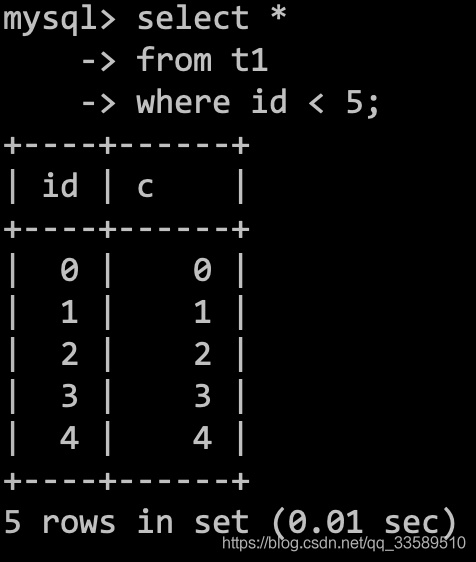
mysql> show processlist;
+
| Id | User | Host | db | Command | Time | State | Info |
+
| 5 | event_scheduler | localhost | NULL | Daemon | 390719 | Waiting on empty queue | NULL |
| 41 | root | localhost | common_mistakes | Query | 8 | User sleep | update t1 set id=sleep(10) where id=1 |
| 47 | root | localhost | common_mistakes | Query | 4 | Waiting for table level lock | select * from t1 where id=2 |
| 49 | root | localhost:56378 | common_mistakes | Sleep | 100 | | NULL |
| 51 | root | localhost | NULL | Query | 0 | starting | show processlist |
+
5 rows in set (0.00 sec)
表锁限制了并发访问。所以,内存表的锁粒度问题,决定了它在处理并发事务时,性能也不好。
数据持久性
数据放在内存中,是内存表优势,但也是劣势。数据库重启时,所有内存表会被清空。
若数据库异常重启,内存表被清空也就清空了,好像也不会有啥问题呀!但在高可用架构下,内存表的这个特点就是个bug!
M-S架构下内存表的问题。
- M-S基本架构
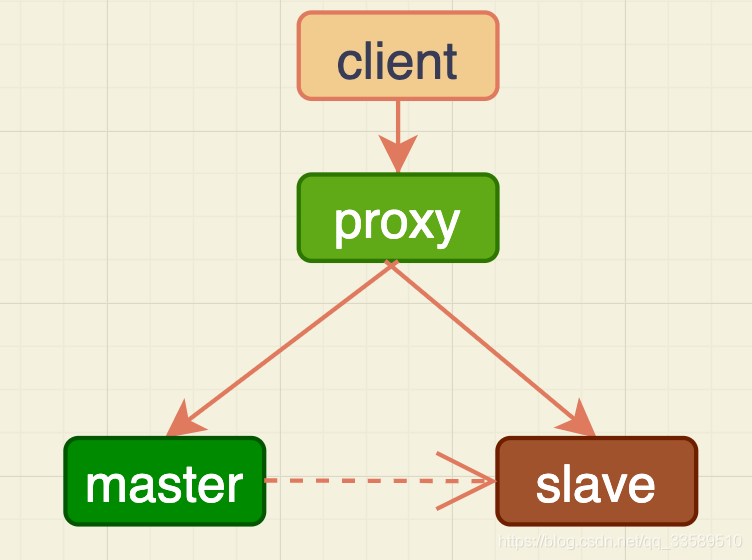
- 业务正常访问主库
- 备库由于xxx而重启,内存表t1内容被清空
- 备库重启后,客户端发送一条update语句,修改t1的数据行,这时备库应用线程就会报错“找不到要更新的行”
这就会导致主备同步停止。当然了,若此时发生主备切换,客户端会看到,t1的数据“丢失”了。
在有proxy的架构,默认主备切换的逻辑由数据库系统自己维护。这样对客户端来说,就是“网络断开,重连之后,发现内存表数据丢失了”。
这也还好呀,毕竟主备发生切换,连接会断开,业务端能够感知到异常!
