һ������Ҫ����һ��,����պ�������һ������ӵ����һ�е�����,���ᱻ��ס����Ȼ����ȴ�״̬,��ô�ȵ���������Լ���ȡ������Ҫ��������ʱ,��������ֵ����ʲô��?
- ��ʼ��
- ����A��B��C��ִ������

��ʱ��������?
- begin/start transaction
��ִ�е�����֮��ĵ�һ������InnoDB�������,���������������һ������ͼ����ִ�е�һ�����ն����ʱ�����ġ� - start transaction with consistent snapshot
������Ҫ��������һ������,����ʹ�á�һ������ͼ����ִ��start transaction with consistent snapshotʱ�����ġ�
��������˵��,Ĭ��autocommit=1��
����:
- ����Cû����ʽʹ��begin/commit,��ʾ��update��䱾�����Ǹ�����,������ʱ���Զ��ύ
- ����B�ڸ�������֮��,��ѯ
- ����A��һ��ֻ�������в�ѯ,����ʱ������������B�IJ�ѯ��
��ͼ
MySQL����������ͼ������:
- view
һ���ò�ѯ��䶨��������,�ڵ���ʱ,ִ�в�ѯ��䲢���ɽ����������ͼ�����create view �� ,�����IJ�ѯ�������һ�� - InnoDB��ʵ��MVCCʱ�õ���һ���Զ���ͼ,��consistent read view
����֧�����ύ�����ظ�������û�������ṹ,����ִ���ڼ��������塰���ܿ���ʲô���ݡ���
�����ա���MVCC������ô������?
�ڿ��ظ�����,��������ʱ�͡����˸����ա���
- �ÿ����ǻ�������ġ�
��һ������100G,������һ������,MySQL��Ҫ����100G�����ݳ���,��ö�������ʵ����,������Ҫ��������100G���ݡ�
�ȿ������յ�ʵ�֡�
InnoDB��ÿ�������и�Ψһ����ID:transaction id,������ʼʱ��InnoDB����ϵͳ�����,������˳���ϸ������
ÿ������Ҳ���ж���汾
ÿ�������������ʱ,��������һ���µ����ݰ汾,����transaction id���������ݰ汾������ID,��Ϊrow trx_id��ͬʱ,�����ݰ汾Ҫ����,�����������ݰ汾��,�ܹ��а취����ֱ���õ�����
Ҳ����˵,���ݱ��е�һ�м�¼,��ʵ�����ж���汾(row),ÿ���汾���Լ���row trx_id��
��ͼ��ʾ,����һ����¼����������������º��״̬��
���߿�����ͬһ�����ݵ�4���汾,��ǰ���°汾��V4,k=22,���DZ�transaction id=25���������,�������row trx_id=25��
- �����»�����undo log(�ع���־),������?
��������ͷ,����undo log��V1��V2��V3������������ʵ����,����ÿ����Ҫʱ,���ݵ�ǰ�汾��undo log������á�����,��ҪV2ʱ,��ͨ��V4����ִ��U3��U2�Ƶá�
��InnoDB��ζ����Ǹ���100G������?
�����ظ�������,һ����������ʱ,�ܹ������������ύ������������֮��,������ִ���ڼ�,��������ĸ��¶������ɼ���
���,һ������ֻ��������ʱ˵,��������ʱ��Ϊ:
- ��һ�����ݰ汾����������ǰ����,����
- �����������,�Ҳ���,�ұ���Ҫ�ҵ�������һ���汾�����ϸ��汾Ҳ���ɼ�,�ͼ�����ǰ�ҡ����Ǹ������Լ����µ�����,���Լ�����Ҫ�ϵġ�
��ͼ����
InnoDBΪÿ����������һ������,�Ա������������˲��,��ǰ������Ծ��(������,����δ�ύ)����������ID��
�ڸ�������:
- ����ID����Сֵ,��Ϊ��ˮλ
- ��ǰϵͳ���Ѵ�����������ID�����ֵ��1,��Ϊ��ˮλ
�����ͼ�����ˮλ,������˵�ǰ�����һ������ͼ(read-view)��
�����ݰ汾�Ŀɼ��Թ���,���ǻ������ݵ�row trx_id�����һ������ͼ�ĶԱȽ�����á�
