Spliterator是java8新增的接口,意思为分割器或者分离器,作用是遍历元素或者将数据源的数据分割成几个部分。
Spliterator的实现类非常多,这也体现了该接口的重要性。下图Stream中比较重要的几个类的继承体系:
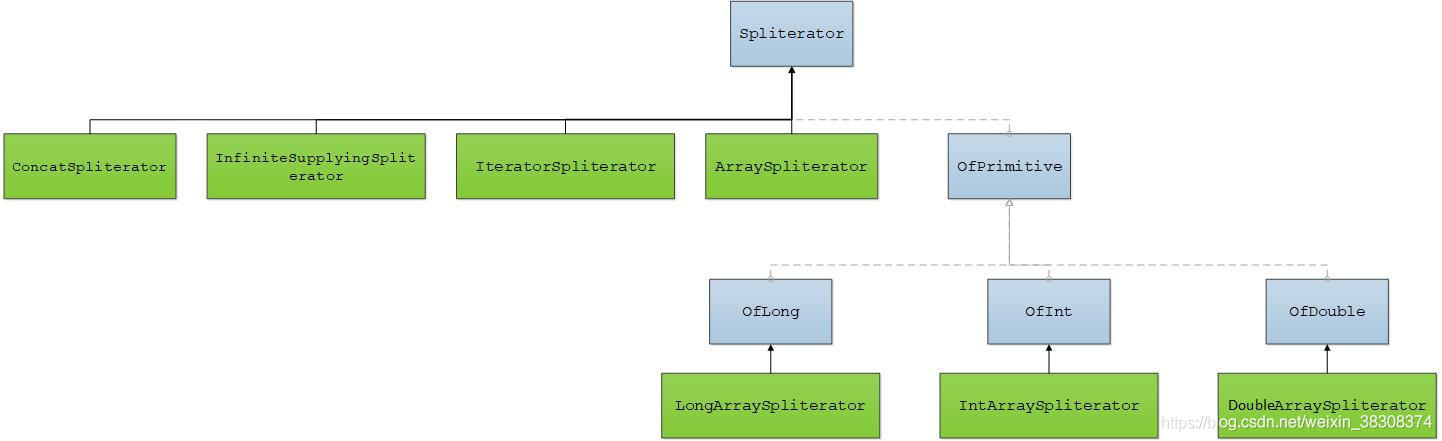
绿框表示实现类,蓝框表示接口。
因为Integer、Long、Double比较特殊且常用,所以单独提供了Spliterator的实现类,不过原理与类ArraySpliterator都是一样的。
上图中Spliterator的直接实现类分为四个,主要原因是它们的数据源不同。
- ArraySpliterator:数据源为数组;
- IteratorSpliterator:数据源为迭代器;
- ConcatSpliterator:数据源为Spliterator,该类的作用是将两个Spliterator拼接成一个Spliterator;
- InfiniteSupplyingSpliterator:数据源为生成函数。
除了上面这些实现类之外,java8还提供了工具类Spliterators,ArraySpliterator和IteratorSpliterator就是在该类中定义的,类中提供了创建ArraySpliterator对象和IteratorSpliterator对象的方法。
接下来,本文首先介绍Spliterator接口中各个方法作用及特征值,然后介绍Spliterator与Iterator接口的区别,最后介绍上面这四个实现类的原理。
一、Spliterator接口
1、接口方法
下面是Spliterator接口中的方法:
public interface Spliterator<T> {
boolean tryAdvance(Consumer<? super T> action);
default void forEachRemaining(Consumer<? super T> action) {
do { } while (tryAdvance(action));
}
Spliterator<T> trySplit();
long estimateSize();
default long getExactSizeIfKnown() {
return (characteristics() & SIZED) == 0 ? -1L : estimateSize();
}
int characteristics();
default boolean hasCharacteristics(int characteristics) {
return (characteristics() & characteristics) == characteristics;
}
default Comparator<? super T> getComparator() {
throw new IllegalStateException();
}
}
2、特征值
Spliterator还提供了一些静态常量,它们是Spliterator的特征值,用于表示该Spliterator是否具有某种特征。
public static final int ORDERED = 0x00000010;
public static final int DISTINCT = 0x00000001;
public static final int SORTED = 0x00000004;
public static final int SIZED = 0x00000040;
public static final int NONNULL = 0x00000100;
public static final int IMMUTABLE = 0x00000400;
public static final int CONCURRENT = 0x00001000;
public static final int SUBSIZED = 0x00004000;
3、Spliterator与Iterator区别
两个接口的作用都是遍历元素,不过Spliterator提供的功能更为丰富。
下面先看一下Iterator接口的方法都有哪些:
public interface Iterator<E> {
boolean hasNext();
E next();
default void remove() {
throw new UnsupportedOperationException("remove");
}
default void forEachRemaining(Consumer<? super E> action) {
Objects.requireNonNull(action);
while (hasNext())
action.accept(next());
}
}
下面介绍一下两者之间的不同:
- 使用Iterator更常用的场景是从数据源中获取元素,然后在外部对元素做更加复杂的加工处理,而Spliterator只能使用Consumer处理,无法直接得到数据源中的元素,只能由内部遍历;
