HTTP/2 是 HTTP 协议自 1999 年 HTTP 1.1 的改进版 RFC 2616 发布后的首个更新,前身是 SPDY 协议(Google),于 2015 年 2 月 17 日被批准。
HTTP/2 标准于 2015 年 5 月以 RFC 7540 正式发表,多数主流浏览器已经在 2015 年底支持了该协议。目前国内外大多数网站也都已经支持了 HTTP/2,比如 Google/Stackoverflow/Reddit,国内的 淘宝 / Segmentfault / 掘金 / CSDN / 博客园 / 36Kr 等等都已经全面支持了 HTTP/2 协议
HTTP/2 相比 HTTP/1 来说,主要是性能上的大幅提升,而且完全没有没有改动 HTTP/1 协议中的应用语义。 Method、State Code、URI 和 Header 等核心概念完全没有变化
下面详细介绍 HTTP/2 中的一些关键升级点
二进制的分层(Binary Framing Layer)
Binary Framing Layer 的设计,算是 HTTP/2 性能提升的核心了。HTTP/2 中在应用层又设计了一套 BinaryFrame Layer,它定义了 HTTP 消息在传输过程中的封装方式。不过这个 Frame Layer 和 TCP 的 Packet 可不是一回事,这个 Frame Layer 只是逻辑上的分层,在 HTTP 和 TCP 层之间,类似于 Http Chunk
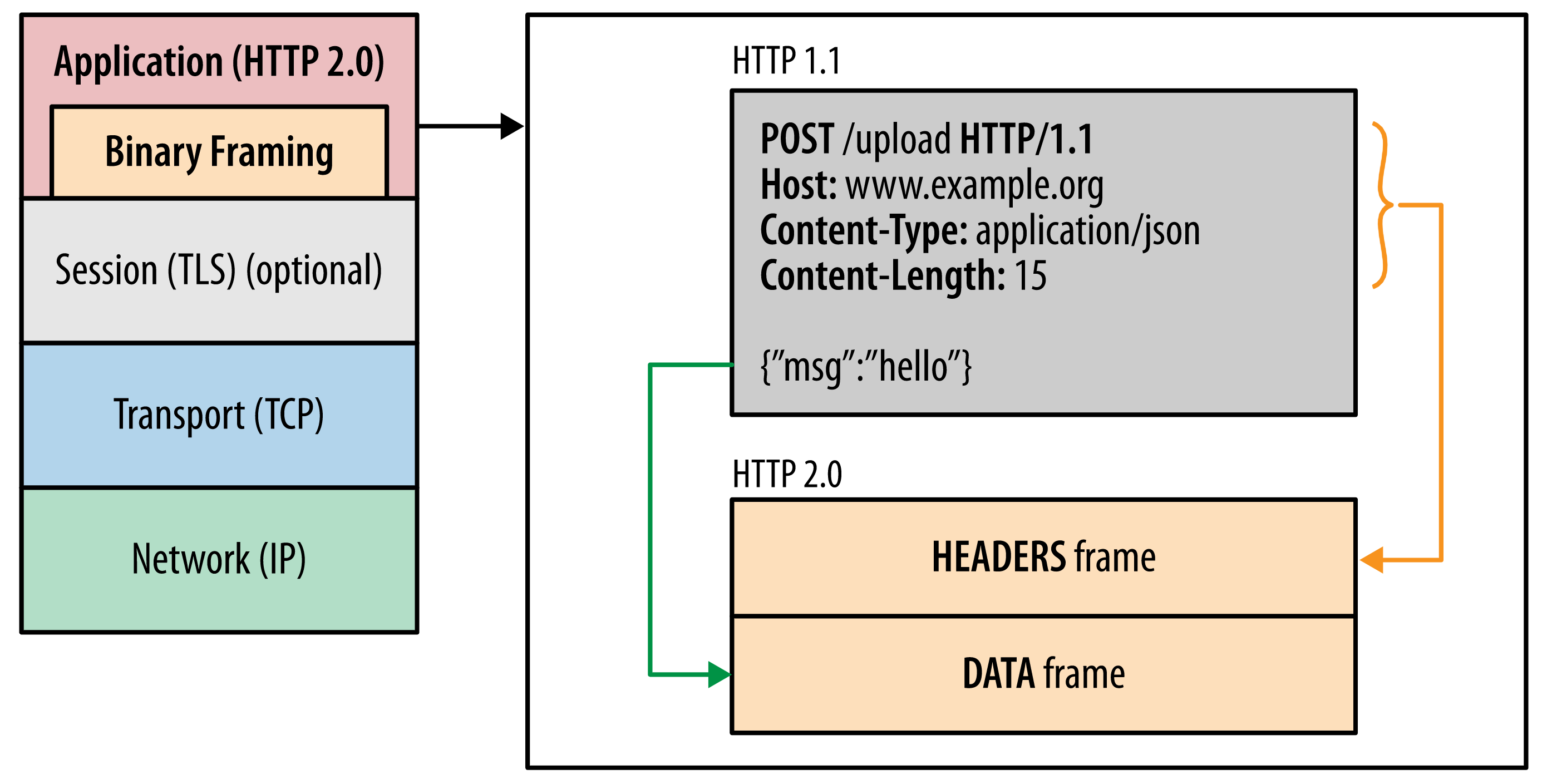
如上图所示,HTTP/2 中的报文,在传输前都会被先构建成一个个的帧(Frame),每次 Socket 发送的最小单位是一个帧,每个帧都以二进制格式进行编码
二进制格式编码(Binary format encode)
