Ϊʲô����ִ����binlog�Ϳ��Ը����Ᵽ��һ��?
MySQL�����Ļ���ԭ��
- ���������������
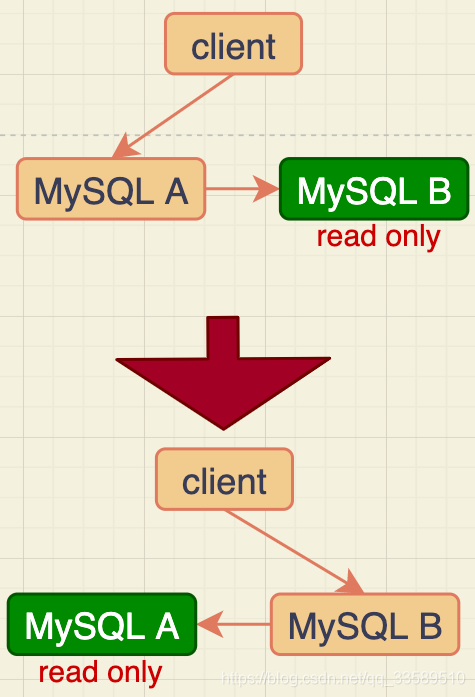
�ϲ���״̬:�ͻ��˵Ķ�д��ֱ�ӷ���A,B��A�ı���,ֻ�ǽ�A�ĸ��¶�ͬ������,������ִ�С��������Ա���B��A��������ͬ��
����Ҫ�л�ʱ,���г��²���״̬:�ͻ��˶�д���ʵĶ���B,A��B�ı��⡣
�ϲ���״̬,��Ȼ�ڵ�Bû�б�ֱ�ӷ���,���Ƽ���B(����)���ֻ��(readonly),��������:
- ��ʱ��һЩ��Ӫ��IJ�ѯ���ᱻ�ŵ�������ȥ��,����Ϊֻ�����Է�ֹ�����
- ��ֹ�л�����bug,�����л������г���˫д,���������һ��
- ������readonly״̬,���жϽڵ�Ľ�ɫ��
�ѱ������ó�ֻ����,���ܺ����Ᵽ��ͬ��������?
����ͬ�����µ��߳�,ӵ�г���Ȩ�ޡ� readonly���öԳ���(super)Ȩ���û���Ч��
A��B�����ߵ��ڲ�������ʲô����?��ͼ�л����ľ���һ��update����ڽڵ�Aִ��,Ȼ��ͬ�����ڵ�B����������ͼ
������յ��ͻ��˵ĸ��������,ִ���ڲ�����ĸ�����,ͬʱдbinlog��
����B������A֮��ά����һ�������ӡ�����A�ڲ���һ���߳�,ר�����ڷ���B����������ӡ�һ��������־ͬ���Ĺ���:
- �ڱ���Bͨ��change master����,��������A��IP���˿ڡ��û���������,�Լ�Ҫ���ĸ�λ�ÿ�ʼ����binlog,���λ�ð����ļ�������־ƫ����
- �ڱ���B��ִ��start slave����,��ʱ���������io_thread��sql_thread��io_thread���������⽨������
- ����AУ�����û����������,��ʼ���ձ���B��������λ��,�ӱ��ض�ȡbinlog,����B
- ����B�õ�binlog��,д�������ļ�,��Ϊ��ת��־(relay log)
- sql_thread��ȡ��ת��־,��������־�������,��ִ��
�������ڶ��̸߳��Ʒ���������,sql_thread�ݻ���Ϊ�˶���̡߳�
binlog�ﵽ����ʲô
Ϊʲô�����ù�ȥ����ֱ��ִ�С�
- ������������ʼ������
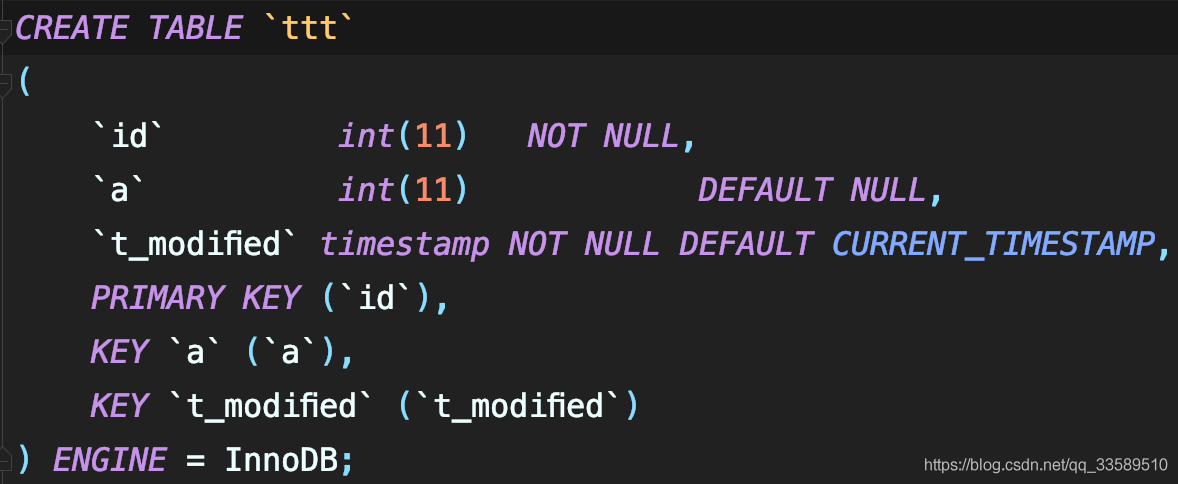
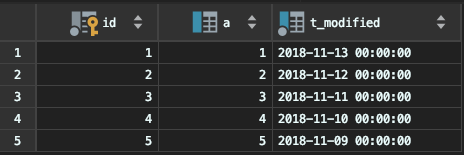
Ҫ�ڱ���ɾ��һ��,���delete����binlog����ô��¼�ġ�
ע��,�������������ע��,�������MySQL�ͻ����������ʵ��Ļ�,Ҫ�ǵü�-c����,����ͻ��˻��Զ�ȥ��ע�͡�
delete
from ttt -c
where a >= 4
and t_modified <= '2018-11-10'
limit 1;
��binlog_format=statementʱ,binlog�����¼�ľ���SQL����ԭ�ġ��������
- �鿴binlog����,������ ROW ��ʽ,������ statement ��ʽ��
mysql> show binlog events in 'binlog.000034';
+
| Log_name | Pos | Event_type | Server_id | End_log_pos | Info |
+
| binlog.000034 | 786 | Anonymous_Gtid | 1 | 865 | SET @@SESSION.GTID_NEXT= 'ANONYMOUS' |
| binlog.000034 | 865 | Query | 1 | 977 | BEGIN |
| binlog.000034 | 977 | Query | 1 | 1151 | use `common_mistakes`; delete from ttt where a >= 4 and t_modified <= '2018-11-10' limit 1 |
| binlog.000034 | 1151 | Query | 1 | 1264 | COMMIT |
+
16 rows in set (0.00 sec)
- BEGIN������COMMITƥ��,��ʾ�м��Ǹ�����
- �����о�����ʵִ�е���䡣����ʵִ�е�delete����֮ǰ,����һ��use�������������MySQL���ݵ�ǰҪ�����ı����ڵ����ݿ���������ӵġ���ô��,���Ա�֤��־��������ȥִ��ʱ,���۵�ǰ�����߳����ĸ���,���ܹ���ȷ���µ�common_mistakes���ttt����
- �����delete ���,����SQLԭ���
- ���һ����һ��COMMITд��xid��
��ǰbinlog���õ���statement��ʽ,�����������limit,�����������unsafe�ġ���Ϊdelete ��limit,���ܳ����������ݲ�һ�¡����������������:
- ��deleteʹ�õ�������a,����������a�ҵ���һ��������������,��ɾ������a=4��һ��
- ����ʹ�õ�������t_modified,��ɾ���ľ���
t_modified='2018-11-09',��a=5����
����statement��ʽ��,��¼��binlog�����ԭ���,���ܷ���:������ִ�и�SQLʱ,�õ�������a;���ڱ���ִ�и�SQLʱ,ȴʹ������t_modified�����,����д���з��յġ�
����binlog��ΪROW ��ʽ,�Dz��Ǿ�û��������?
