R语言与数据分析练习:创建和使用R语言数据集&数据的导入导出
实验一 创建和使用R语言数据集
一、实验目的:
-
了解R语言中的数据结构。
-
熟练掌握他们的创建方法,和函数中一些参数的使用。
-
对创建的数据结构进行,排序、查找、删除等简单的操作。
二、实验内容:
1、向量的创建及因子的创建和查看
有一份来自澳大利亚所有州和行政区的20个税务会计师的信息样本1 以 及他们各自所在地的州名。州名为:tas, sa, qld, nsw, nsw, nt, wa, wa, qld, vic, nsw, vic, qld, qld, sa, tas, sa, nt, wa, vic。
手动创建州名txt文件
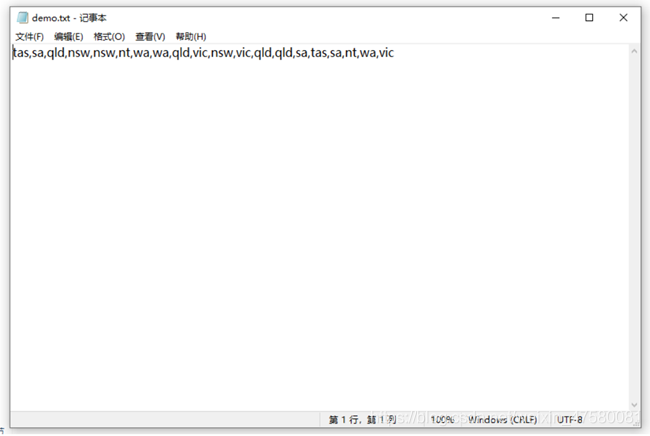
1) 将这些州名以字符串的形式保存在state当中
# 1 用read.table函数导入txt文件
setwd("D:/bigdata/R语言与数据分析/data06/")
data = read.table("./demo.txt",sep=",")
# 2 将这些州名以字符串的形式保存在state当中
state = c(t(data))
print(state)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-wSwlANcI-1617800863149)(C:\Users\John\AppData\Roaming\Typora\typora-user-images\image-20210407204036154.png)]](http://style.iis7.com/uploads/2021/07/14244721944.png)