在 HTTP/1 中,数据都是以文本编码的模式进行传输的。那么什么叫文本编码,什么叫二进制编码呢?
举个例子,协议中有一个长度的首部值为 11 ,这个数字在文本编码中(用字符串来表示),它会占用 2 个 Byte,对应的字节为[49, 49],那么在二进制编码下,11如果是 Unsigned Int 类型,那么它会占用 4 个 Byte,对应的字节为[0, 0, 0, 11] 。
上面这个例子,看起来二进制编码下占用更大了;其实大多数情况下,二进制编码的占用会更低。如果换个大点的数字2147483647,在文本编码下需要占用 10 个 Byte,可二进制编码下还是只需要占用 4 个 Byte
| 文本编码(Byte Array) | 二进制编码(Byte Array) |
|---|
| 11 | [49, 49] | [0, 0, 0, 11] |
| 2147483647 | [50, 49, 52, 55, 52, 56, 51, 54, 52, 55] | [127, -1, -1, -1] |
二进制格式这个叫法虽然比较容易引起歧义,不过大家都这么叫,那就是对的
不过既然都用二进制编码了,那么还能叫**超文本传输(HyperText Transfer )**吗……
比如在 HTTP/1 中,有一个 Chunk 编码,和上面提到的 Binary Framing Layer 有些相似,都是在 TCP 之上加了一层逻辑层。Chunk 编码中有一个 Length 字段,就是用文本编码的,但 Binary Framing 中的长度和其他字段都是用二进制编码,所以这也是 HTTP/2 新增的逻辑层叫 Binary Framing 的原因吧
二进制格式虽然占用更小,但不像文本编码那种直观,易于调试,肉眼很难直接看出数据的内容