����ͼ���������row trx_id �ֳ�:
- ���ݰ汾�ɼ��Թ���
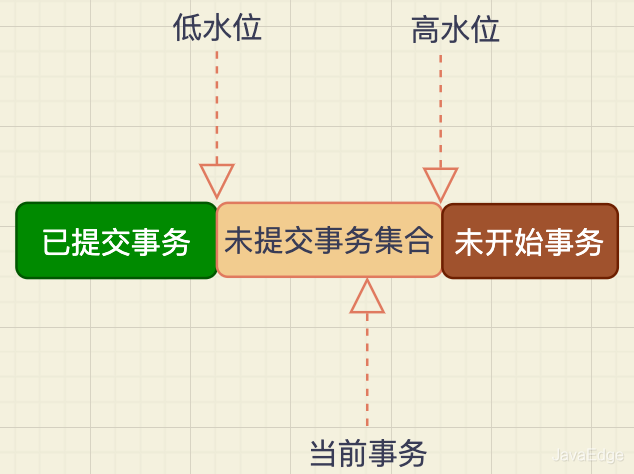
���ڵ�ǰ���������˲��,һ�����ݰ汾��row trx_id,�����¿���:
- ��������ɫ,��ʾ�ð汾�����ύ�������ǰ�����Լ����ɵ�,��������ǿɼ���
- ��������ɫ,��ʾ�ð汾���ɽ����������������ɵ�,�϶����ɼ�
- �����ڻ�ɫ,�����������:
a. �� row trx_id��������,��ʾ�ð汾������δ�ύ���������ɵ�,���ɼ�
b. �� row trx_id����������,��ʾ�ð汾�����ύ���������ɵ�,�ɼ�
����,���ڡ���״̬���ͼ��������,����һ������,���ĵ�ˮλ��18,����������һ������ʱ,�ͻ��V4ͨ��U3�����V3,������������,��һ��ֵ��11��
���˸�������,ϵͳ��������ĸ���,�����������������ˡ���Ϊ֮��ĸ���,���ɵİ汾һ�����������2����3(a),��������˵,��Щ�µ����ݰ汾�Dz����ڵ�,�����������Ŀ���,���ǡ���̬�����ˡ�
����InnoDB�����ˡ��������ݶ��ж�汾��������,ʵ���ˡ��뼶�������ա�������
������,���ǿ�ʼ����һ��ʼ����������
����������
����:
- ����A��ʼǰ,ϵͳ��ֻ��һ����Ծ����ID=99
- ����A��B��C�汾�ŷֱ���100��101��102,�ҵ�ǰϵͳ��ֻ�����ĸ�����
- ��������ʼǰ,(1,1)��һ�����ݵ�row trx_id��90
����:
- ����A����ͼ����[99,100]
- ����B����ͼ������[99,100,101]
- ����C����ͼ������[99,100,101,102]
Ϊ����,�Ȱ������������ȥ��,ֻ����������A��ѯ���йصIJ���:
-
����A��ѯ������ͼ
TODO
-
��һ����Ч����������C,(1,1)=��(1,2)����ʱ,�����ݵ����°汾��row trx_id=102,�汾90�ѳ�Ϊ��ʷ�汾
-
�ڶ�����Ч����������B,(1,2)=��(1,3)����ʱ,�����ݵ����°汾(��row trx_id)=101,�汾102��Ϊ��ʷ�汾
������A��ѯʱ,����B��û���ύ,�������ɵ�(1,3)����汾�Ѿ���ɵ�ǰ�汾��������汾������A�����Dz��ɼ���,����ͱ������ˡ�
��������AҪ����������,������ͼ������[99,100]�������ݶ��Ǵӵ�ǰ�汾����ġ�����,����A��ѯ���Ķ�����������������:
- �ҵ�(1,3)��ʱ��,�жϳ�row trx_id=101,�ȸ�ˮλ��,���ں�ɫ����,���ɼ�
- ����,�ҵ���һ����ʷ�汾,һ��row trx_id=102,�ȸ�ˮλ��,���ں�ɫ����,���ɼ�
- ����ǰ��,�����ҵ���(1,1),����row trx_id=90,�ȵ�ˮλС,������ɫ����,�ɼ�
����ִ������,��Ȼ�ڼ���һ�����ݱ��Ĺ�,��������A������ʲôʱ���ѯ,�����������ݵĽ������һ�µ�,���Գ�֮Ϊһ���Զ���
һ�����ݰ汾,����һ��������ͼ��˵,�����Լ��ĸ������ǿɼ�֮��,�����������:
- �汾δ�ύ,���ɼ�
- �汾���ύ,����������ͼ�������ύ��,���ɼ�
- �汾���ύ,����������ͼ����ǰ�ύ��,�ɼ���
����,����������Щ�����жϲ�ѯ���,����A�IJ�ѯ������ͼ������������A����ʱ���ɵ�,��ʱ:
- (1,3)��û�ύ,����case1,���ɼ�
- (1,2)��Ȼ�ύ��,��ȴ����ͼ���鴴��֮���ύ,����case2,���ɼ�
- (1,1)������ͼ���鴴��֮ǰ�ύ��,�ɼ�
����ֻ��ͨ��ʱ���Ⱥ�������ɡ�
������
����B��update���,����һ���Զ�,������������?
�㿴��ͼ,����B����ͼ�����������ɵ�,֮������C���ύ,����Ӧ�ÿ�����(1,2)��,��ô�����(1,3)?
