final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
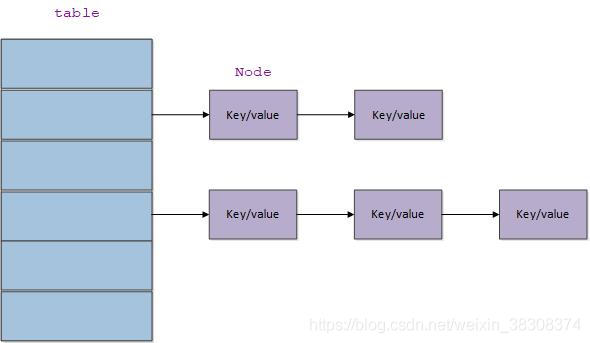
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1)
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) {
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
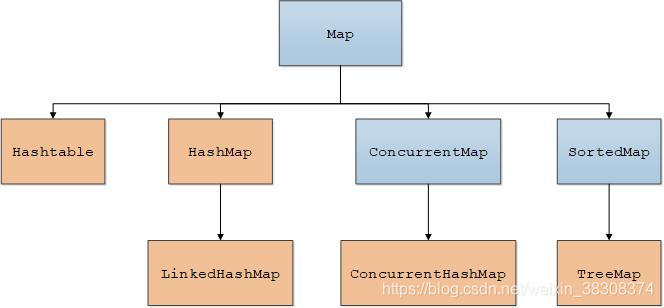
相比于java8之前的版本,HashMap有三点改动非常大:
- 一是如果链表的长度小于8,则每次都将元素插入到链表尾,之前的版本是插入到链表头,之所以把元素插入到链表尾,其中一个原因就是在并发的情况下因为插入而进行扩容时可能会出现链表环而发生死循环,不过,HashMap本身是不用于处理并发情况的。
- 二是如果链表长度大于等于8且桶个数大于等于64,则将链表转换为红黑树,这个是之前的版本没有实现的,修改为红黑树之后,可以加快查询速度,红黑树的时间复杂度是O(nlogn);
- 当加入的键值对过多,超过了负载因子,那么HashMap启动再哈希,再哈希将键值对重新放入每个桶中,如果原来的Node节点是树,再哈希后发现树的元素个数小于等于6,那么HashMap会将树转换为链表。
在putVal()方法最后,如果元素个数超过了threshold(threshold = 桶数 * 负载因子),那么需要扩充桶,扩充桶是将table的长度扩充到原来的2倍,然后将每个键值对重新计算哈希值放入桶中。java8对每个键值对重新放入桶中也做了优化,想了解请参见文末的参考文章。
2、Hashtable
Hashtable将每个方法都使用synchronized关键字修饰。Hashtable与HashMap的原理类似,下面只介绍两者不同的地方:
- Hashtable的默认初始容量为11,它不像HashMap一样,容量必须是2的次幂,Hashtable使用
(hash & 0x7FFFFFFF) % tab.length计算桶的位置; - 新增加的键值对放到链表头,无论链表多长,都不会转换为红黑树;
- 如果元素个数超过了阈值,Hashtable会扩容,扩容长度为
(oldCapacity << 1) + 1,接下里对每个键值对重新计算哈希值,然后放入桶中。
HashMap做的很多优化在Hashtable上都没有,因此性能上,HashMap要优于Hashtable。
3、LinkedHashMap
LinkedHashMap是HashMap的子类。
HashMap有一个缺点,就是HashMap中的元素是无序的,无法按照插入顺序遍历元素,这时LinkedHashMap便提供了这个功能,可以按照插入顺序遍历。
为了实现这个功能,LinkedHashMap在内部维护了一个双链表,使用head和tail属性记录链表的头和尾:
transient LinkedHashMap.Entry<K,V> head;
transient LinkedHashMap.Entry<K,V> tail;
链表节点定义为:
static class Entry<K,V> extends HashMap.Node<K,V> {
Entry<K,V> before, after;
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}
每当插入新元素时都会创建一个Entry对象,并将这个Entry对象加入到链表的尾部,这样链表上节点的顺序就是元素的插入顺序,下面是创建Entry对象的代码:
Node<K,V> newNode(int hash, K key, V value, Node<K,V> e) {
LinkedHashMap.Entry<K,V> p =
new LinkedHashMap.Entry<K,V>(hash, key, value, e);
linkNodeLast(p);
return p;
}