流 / 消息 / 帧(Stream/Message/Frame)
- Stream - 流,已建立的双向字节流,是一条逻辑的链路,对应一次 HTTP 交互的完整请求和响应
- Message - 消息,一次 HTTP 的请求消息,或者响应消息;一次请求 - 响应的交互报文,属于一个 Stream
- Frame - 帧,HTTP/2 传输的最小单位,每个帧包含帧首部,首部中会包含所属流的 ID,一个 Message 会被分成多个 Frame 进行传输,所属不同 Stream 的 Frame 可以交错发送,对端收到交错的 Frame 后再根据 Stream 进行组装
在 HTTP/2 中,(同源的)所有的通信都会在一个单一的 TCP 连接上执行,该连接可以传输任意数量的 Stream
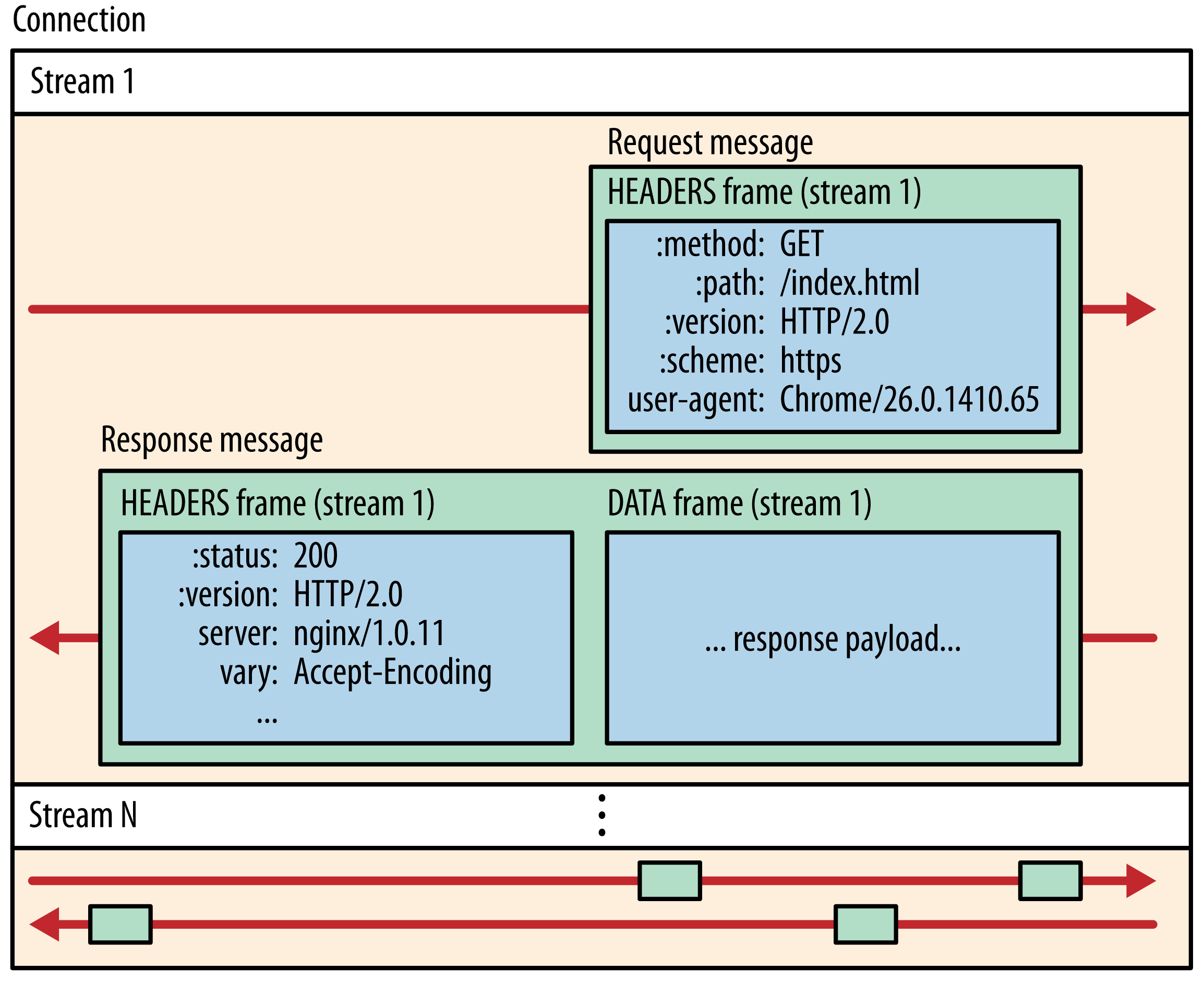
如上图所示:一条 TCP 连接,可以承载多条 Stream,一条 Stream 包含一次完整的请求和响应消息,请求和响应消息又会被拆分为多个 Binary Frame 进行传输
多路复用
HTTP/2 中的多路复用,和 I/O 多路复用(I/O Multiplexing)可不是一回事。I/O 多路复用指的是同一个进程监听多个 Sock 事件,而 HTTP/2 中的多路复用是指在一条 TCP 连接上同时进行多个请求和响应消息的传输。
**
在 HTTP/1 中,如果想并行的发送多个请求,那么需要建立多条 TCP 连接,每个连接同时只能处理一个请求;而且当 TCP 连接过多时,还会造成 TCP 的排队
HTTP/2 中新的 Binary Frame Layer 的设计解决了这个弊端,客户端和 服务器可以把 多条并行的 HTTP 消息分解为互不依赖的 Frame(如下图所示),然后交错发送,最后对端会把这些交错的 Frame 按 Stream 分组重新组合起来