但接下来内存表会让现象更“诡异”。由于MySQL知道重启之后,会丢失内存表数据。所以,担心主库重启之后,出现主备不一致,MySQL会在数据库重启后,往binlog写一行DELETE FROM t1。
此时若使用的双M架构:
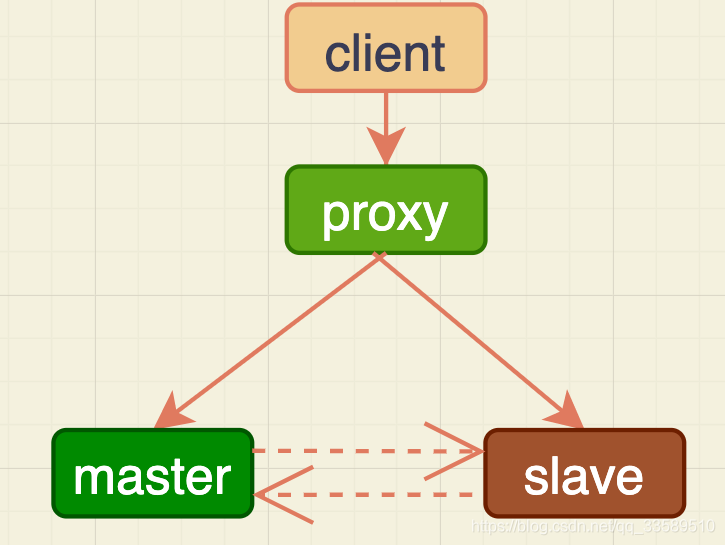
备库重启时,备库binlog里的delete语句就会传到主库,然后把主库内存表删除。这样你在使用时,就会发现主库的内存表数据突然被清空。
综上,内存表不适合在生产环境使用。
但内存表执行速度就是快呀?!
- 若你的表更新量大,那么并发度是个重要指标,InnoDB支持行锁,并发度就是比内存表好
- 能放到内存表的数据量都不大。若你考虑的是读性能,一个读QPS很高 && 数据量不大的表,即使用InnoDB,数据也都会缓存在 Buffer Pool,读性能也不会差!
所以,推荐普通内存表都用InnoDB表替代。
but!有个场景是例外:用户临时表,在数据量可控,不会耗费过多内存的情况下,你可以考虑使用内存表。