2) 创建一个为这个向量创建一个因子statef
# 3 创建一个为这个向量创建一个因子statef
statef <- factor(state)
3) 使用levels函数查看因子的水平
# 4 使用levels函数查看因子的水平
print(levels(statef))
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Wc9ThmY8-1617800863150)(C:\Users\John\AppData\Roaming\Typora\typora-user-images\image-20210407204229664.png)]](http://style.iis7.com/uploads/2021/07/14244821945.png)
2、矩阵与数组。
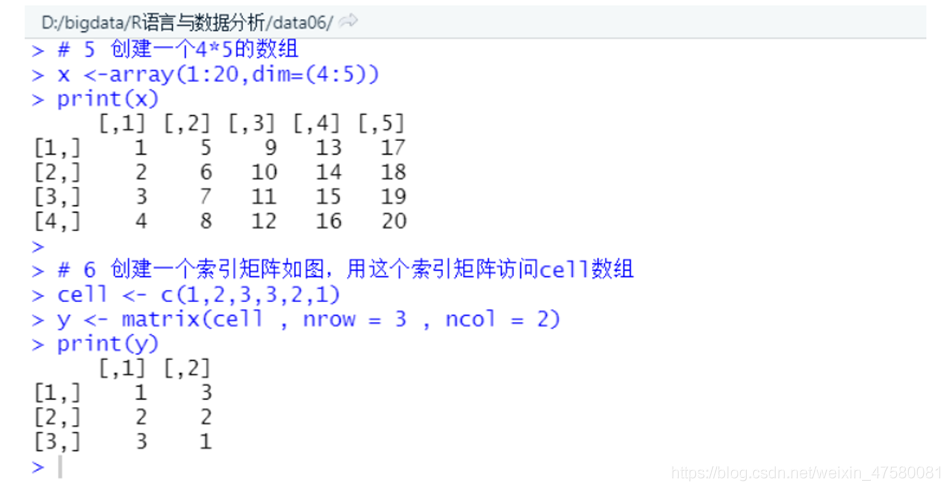
? i. 创建一个4*5的数组如图,创建一个索引矩阵如图,用这个索引矩阵访问数组,观察结果。

# 5 创建一个4*5的数组
x <-array(1:20,dim=(4:5))
print(x)
# 6 创建一个索引矩阵如图,用这个索引矩阵访问cell数组
cell <- c(1,2,3,3,2,1)
y <- matrix(cell , nrow = 3 , ncol = 2)
print(y)
3、将之前的state,数组,矩阵合在一起创建一个长度为3的列表。