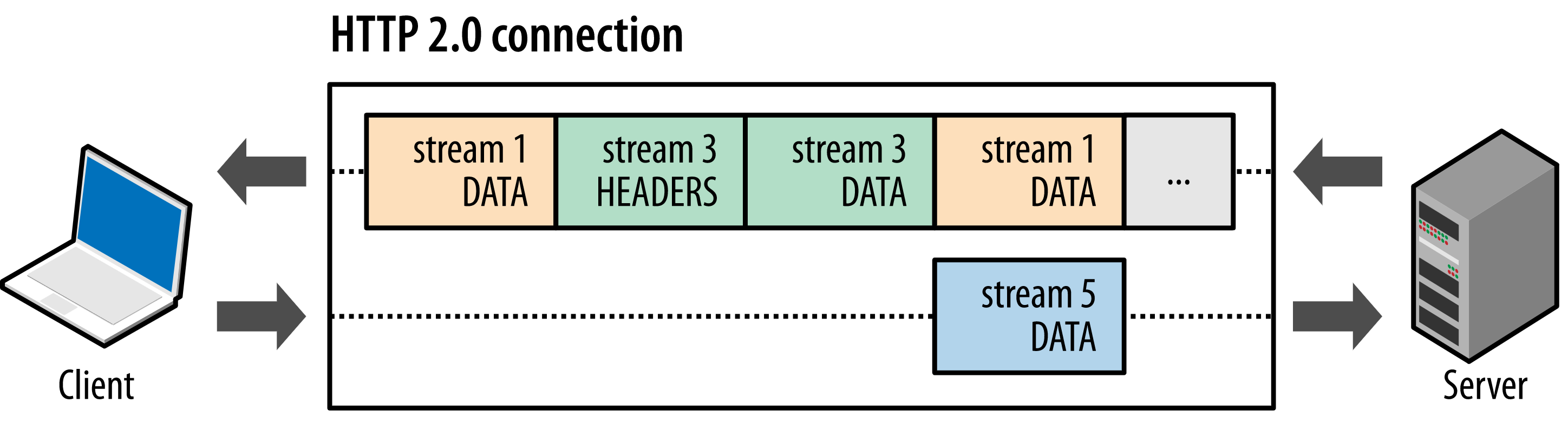
上图中包含了一个连接上多个传输中的 Stream:Client 正在向服务端发送 Stream5 的 Data Frame,同时 Server 也在向 Client 交错发送 Stream1 和 Stream3 的 Frame,在这条 TCP 连接上有 3 个请求 / 响应的数据进行交互
多路复用是 HTTP/2 性能提升的核心,这种方案的优势主要在于以下几点:
- 并行处理多个请求 / 响应,不会发生应用层面的阻塞
- 使用单个 TCP 连接,大幅减少资源占用
这里可能会有一个疑问,换成单个 TCP 连接真的会更快吗?
其实不绝对,HTTP/1 中浏览器一般会限制单个域名的连接数。比如 Chrome 会限制单个域名连接数上限为 6 个(历史数据,不保证准确,可能不同版本有所差异),如果在带宽足够,负载也不高时,同时下载的文件在 6 个以内时,单连接和多连接速度没什么区别。
不过如果同时下载的文件超过 6 个时,超出 6 个的那些下载就需要排队等待,这个时候就有区别了,HTTP/1 中的连接模型会导致排队,而 HTTP/2 不会
针对上述问题也有一些解决方案,比如说 Domain Sharding,将静态资源分别部署至多个域名站点,这样就可以一定程度上绕过浏览器的连接限制;或者时拼接静态资源,将多个静态资源文件合并至一个,降低连接数的占用
而 HTTP/2 中,根本就不用考虑连接数的限制,因为它对同源的下载只会使用一个 TCP 连接,自然也就没什么连接限制的概念了。
不过这里可能会思考一个问题,多个请求的数据在单个 TCP 连接中传输时,会发生阻塞或者排队吗?