mysql> show binlog events in 'binlog.000034';
+
| Log_name | Pos | Event_type | Server_id | End_log_pos | Info |
+
| binlog.000034 | 156 | Anonymous_Gtid | 1 | 235 | SET @@SESSION.GTID_NEXT= 'ANONYMOUS' |
| binlog.000034 | 235 | Query | 1 | 329 | BEGIN |
| binlog.000034 | 329 | Table_map | 1 | 392 | table_id: 102 (common_mistakes.ttt) |
| binlog.000034 | 392 | Delete_rows | 1 | 440 | table_id: 102 flags: STMT_END_F |
| binlog.000034 | 440 | Xid | 1 | 471 | COMMIT
BEGIN��COMMIT��һ���ġ���row��ʽ��binlog��û��ԭSQL���,������event:
- Table_map event
˵��������Ҫ�����ı���test��ı�t - Delete_rows event
����ɾ������Ϊ
��ʵ����Ҫ����mysqlbinlog����,���������������Ͳ鿴binlog���ݡ���Ϊͼ5�е���Ϣ��ʾ,��������binlog�Ǵ�8900���λ�ÿ�ʼ��,���Կ�����start-position������ָ�������λ�õ���־��ʼ������
/usr/local/Cellar/mysql/8.0.21_1/bin/mysqlbinlog
-vv /usr/local/var/mysql/binlog.000034
row��ʽbinlog ʾ������ϸ��Ϣ
BEGIN
;
BINLOG '
IGe8YBMBAAAAPwAAAIgBAAAAAGYAAAAAAAEAD2NvbW1vbl9taXN0YWtlcwADdHR0AAMDAxEBAAIB
AQAAmNfo
IGe8YCABAAAAMAAAALgBAAAAAGYAAAAAAAEAAgAD/wAEAAAABAAAAFvlrwDRQzuL
';
COMMIT;
- server id 1
��������server_id=1�Ŀ���ִ�� - ÿ��event����CRC32ֵ,��Ϊbinlog_checksum��CRC32
- Table_map event
��ʾ�˽�����Ҫ�ı�,map������226��������������SQL���ֻ������һ�ű�,�����������?ÿ��������һ����Ӧ��Table_map event������map��һ������������,�������ֶԲ�ͬ���IJ����� - -vv������Ϊ�˰����ݶ���������,���Դӽ��������Կ��������ֶε�ֵ(����,@1=4�� @2=4��Щֵ)
- binlog_row_image
Ĭ��������FULL,���Delete_event����,������ɾ�����е������ֶε�ֵ������binlog_row_image����ΪMINIMAL,��ֻ���¼��Ҫ����Ϣ���ڸ���,��ֻ���¼id=4�� - Xid event
��ʾ������ȷ�ύ�ˡ�
�ɼ�,��binlog_format=row,binlog��¼����ʵɾ���е�����id,����binlog��������ʱ,�Ϳ϶���ɾ��id=4����,����������ɾ����ͬ�е����⡣
Ϊ��binlog��mixed��ʽ?