内存临时表刚好可以无视内存表的两个不足,主要因为:
- 临时表不会被其他线程访问,无并发问题
- 临时表重启后也需要删除,不存在清空数据问题
- 备库的临时表也不会影响主库的用户线程
看看join语句优化案例,推荐创建一个InnoDB临时表,使用的语句序列是:
create temporary table temp_t
(
id int primary key,
a int,
b int,
index (b)
) engine = innodb;
insert into temp_t
select *
from t2
where b >= 1
and b <= 2000;
select *
from t1
join temp_t on (t1.b = temp_t.b);
这里使用内存临时表的效果更好:
- 使用内存表不需要写磁盘,往表temp_t的写数据的速度更快
- 索引b使用hash索引,查找的速度比B-Tree索引快
- 临时表数据只有2000行,占用的内存有限
因此,可以将临时表temp_t改成内存临时表,并且在字段b上创建一个hash索引。
create temporary table temp_t
(
id int primary key,
a int,
b int,
index (b)
) engine = memory;
insert into temp_t
select *
from t2
where b >= 1
and b <= 2000;
select *
from t1
join temp_t on (t1.b = temp_t.b);
- 使用内存临时表的执行效果
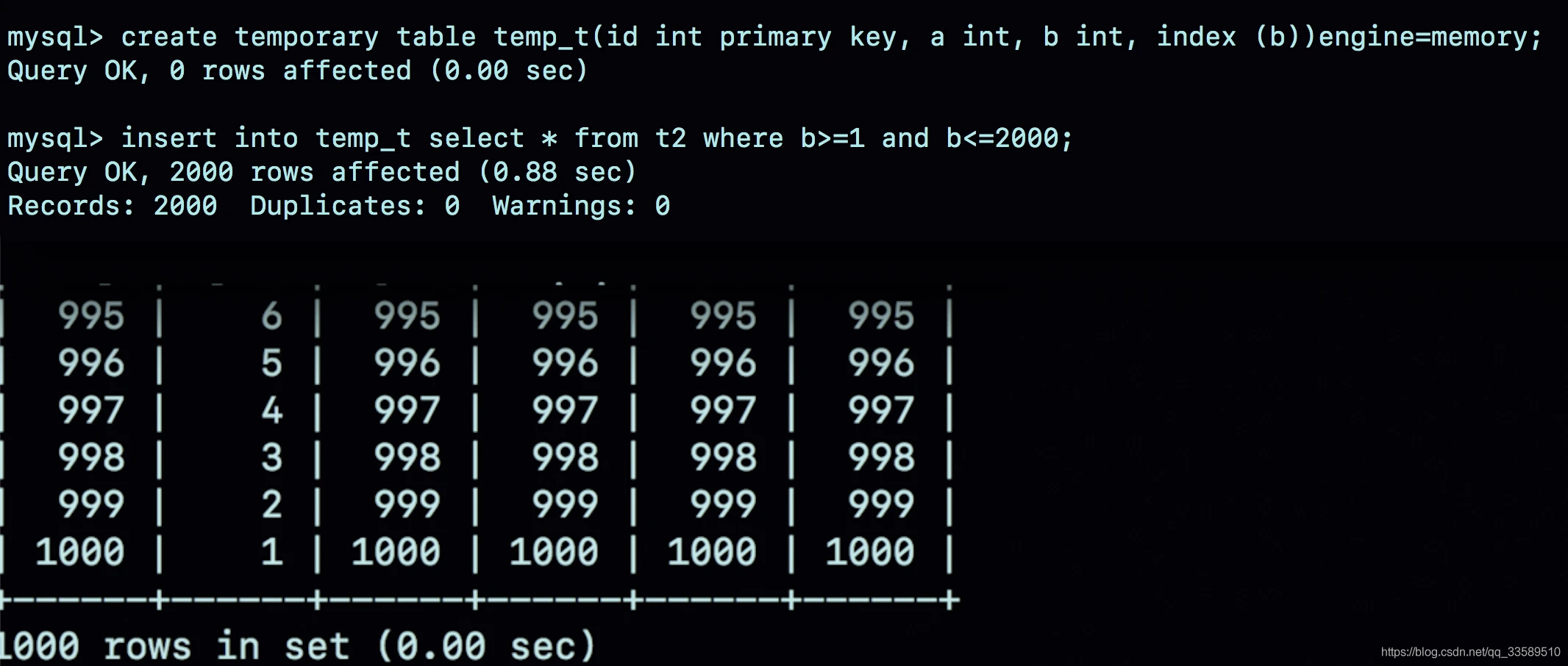
不论是导入数据的时间,还是执行join的时间,使用内存临时表的速度都比使用InnoDB临时表要快。
cs

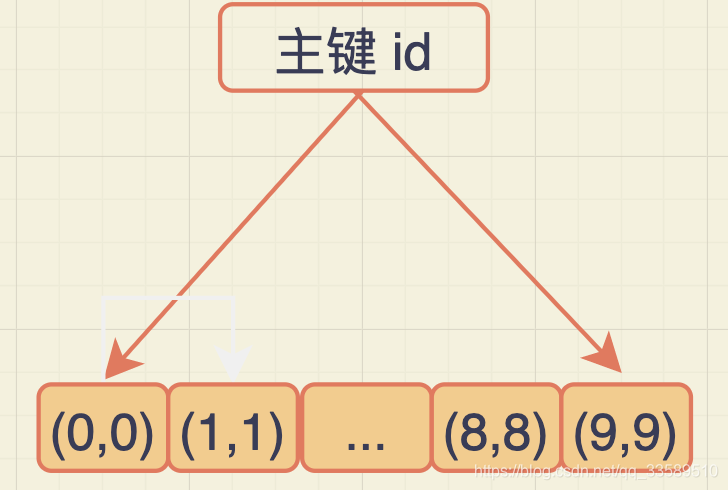



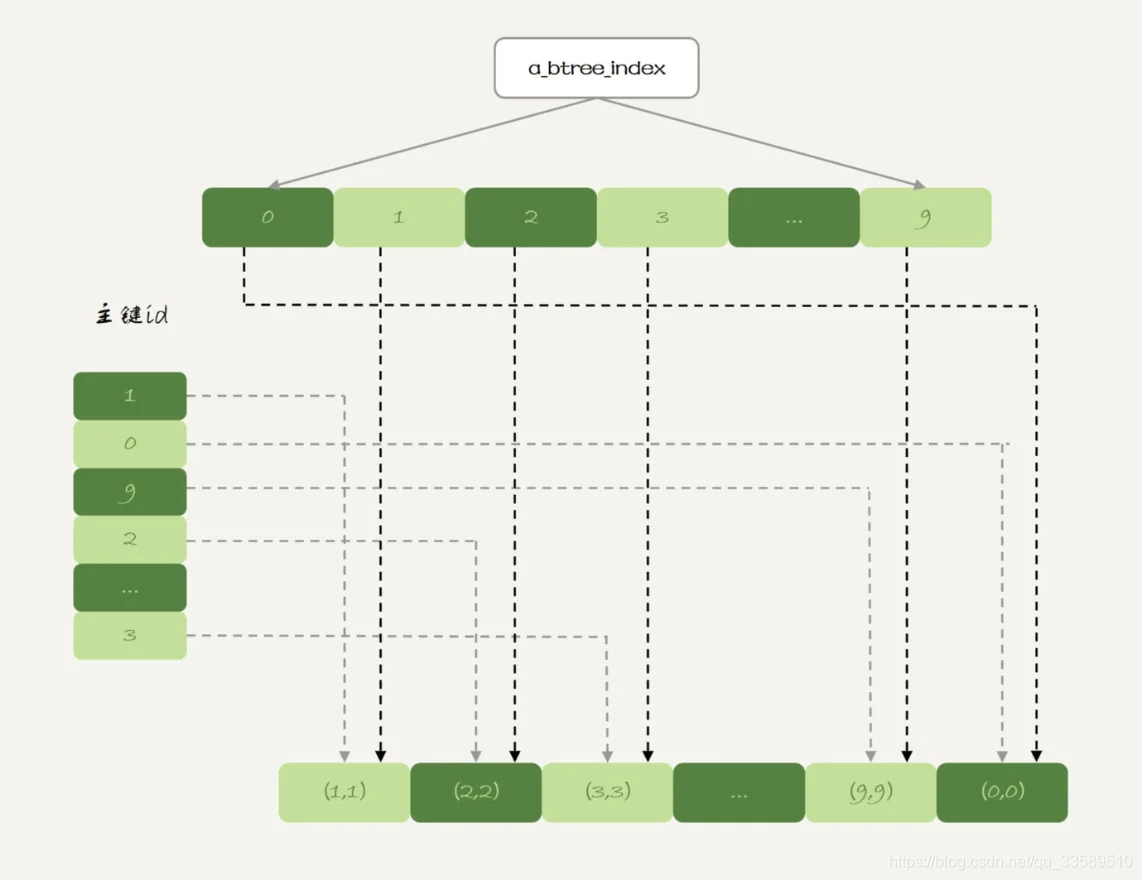 这就类似InnoDB的b+树索引了。
这就类似InnoDB的b+树索引了。