其实不会,TCP 滑动窗口大小的上限是 65535,足够跑满你的带宽。不过在网络环境极其差的时候,还是会有些影响的,毕竟收到 ACK 太慢或丢包,不过这种情况下单连接和多连接都一样有问题;但在网络情况良好时,单连接省去了额外的建立连接的开销,而且在 TCP 的 Slow Start 的机制下,连接刚建立时滑动窗口的大小是比较小的,传输报文的速率会有所降低;不过在 HTTP/2 下,由于只有一条连接,且多个请求的报文可以交错发送不用等待,上述的缺点都可以避免了。
总结一下,HTTP/2 的多路复用机制并不是在所有场景下都能够提升性能,只是在浏览器同时加载过多文件时才会大幅提升性能,并行的请求越多 HTTP/2 和 HTTP/1 的差异会越明显,如果只是下载单个文件,这个多路复用并不能带来什么提升
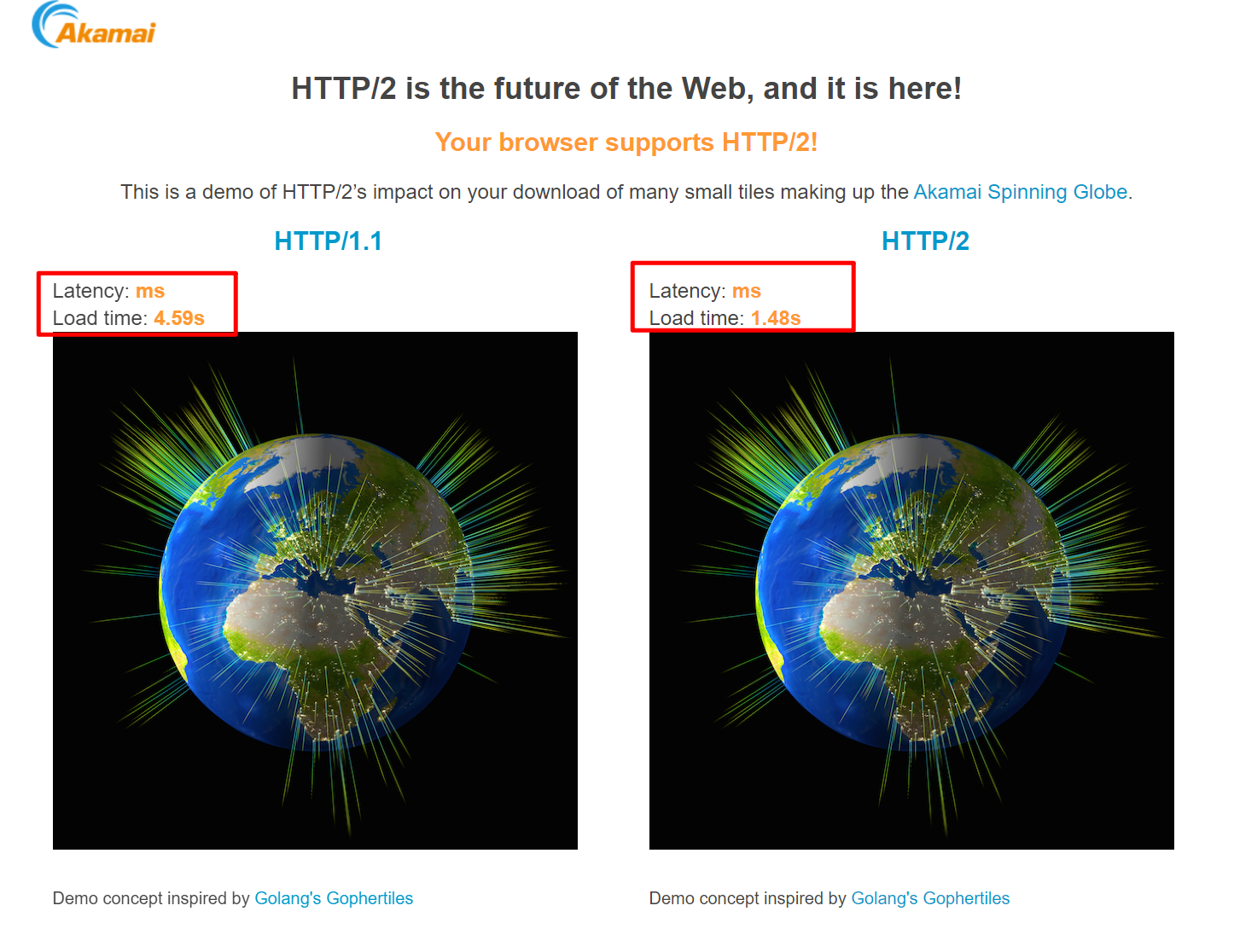
这个网站,提供了一个 HTTP/2 和 HTTP/1 在同时加载多个资源时的速度差异:https://http2.akamai.com/demo,这个网页中同时下载 400 个小图片,可以看到 HTTP2 的加载速度远超 HTTP/1
不过 HTTP/2 的优化可不止连接复用,还有首部压缩,流量控制等
首部压缩(Header Compression)