��Ϊ��Щstatement��ʽ��binlog���ܻᵼ��������һ��,����Ҫʹ��row��ʽ��
��row��ռ�ռ�(��Ȼ��ô������?)����������һ��delete���ɾ��10����:
- statement����һ��SQL��䱻��¼��binlog,ռ�ü�ʮ���ֽ�
- row��Ҫ����10������¼��д��binlog������ռ�þ�ռ�,дbinlogҲҪ�ķ�I/O��Դ,Ӱ��ִ���ٶȡ�
����,MySQL��ȡ���з���-mixed:MySQL�Լ����жϸ�SQL�Ƿ��������������һ��:
- ���,��row
- ������,��statement
��mixed�ȿ�������statment��ʽ���ŵ�,���ܱ������ݲ�һ�¡�
�������ǵ�����,��Ϊmixed��:
- �ͻ��¼Ϊrow
- ��ִ�е����û��limit 1,�ͼ�¼Ϊstatement
����Խ��Խ��ij���Ҫ���MySQL��binlog��ʽ���row����ô���������кܶ�,����ָ����ݡ�
���ݻָ�����Ҫ��
- ��ʹִ��delete,row��ʽbinlogҲ�ᱣ�汻ɾ�����е�������Ϣ������,������ִ����һ��delete��,����ɾ��������,����ֱ�Ӱ�binlog�м�¼��deleteתinsert,�Ѵ�ɾ���ݲ�ء�
- ��ִ�д�insert��?row��,insert��binlog����¼�����ֶ���Ϣ,����������λ����������С���ֱ�Ӱ�insertתdelete ���ɡ�
- ��ִ��update,binlog���¼��ǰ���е����ݺ��ĺ���������ݡ�����ֻ������eventǰ��������Ϣ�Ե�,��DB��ִ��
��Ȼmixed��ʽ��binlog�����Ѿ��õò�����,�����ﻹ��Ҫ�ٽ���һ��mixed��ʽ��˵��һ������,����һ������SQL���:
insert into ttt values(10,10, now());
��binlog��Ϊmixed,MySQL�������¼Ϊɶ��ʽ��?

MySQL����statement��ʽ������binlog����1min�Ŵ�������,���������ݲ��Ͳ�һ����?
����mysqlbinlog�鿴:
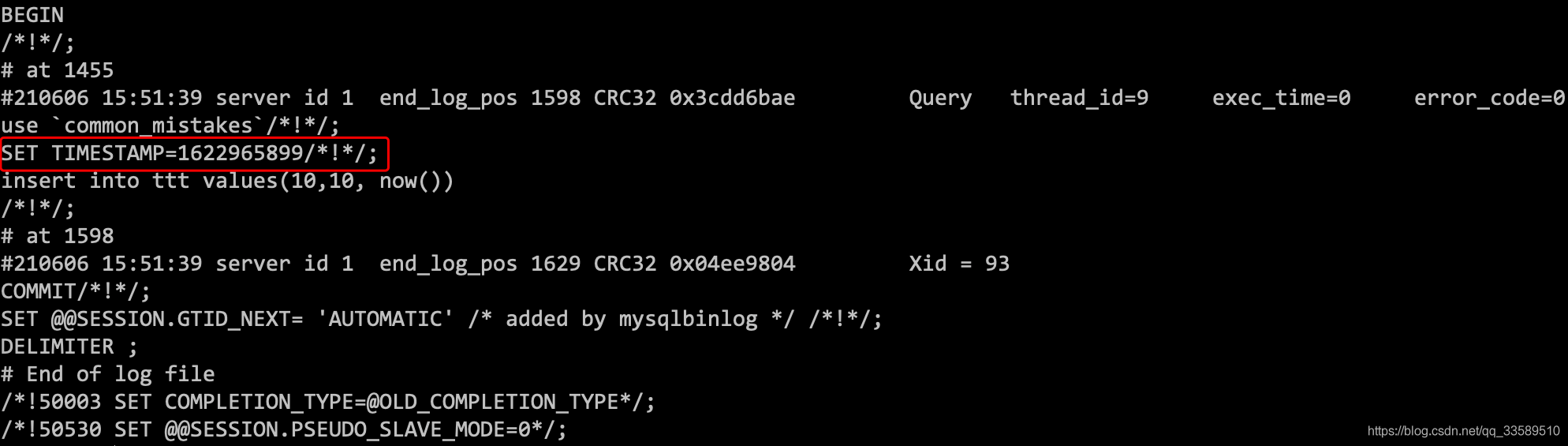
binlog�ڼ�¼eventʱ,�����һ������:SET TIMESTAMP������ SET TIMESTAMP����Լ���˽�������now()�����ķ���ʱ�䡣
���,���۸�binlog��ú���ִ�л����ڻָ��ÿ�ı���,��insert�������,ֵ���̶�����ͨ��SET TIMESTAMP,MySQL��֤����������һ���ԡ�
�����ط�binlogʱ,����ô����:
- ��mysqlbinlog��������־
- Ȼ��������statement���ֱ�ӿ�������ִ��
�����з��ա���Ϊ��Щ����ִ�н������������������,ֱ��ִ�кܿ��ܴ���
ʹ��binlog�ָ����ݵ���ȷ����:
- �� mysqlbinlog���߽�������
- Ȼ��ѽ��������������MySQLִ�С��������������:
mysqlbinlog master.000001
�� master.000001 �ļ�����ӵ�2738�ֽڵ���2973�ֽ��м�������ݽ�������,�ŵ�MySQLȥִ�С�
ѭ����������
binlogȷ�����ڱ���ִ����ͬ��binlog,���Եõ���������ͬ��״̬��
���,������Ϊ�������������������һ�µġ�������һ��ʼ��ͼ��A��B�����ڵ��������һ�µġ���������M-S�ṹ,ʵ��������ʹ�ñȽ϶����˫M�ṹ:
- MySQL�����л����̨C˫M�ṹ
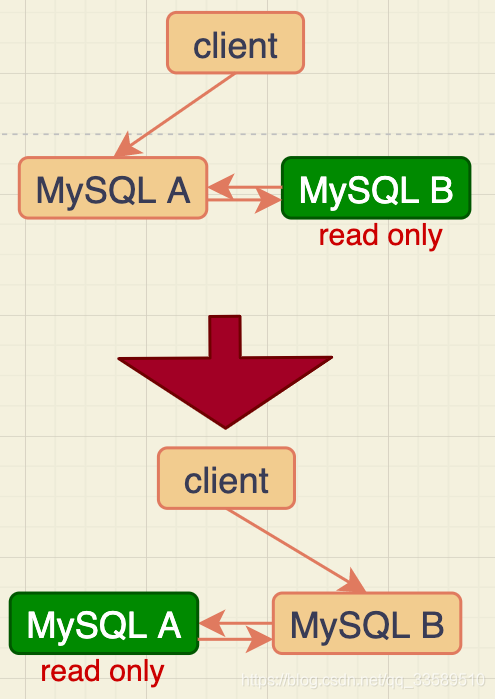
����ֻ�Ƕ���һ����,��:�ڵ�A��B֮�����ǻ�Ϊ������ϵ���������л���ʱ��Ͳ�������������ϵ��
����,˫M�ṹ����һ��������Ҫ���:ҵ�����ڽڵ�A�ϸ�����һ�����,Ȼ���ٰ����ɵ�binlog �����ڵ�B,�ڵ�Bִ����������������Ҳ������binlog��(�Ƽ��Ѳ���log_slave_updates����Ϊon,��ʾ����ִ��relay log������binlog)��
��ô,���ڵ�Aͬʱ�ǽڵ�B�ı���,�൱���ְѽڵ�B�����ɵ�binlog�ù���ִ����һ��,Ȼ��ڵ�A��B��,��ϵ�ѭ��ִ������������,Ҳ����ѭ�������ˡ�����ô���?
�����Ѿ�֪��,MySQL��binlog�м�¼����������һ��ִ��ʱ����ʵ����server id�����,���������������������ڵ���ѭ�����Ƶ�����:
- �涨�������server id���벻ͬ,�����ͬ,������֮�䲻���趨Ϊ������ϵ
- һ������ӵ�binlog�����طŵĹ�����,������ԭbinlog��server id��ͬ���µ�binlog
- ÿ�������յ����Լ������ⷢ��������־��,���ж�server id,������Լ�����ͬ,��ʾ�����־���Լ����ɵ�,��ֱ�Ӷ��������־
���������,�������������˫M�ṹ,��־��ִ�����ͻ�������:
4. �ӽڵ�A���µ�����,binlog����ǵĶ���A��server id
5. �����ڵ�Bִ��һ���Ժ�,�ڵ�B���ɵ�binlog ��server idҲ��A��server id
6. �ٴ��ظ��ڵ�A,A�жϵ����server id���Լ�����ͬ,�Ͳ����ٴ��������־������,��ѭ��������Ͷϵ���
binlog��MySQL�߿��÷�������Ҫ,������MySQL�߿��÷���,�����ڵ㡢��ͬ����MySQL group replication�ȵĻ�����
cs