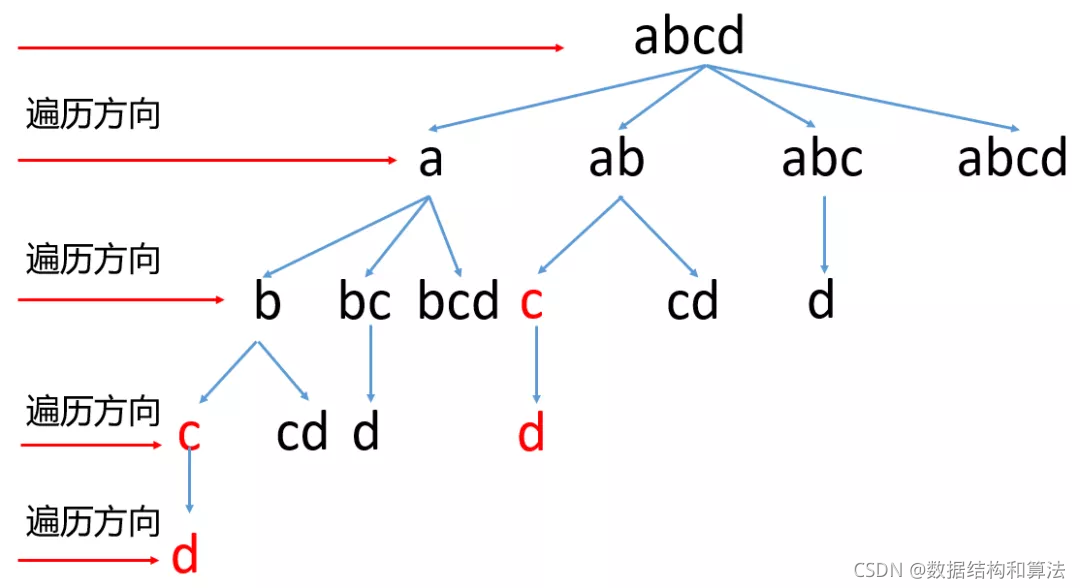
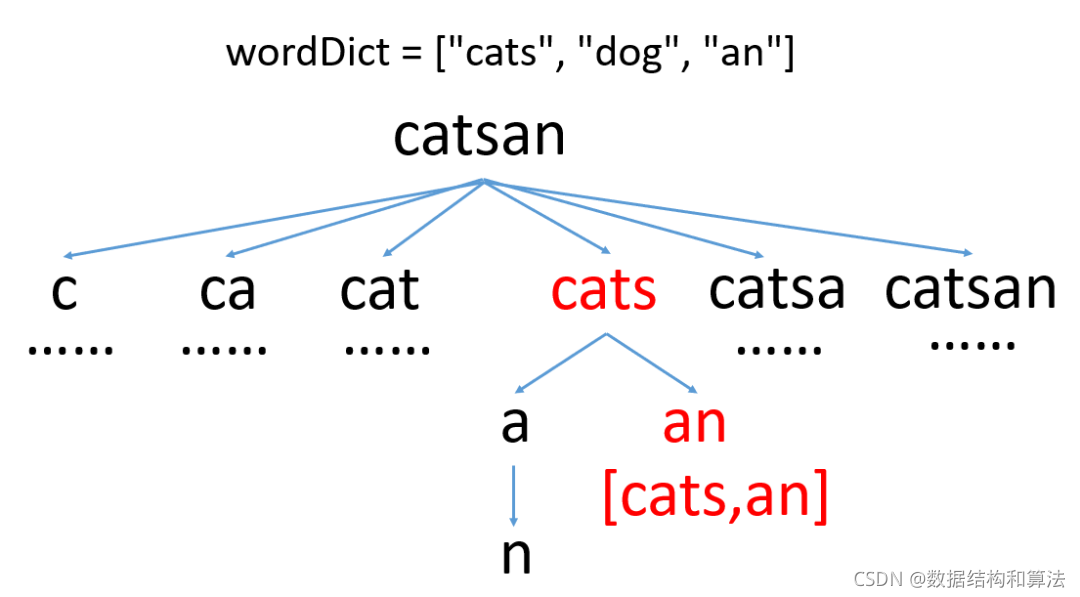
BFS一般不需要递归,只需要使用一个队列记录每一层需要记录的值即可。BFS中在截取的时候,如果截取的子串存在于字典中,我们就要记录截取的位置,到下一层的时候就从这个位置的下一个继续截取,来看下代码。
public boolean wordBreak(String s, List<String> wordDict) {
Set<String> setDict = new HashSet<>(wordDict);
Queue<Integer> queue = new LinkedList<>();
queue.add(0);
int length = s.length();
while (!queue.isEmpty()