平台:pycharm
目标:爬取豆瓣网页电影名称,评分等信息,并存储存在csv文件中
代码(代码中的url和headers获取方法在下)
import re
import requests
import csv
url = "https://movie.douban.com/chart"
headers = {"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114 Safari/537.36"}
resq = requests.get(url=url,headers = headers)
page_content = resq.text
obj = re.compile(r' <table width="100%" class="">.*?title="(?P<name>.*?)">'
r'.*?<span class="rating_nums">(?P<grade>.*?)</span>'
r'.*?<span class="pl">(?P<review>.*?)</span>',re.S)
res = obj.finditer(page_content)
f = open("data.csv",mode="w")
csvwriter = csv.writer(f)
for it in res:
dic = it.groupdict()
csvwriter.writerow(dic.values())
f.close()
resq.close()
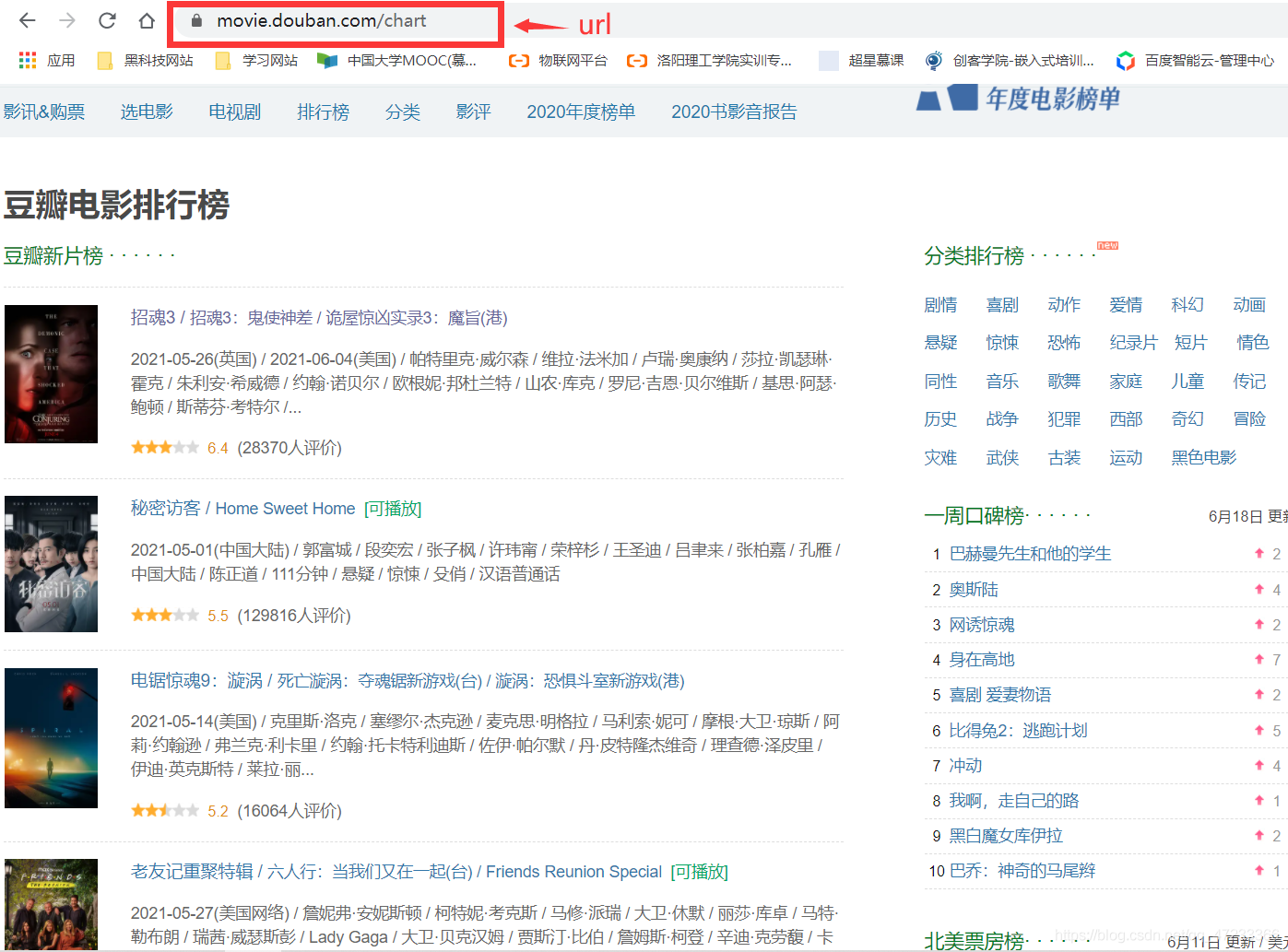