private void linkNodeLast(LinkedHashMap.Entry<K,V> p) {
LinkedHashMap.Entry<K,V> last = tail;
tail = p;
if (last == null)
head = p;
else {
p.before = last;
last.after = p;
}
}
这样当我们使用Iterator或者调用forEach()方法遍历元素时,直接遍历双向链表即可。
LinkedHashMap相对于HashMap来说,插入一个元素既要插入到桶中,也要插入到链表中。
LinkedHashMap还提供了属性accessOrder,如果accessOrder=true,那么链表除了按照插入顺序排序之外,如果调用get()方法访问了该元素,那么该元素也会被移动到链表尾部。默认accessOrder=false。下面来看一下get()方法代码:
public V get(Object key) {
Node<K,V> e;
if ((e = getNode(hash(key), key)) == null)
return null;
if (accessOrder)
afterNodeAccess(e);
return e.value;
}
基于这个特性,可以使用LinkedHashMap实现LRU算法,使用越频繁的元素越靠后,当缓存满的时候,可以将链表头部的元素删除。
4、TreeMap
TreeMap是使用红黑树实现的,它没有桶的概念,使用属性root记录红黑树的树根:
private transient Entry<K,V> root;
因为是基于树实现的,所以TreeMap没有初始容量,也没有负载因子的概念,而且还是无界的。它要求key不能为null,因为红黑树要比较元素大小,所以要么key实现接口Comparable,要么比较器属性comparator不能为null,如果属性comparator不为null,那么优先使用comparator比较元素大小。
根据key查询时直接在红黑树上搜索,时间复杂度是O(nlogn)的。同样的,插入、删除操作也都是O(nlogn)的。
TreeMap实现了NavigableMap接口,NavigableMap继承自SortedMap接口,前者在后者的基础上做了扩展,提供了大量的与顺序相关的方法,比如创建按照升序遍历的迭代器。因为TreeMap是有序的,所以可以很方便的创建按照升序或者降序遍历元素的迭代器,也可以查找大于/小于某个key的所有元素,以及TreeMap中的最大元素或者最小元素。
5、ConcurrentHashMap
ConcurrentHashMap是这些类中,唯一一个线程安全的Map实现类,它是基于CAS使用类Unsafe操作来操作元素。
ConcurrentHashMap的总体实现原理与HashMap是类似的,比如:
- ConcurrentHashMap的默认初始容量是16,默认负载因子是0.75;
- 与HashMap一样,也使用了数组来表示桶,当元素key的hash值一样时,会放到桶后面的链表尾上,如果链表长度达到了8,且总的元素个数大于等于64,则将链表改造成红黑树;
- 计算key的哈希值使用的算法与HashMap一样;
- 每次扩充桶时,都是扩充为原来的2倍,桶的个数永远都是2的次幂。
两个类计算key的哈希规则是不同,ConcurrentHashMap的计算规则是:
static final int spread(int h) {
return (h ^ (h >>> 16)) & HASH_BITS;
}
spread()方法里面使用0x7fffffff进行了与操作,这样得到的哈希结果一定是正的。那么为什么要哈希结果一定是正的呢?原因是负值在ConcurrentHashMap中有特殊含义,比如如果节点的哈希值是-1,表示正在进行再哈希,如果是-2,表示当前节点是红黑树的树根,我们可以在代码中看到key.hash>=0的判断,大于0表示桶后面是一个链表。
除了使用CAS之外,当插入和删除元素、扩容操作时,还会使用synchronized关键字将槽位锁住,防止不同线程同时操作同一个链表或者红黑树。