# 7 将之前的state,数组,矩阵合在一起创建一个长度为3的列表
mixList <- list(state,x,y)
print(mixList)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-i8Cj1caV-1617800863156)(C:\Users\John\AppData\Roaming\Typora\typora-user-images\image-20210407204716283.png)]](http://style.iis7.com/uploads/2021/07/14244821948.png)
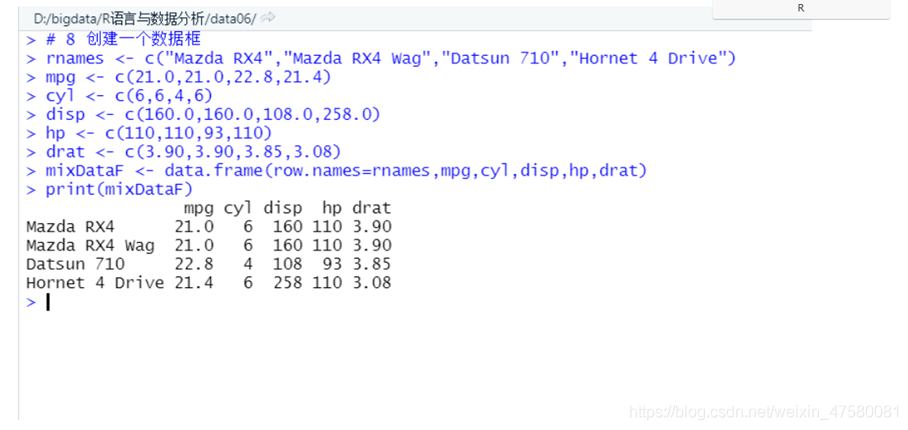
4、创建一个数据框如图。

# 8 创建一个数据框
rnames <- c("Mazda RX4","Mazda RX4 Wag","Datsun 710","Hornet 4 Drive")
mpg <- c(21.0,21.0,22.8,21.4)
cyl <- c(6,6,4,6)
disp <- c(160.0,160.0,108.0,258.0)
hp <- c(110,110,93,110)
drat <- c(3.90,3.90,3.85,3.08)
mixDataF <- data.frame(row.names=rnames,mpg,cyl,disp,hp,drat)
print(mixDataF)
5、将这个数据框按照mpg列进行排序。
# 9 将这个数据框按照mpg列进行排序
ordermixDataF <- mixDataF[order(mixDataF$mpg),]