- Iterator可以删除数据源中的元素,不过这个依赖于数据源的实现,有些数据源是不支持的;
- Spliterator可以得到元素个数,而Iterator不可以;
- Spliterator提供了很多特征值,可以直接获知元素的特征;
- Spliterator提供了拆分方法,可以在并行流中使用。
二、实现类原理
本小节只介绍实现类中trySplit()方法,其他的方法比较简单不做介绍。
1、ArraySpliterator
该类的数据源为数组,默认特征值是Spliterator.SIZED | Spliterator.SUBSIZED。
下面看一下trySplit()方法:
public Spliterator<T> trySplit() {
int lo = index, mid = (lo + fence) >>> 1;
return (lo >= mid)
? null
: new ArraySpliterator<>(array, lo, index = mid, characteristics);
}
从代码中可以很明显的看出,每调用一次trySplit()都是将元素平均的一分为二,将左半部分的元素新建一个ArraySpliterator对象。
2、IteratorSpliterator
该类的数据源为迭代器。
下面看一下trySplit()方法:
public Spliterator<T> trySplit() {
Iterator<? extends T> i;
long s;
if ((i = it) == null) {
i = it = collection.iterator();
s = est = (long) collection.size();
}
else
s = est;
if (s > 1 && i.hasNext()) {
int n = batch + BATCH_UNIT;
if (n > s)
n = (int) s;
if (n > MAX_BATCH)
n = MAX_BATCH;
Object[] a = new Object[n];
int j = 0;
do { a[j] = i.next(); } while (++j < n && i.hasNext());
batch = j;
if (est != Long.MAX_VALUE)
est -= j;
return new ArraySpliterator<>(a, 0, j, characteristics);
}
return null;
}
从代码可以看出,如果元素足够多,第一次拆分时,将BATCH_UNIT个元素拆分出来,第二次拆分,需要拆分出batch + BATCH_UNIT个元素,也就是2*BATCH_UNIT个元素,第三次拆分也是一样。
这里要注意,trySplit()返回的是ArraySpliterator,我猜测这可能是为了性能的考虑。
3、ConcatSpliterator
该类的数据源为Spliterator。
ConcatSpliterator是将两个Spliterator对象组合成一个,因此ConcatSpliterator提供了两个属性aSpliterator和bSpliterator,同时使用beforeSplit表示aSpliterator是否已经访问结束,如果为true,表示没有。
public T_SPLITR trySplit() {
@SuppressWarnings("unchecked")
T_SPLITR ret = beforeSplit ? aSpliterator : (T_SPLITR) bSpliterator.trySplit();
beforeSplit = false;
return ret;
}
如果beforeSplit为true,那么直接将aSpliterator返回,作为拆分结果,之后的拆分,都是调用bSpliterator.trySplit()完成。
4、InfiniteSupplyingSpliterator
InfiniteSupplyingSpliterator是抽象类,它有四个实现类:OfRef、OfDouble、OfInt、OfLong,分别用于处理对象、Double、Integer、Long类型的元素。
InfiniteSupplyingSpliterator的数据源为生成函数,只有一个特征值IMMUTABLE。它的trySplit()方法是在子类中实现的。下面以OfRef为例做介绍:
public Spliterator<T> trySplit() {
if (estimate == 0)
return null;
return new InfiniteSupplyingSpliterator.OfRef<>(estimate >>>= 1, s);
}
trySplit()方法没有调用生成函数获取元素的动作,只是设置元素个数为当前剩余元素的一半,然后新建一个OfRef对象。
cs