1、首先、随便找一个豆瓣网页,获取其url,如图
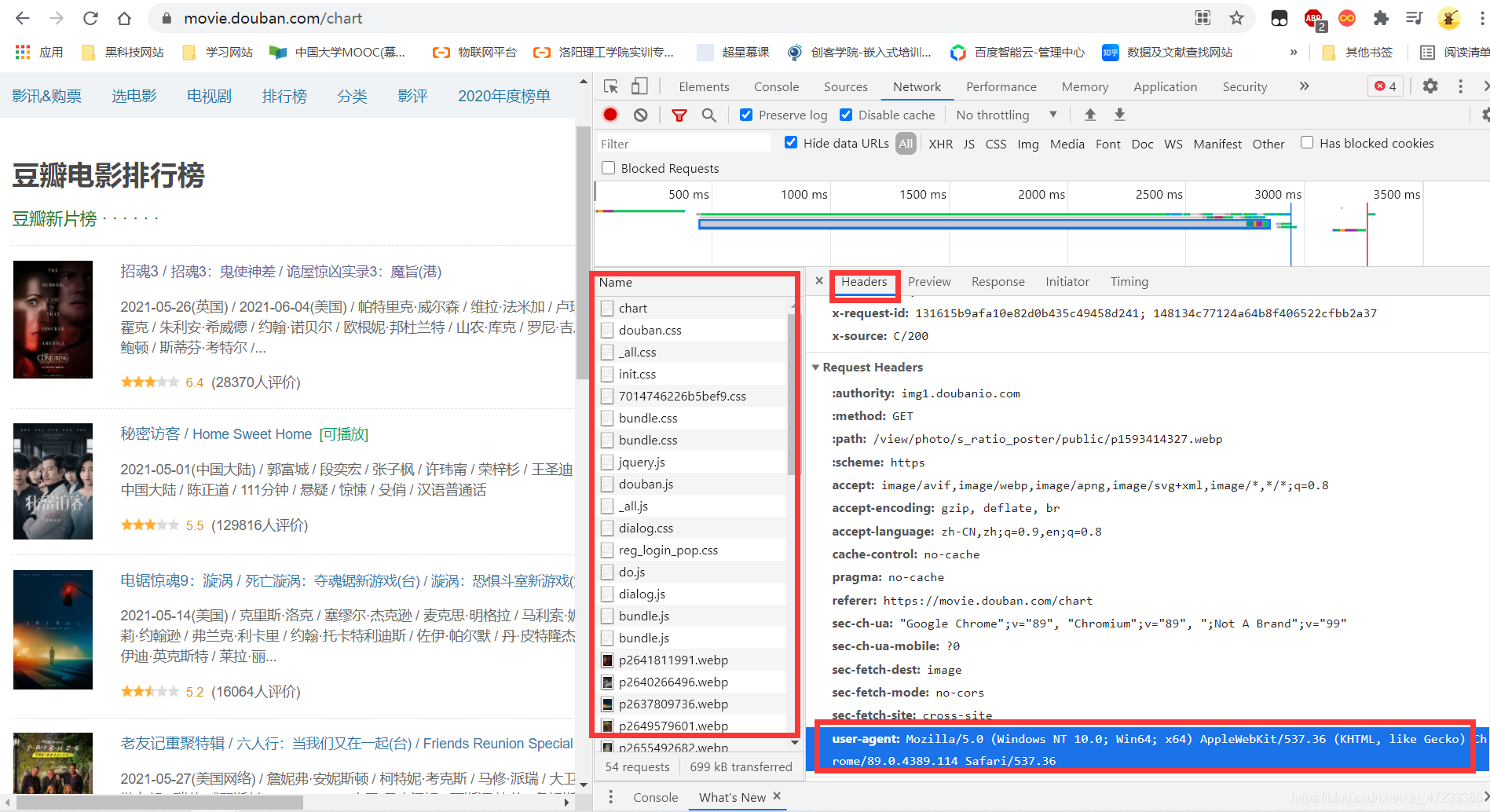
2、拿到请求头中的user-agent,步骤如下:
ctrl+shift+I或右键检测(谷歌浏览器)导出检查界面,点击Network,先刷新一下网页,在Name栏会显示许多信息,随意点击一个,之后在Headers内下滑找到user-agent,复制其内容至代码的headers。具体如图所示:
3、之后通过查看网页源代码使用正则表达式对需要的信息进行获取(正则表达式不明白的可查阅相关资料)
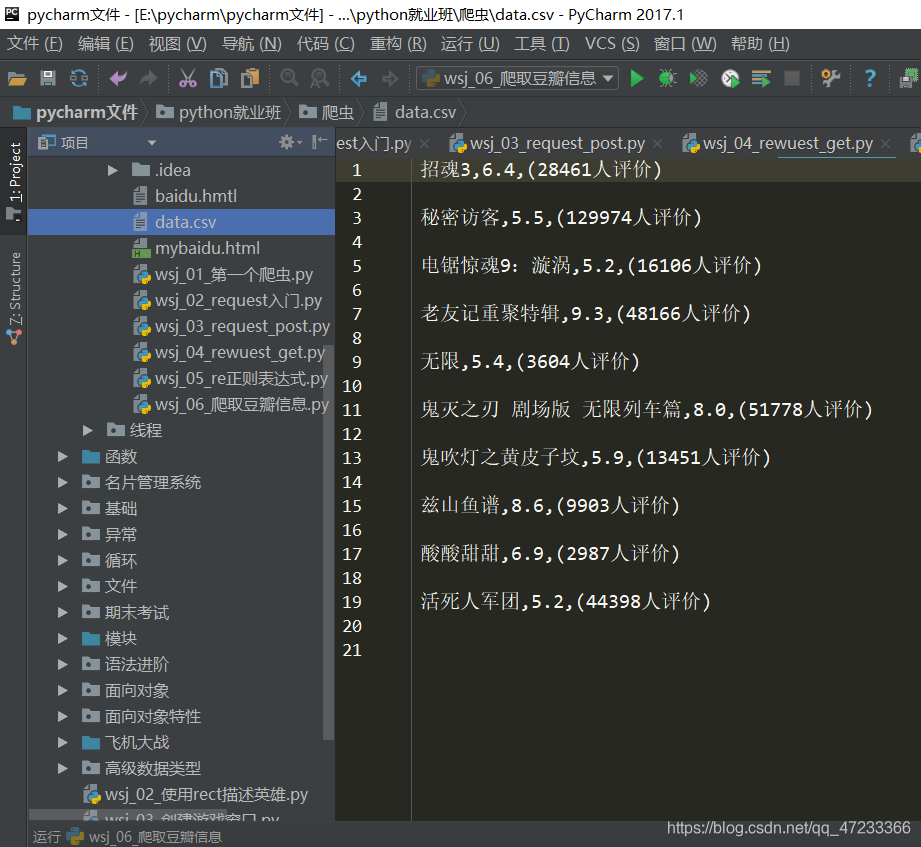
4、将文件存储在CSV文件中
最终csv文件内容
cs