print(ordermixDataF)

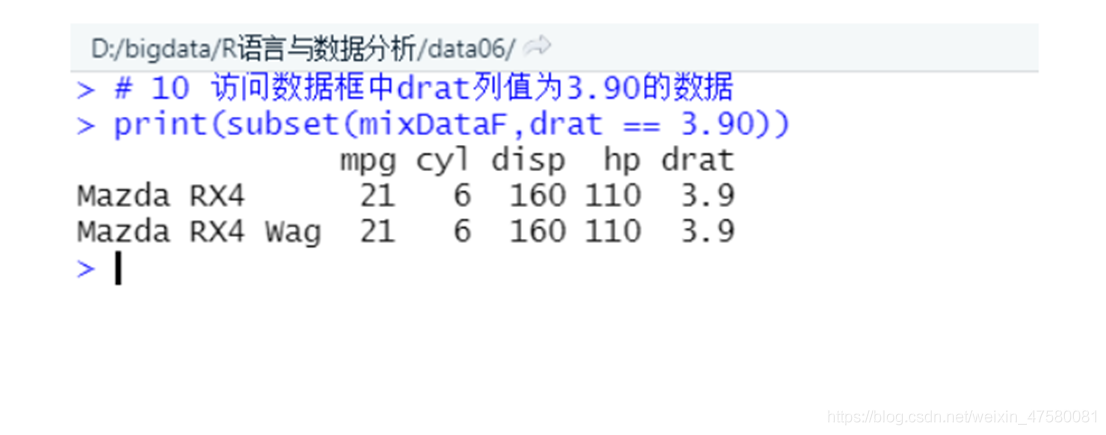
6、访问数据框中drat列值为3.90的数据。
# 10 访问数据框中drat列值为3.90的数据
print(subset(mixDataF,drat == 3.90))
三、实验要求
要求熟练掌握向量、矩阵、数据框、列表、因子的创建和使用。
四、实验总结
通过对实验过程中重难点进行说明,对实验过程中的缺点不足的阐述,明确以后努力和改进的方向。
实验二 数据的导入导出
一、实验目的
-
熟练掌握从一些包中读取数据。
-
熟练掌握csv文件的导入。
-
创建一个数据框,并导出为csv格式。
二、实验内容
1、创建一个csv文件(内容自定),并用readtable函数导入该文件。
手动创建csv文件
| id | name | gender |
|---|
| 1001 | John | Male |
| 1002 | yuyu | Female |
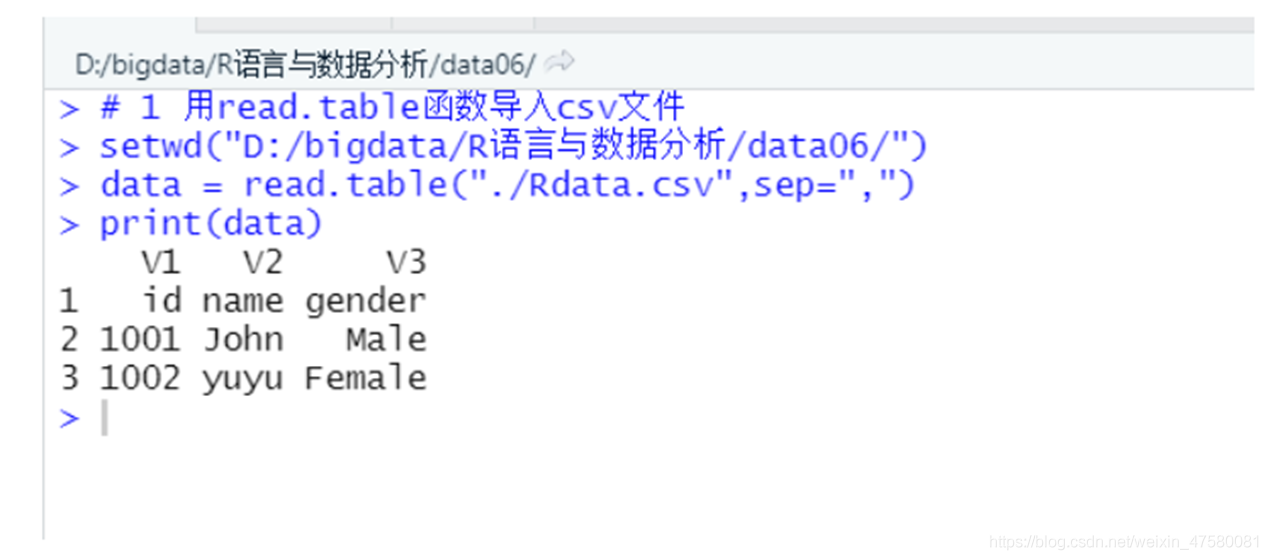
# 1 用read.table函数导入csv文件
setwd("D:/bigdata/R语言与数据分析/data06/")
data = read.table("./Rdata.csv",sep=",")
print(data)
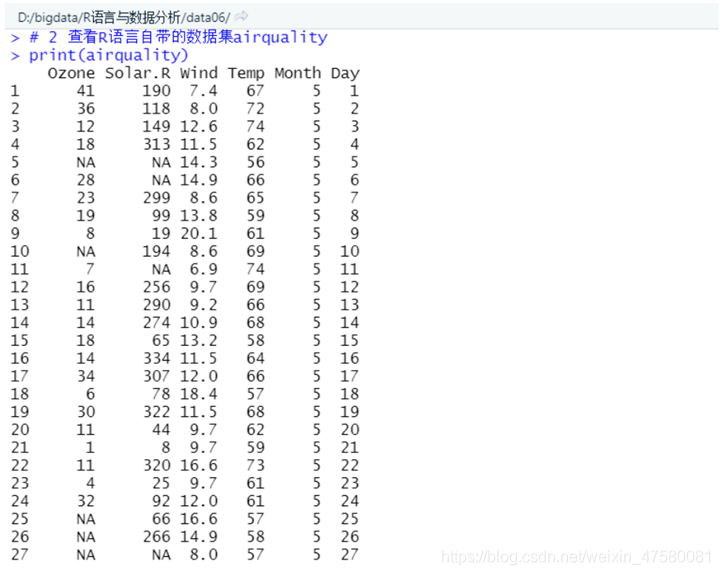
2、查看R语言自带的数据集airquality(纽约1973年5-9月每日空气质量)。