在 HTTP/1 中,报文中的 Header 时通过文本形式编码的,就像下面这样:
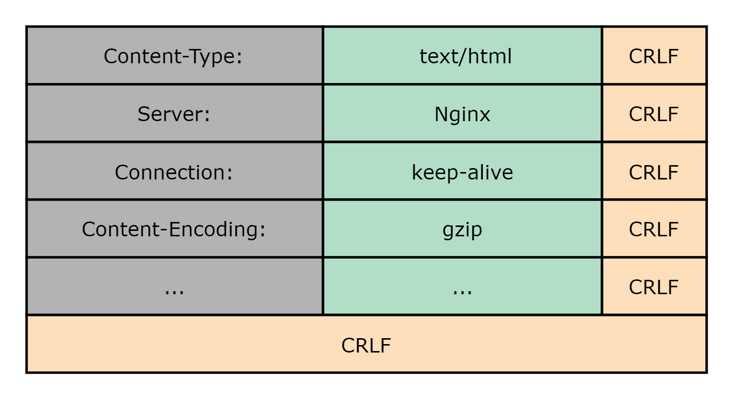
每个 header name 都会跟一个冒号,然后时一个可选的空格,每个 header 以 CRLF 结尾,最后还会保留一个空行作为 header 部分的结束标识
这些 header 每次传输会增加 500-800 字节的开销,如果算上 HTTP cookie 的化,甚至会增加上千个字节开销。为了减少此开销,HTTP/2 使用 HPACK 压缩格式压缩请求和响应 Header 数据:
- 通过静态霍夫曼编码(Huffman code)对发送的 Header 进行编码,降低 Header 的大小
- 要求客户端和服务器都维护和更新以前看到的 Header 的索引列表,然后将该列表用作有效编码先前传输的值的参考
客户端和服务端都会建立一个 Header 索引表,里面包含已经发送或接收的 header,当再次发送 header 数据时会先从这个 header 索引表中查找,如果找到就用特殊值替换这个重复 header,这样降低了重复值的占用,减小了报文大小
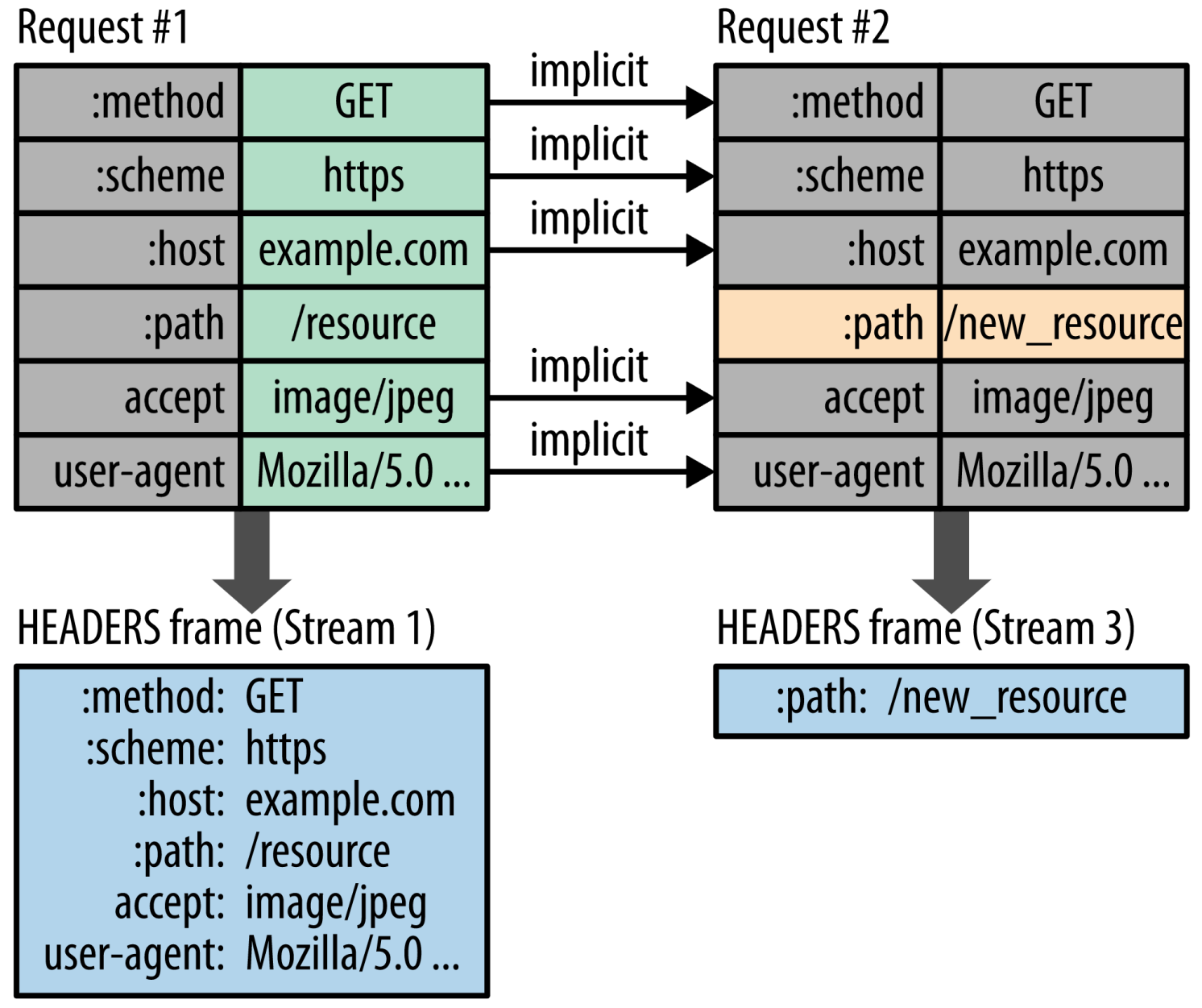
