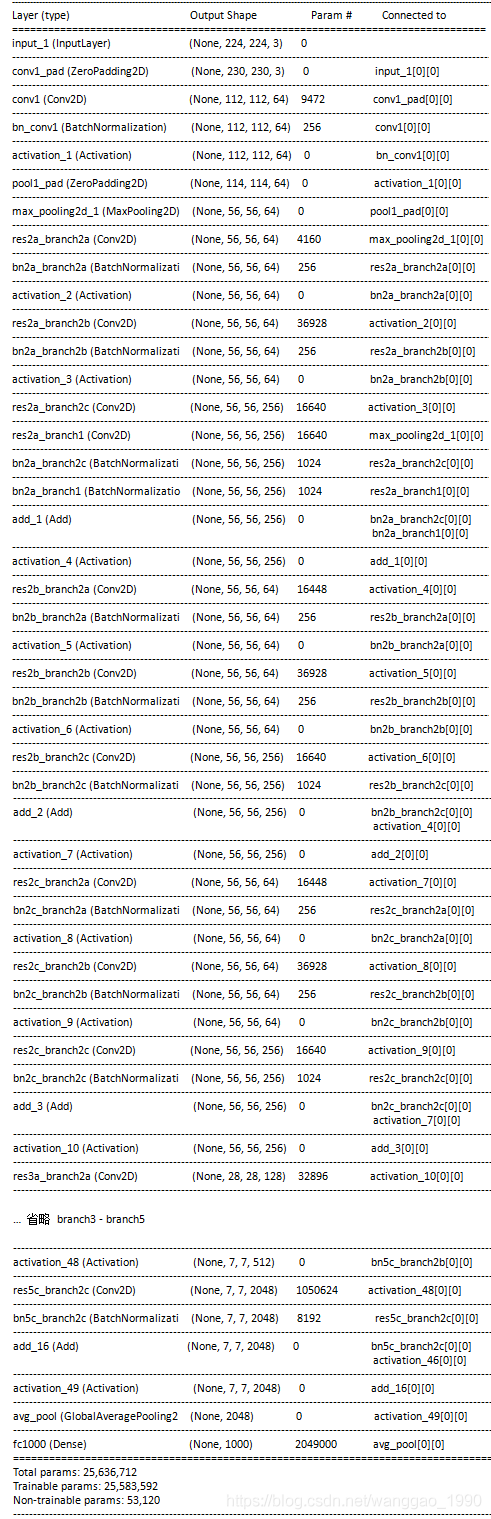
>>> f
<HDF5 file "resnet50_weights_tf_dim_ordering_tf_kernels_v2.h5" (mode r)>
>>> f.filename
'E:\\DeepLearning\\keras_test\\models\\resnet50_weights_tf_dim_ordering_tf_kernels_v2.h5'
>>> f.name
'/'
>>> f.attrs.keys()
<KeysViewHDF5 ['layer_names']>
>>> f.keys()
<KeysViewHDF5 ['activation_1', 'activation_10', 'activation_11', 'activation_12',
...,'activation_8', 'activation_9', 'avg_pool', 'bn2a_branch1', 'bn2a_branch2a',
...,'res5c_branch2a', 'res5c_branch2b', 'res5c_branch2c', 'zeropadding2d_1']>
>>> f.attrs['layer_names']
array([b'input_1', b'zeropadding2d_1', b'conv1', b'bn_conv1',
b'activation_1', b'maxpooling2d_1', b'res2a_branch2a',
..., b'res2a_branch1', b'bn2a_branch2c', b'bn2a_branch1',
b'merge_1', b'activation_47', b'res5c_branch2b', b'bn5c_branch2b',
..., b'activation_48', b'res5c_branch2c', b'bn5c_branch2c',
b'merge_16', b'activation_49', b'avg_pool', b'flatten_1', b'fc1000'],
dtype='|S15')
>>> f['input_1']
<HDF5 group "/input_1" (0 members)>
>>> f['input_1'].attrs.keys()
<KeysViewHDF5 ['weight_names']>
>>> f['input_1'].attrs['weight_names']
array([], dtype=float64)
>>> f['conv1']
<HDF5 group "/conv1" (2 members)>
>>> f['conv1'].attrs.keys()
<KeysViewHDF5 ['weight_names']>
>>> f['conv1'].attrs['weight_names']
array([b'conv1_W:0', b'conv1_b:0'], dtype='|S9')
从文件中读取具有权重数据的层的名字列表
layer_names = load_attributes_from_hdf5_group(f, 'layer_names')
filtered_layer_names = []
for name in layer_names:
g = f[name]
weight_names = load_attributes_from_hdf5_group(g, 'weight_names')
if weight_names:
filtered_layer_names.append(name)
layer_names = filtered_layer_names
if len(layer_names) != len(filtered_layers):
raise ValueError('You are trying to load a weight file '
'containing ' + str(len(layer_names)) +
' layers into a model with ' +
str(len(filtered_layers)) + ' layers.')
3、从hdf5文件中读取的权重数据、和keras模型层tf.Variable打包对应
先看一下权重数据、层的权重变量(Tensor tf.Variable)对象,以conv1为例
>>> f['conv1']['conv1_W:0']
<HDF5 dataset "conv1_W:0": shape (7, 7, 3, 64), type "<f4">
>>> f['conv1']['conv1_W:0'].value
array([[[[ 2.82526277e-02, -1.18737184e-02, 1.51488732e-03, ...,
-1.07003953e-02, -5.27982824e-02, -1.36667420e-03],
[ 5.86827798e-03, 5.04415408e-02, 3.46324709e-03, ...,
1.01423981e-02, 1.39493728e-02, 1.67549420e-02],
[-2.44090753e-03, -4.86173332e-02, 2.69966386e-03, ...,
-3.44439060e-04, 3.48098315e-02, 6.28910400e-03]],
[[ 1.81872323e-02, -7.20698107e-03, 4.80302610e-03, ...,
…. ]]]])
>>> conv1_w = np.asarray(f['conv1']['conv1_W:0'])
>>> conv1_w.shape
(7, 7, 3, 64)
>>> filtered_layers[0]
<keras.layers.convolutional.Conv2D object at 0x000001F7487C0E10>
>>> filtered_layers[0].name
'conv1'
>>> filtered_layers[0].input
<tf.Tensor 'conv1_pad/Pad:0' shape=(?, 230, 230, 3) dtype=float32>
>>> filtered_layers[0].weights
[<tf.Variable 'conv1/kernel:0' shape=(7, 7,