# 2 查看R语言自带的数据集airquality
print(airquality)
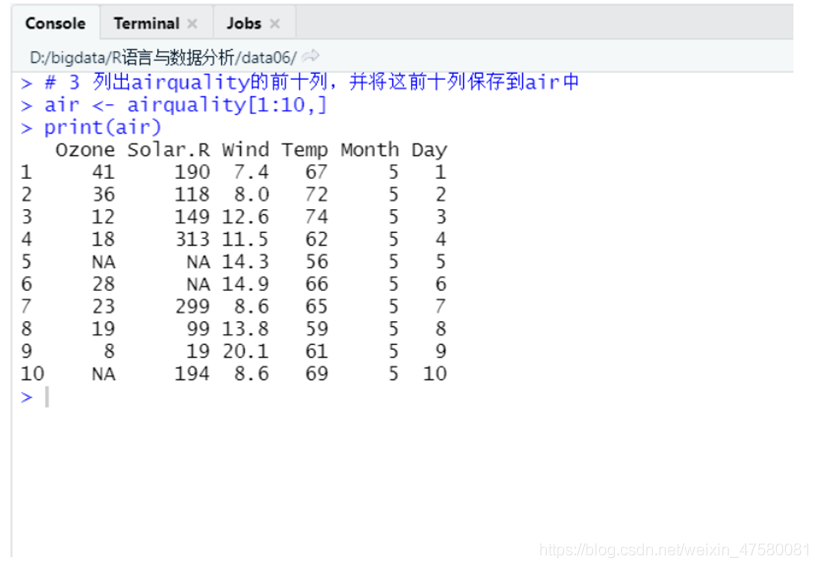
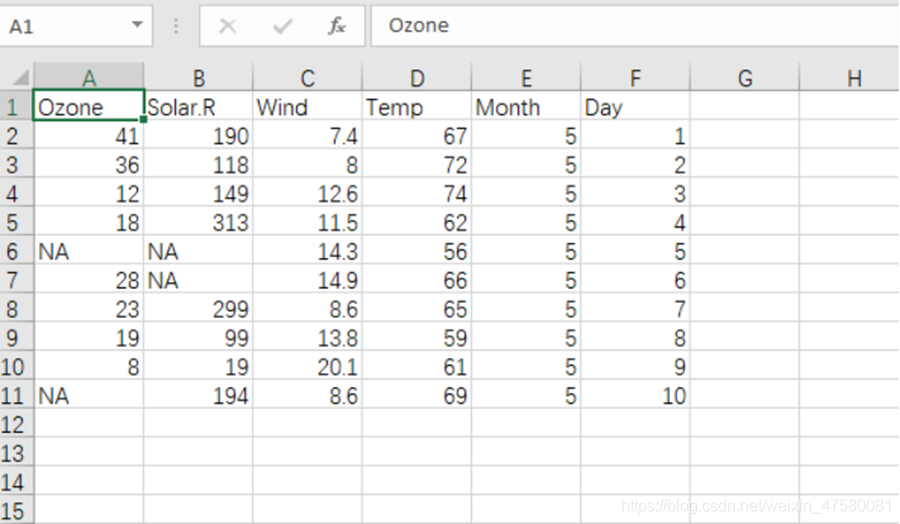
3、列出airquality的前十列,并将这前十列保存到air中。
# 3 列出airquality的前十列,并将这前十列保存到air中
air <- airquality[1:10,]
print(air)
4、任选三个列,查看airquality中列的对象类型。
# 4 查看airquality中列Ozone,Solar.R,Wind的对象类型
class(airquality$Ozone)
class(airquality$Solar.R)
class(airquality$Wind)

5、使用names查看airquality数据集中各列的名称
# 5 使用names查看airquality数据集中各列的名称
names(airquality)

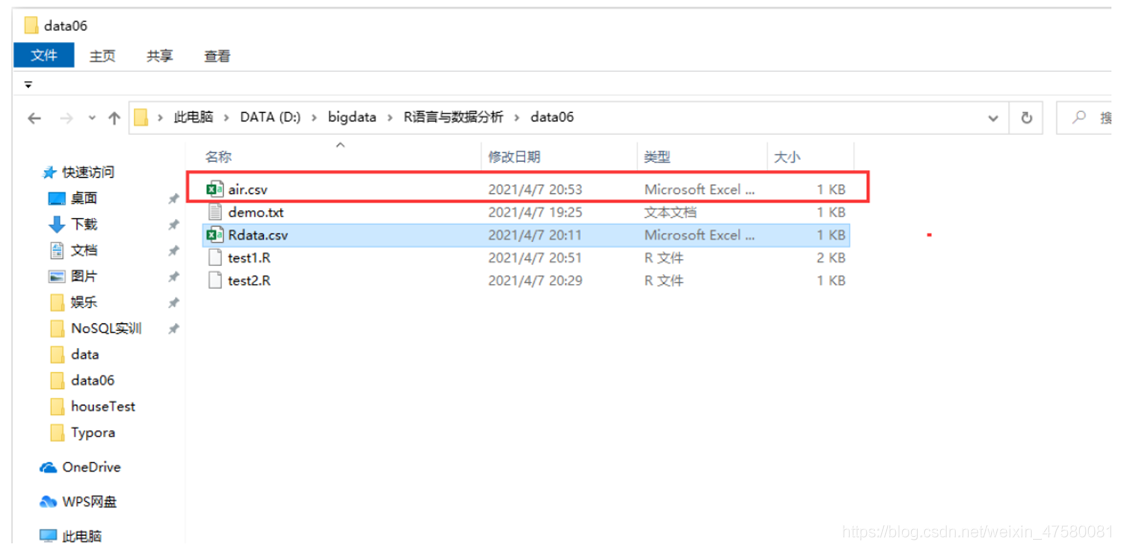
6、将air这个数据框导出为csv格式文件。
(write.table (x, file ="", sep ="", row.names =TRUE, col.names =TRUE, quote =TRUE))
# 6 将air这个数据框导出为csv格式文件
write.table(air, file ="./air.csv" , sep = ",", row.names = FALSE)
cs