如上图所示,Request 1 和 Request 2 的 header 只有一个: path 不同,那么在发送 Request 2 时其他只有: path 需要完整编码发送,其他 header 替换成对应重复的索引即可
光说
总结
HTTP/2 性能提升的关键,主要在于新的二进制分层配合多路复用设计,降低了连接数的占用,浏览器环境下提升会比较明显
早期的域名域名分片(Domain Sharding),资源文件合并(Bundle resources )这种针对 HTTP/1 的优化策略,在 HTTP/2 下也完全不需要了;如果升级到 HTTP/2,前端的一些构建工具最好也将构建策略调整一下,单域名 + 多文件会更适合 HTTP/2。
不过对于一些纯服务端环境下,比如服务端调用三方系统的 HTTP 接口,不会有什么连接数的限制,但是单连接下还是可以降低建立连接的开销
加上 HTTP/2 的 Header 压缩,降低了 HTTP 的报文大小,进一步的提升了 HTTP/2 的性能
参考
- https://hpbn.co/http2/
- https://httpwg.org/specs/rfc7…
- https://tools.ietf.org/html/r…
- https://netty.io/4.1/xref/io/…
原创不易,转载请在开头著名文章来源和作者。如果我的文章对您有帮助,请点赞收藏鼓励支持。
cs