������B�ڸ���ǰ��ѯһ������,�ò�ѯ���ص�k��ֵȷʵ��1��
������Ҫȥ��������ʱ,�Ͳ���������ʷ�汾�ϸ�����,��������C�ĸ��¾Ͷ�ʧ�ˡ����,����B��ʱ��set k=k+1����(1,2)�Ļ����Ͻ��еIJ�����
����,�����õ�����:�������ݶ����ȶ���д�������,ֻ�ܶ���ǰ��ֵ,��Ϊ����ǰ����(current read)��
���,�ڸ���ʱ,��ǰ���õ���������(1,2),���º��������°汾����(1,3),����°汾��row trx_id��101��
����,��ִ������B��ѯ���ʱ,һ���Լ��İ汾����101,�������ݵİ汾��Ҳ��101,���Լ��ĸ���,����ֱ��ʹ��,���Բ�ѯ�õ���k��ֵ��3��
��ǰ��(current read)
����update�����,select���������,Ҳ�ǵ�ǰ����
����,��������A�IJ�ѯ���
select * from t where id=1
����lock in share mode �� for update,���ɶ����汾����101������,���ص�k��ֵ��3��
mysql> select k from t where id=1 lock in share mode;
mysql> select k from t where id=1 for update;
��������C���������ύ��,���DZ�������������C��,����ô����?
- ����A��B��C����ִ������

����C����ͬ���ڸ��º�û�������ύ,�����ύǰ,����B�ĸ�������ȷ����ˡ�ǰ��˵����,��Ȼ����C����û�ύ,��(1,2)����汾Ҳ�Ѿ�������,�����ǵ�ǰ�����°汾��
������B�ĸ���������ô������?
��������Э�顱������C��û�ύ,��(1,2)����汾�ϵ�д����û�ͷš�������B�ǵ�ǰ��,����Ҫ�����°汾,���ұ������,��˾ͱ���ס��,����ȵ�����C���ͷ������,���ܼ������ĵ�ǰ����
- ����B������ͼ(�������C��)
TODO
����,һ���Զ�����ǰ���������ʹ������ˡ�
�������ʵ�ֿ��ظ���?
- ���ظ����ĺ��ľ���һ���Զ�(consistent read)
- �������������ʱ,ֻ���õ�ǰ��
����ǰ�ļ�¼����������������ռ��,����Ҫ�������ȴ���
���ύ�Ϳ��ظ�����������,����Ҫ������:
- ���ظ���,ֻ��Ҫ������ʼʱ����һ������ͼ,֮���������������ѯ�����ø�һ������ͼ
- ���ύ,ÿ�����ִ��ǰ�����������һ������ͼ
���ڶ��ύ���뼶����,����A������B�IJ�ѯ���鵽��k,�ֱ�Ӧ���Ƕ�����?
start transaction with consistent snapshot;
����˼�Ǵ������俪ʼ,����һ���������������һ���Կ��ա�����,�ڶ��ύ���뼶����,����÷���û������,��Ч����ͨ��start transaction��
�����Ƕ��ύʱ��״̬ͼ,���Կ�����������ѯ���Ĵ�����ͼ�����ʱ�������˱仯,����ͼ�е�read view��(ע��:����,�����õĻ�������C����ֱ���ύ,����������C��)
ͼ8 ���ύ���뼶���µ�����״̬ͼ
��ʱ,����A�IJ�ѯ������ͼ��������ִ���������ʱ����,ʱ����(1,2)��(1,3)������ʱ�䶼�ڴ��������ͼ�����ʱ��֮ǰ������,�����ʱ��:
(1,3)��û�ύ,�������1,���ɼ�;
(1,2)�ύ��,�������3,�ɼ���
����,��ʱ������A��ѯ��䷵�ص���k=2��
��Ȼ��,����B��ѯ���k=3��
�ܽ�
InnoDB���������ж���汾,ÿ�����ݰ汾���Լ���row trx_id,ÿ���������������Լ���һ������ͼ����ͨ��ѯ�����һ���Զ�,һ���Զ������row trx_id��һ������ͼȷ�����ݰ汾�Ŀɼ��ԡ�
- ���ڿ��ظ���
��ѯֻ��������������ǰ���Ѿ��ύ��ɵ����� - ���ڶ��ύ
��ѯֻ�������������ǰ���Ѿ��ύ��ɵ����� - ��ǰ��
���Ƕ�ȡ�Ѿ��ύ��ɵ����°汾
Ϊʲô���ṹ��֧�֡����ظ�����?
��Ϊ���ṹû�ж�Ӧ��������,Ҳû��row trx_id,���ֻ����ѭ��ǰ��������
��Ȼ,MySQL 8.0�Ѿ����ѱ��ṹ����InnoDB�ֵ�����,Ҳ���Ժ��֧�ֱ��ṹ�Ŀ��ظ�����
cs