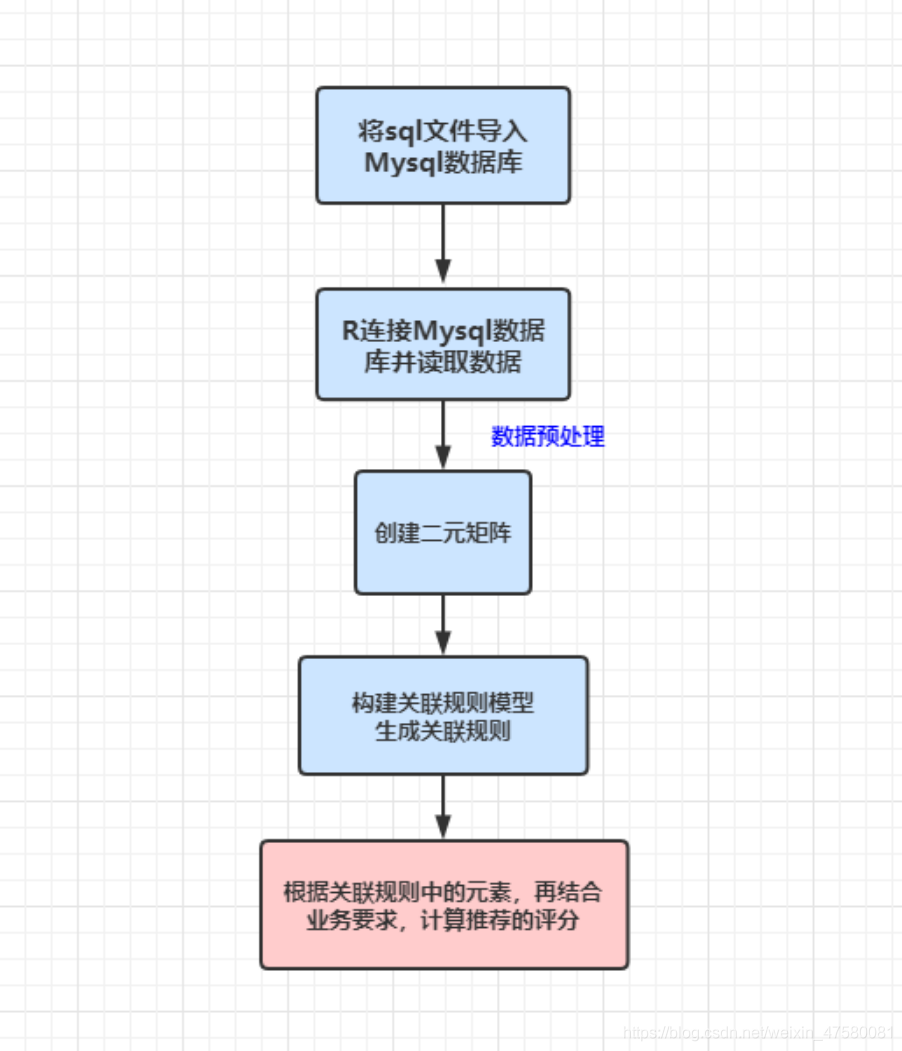
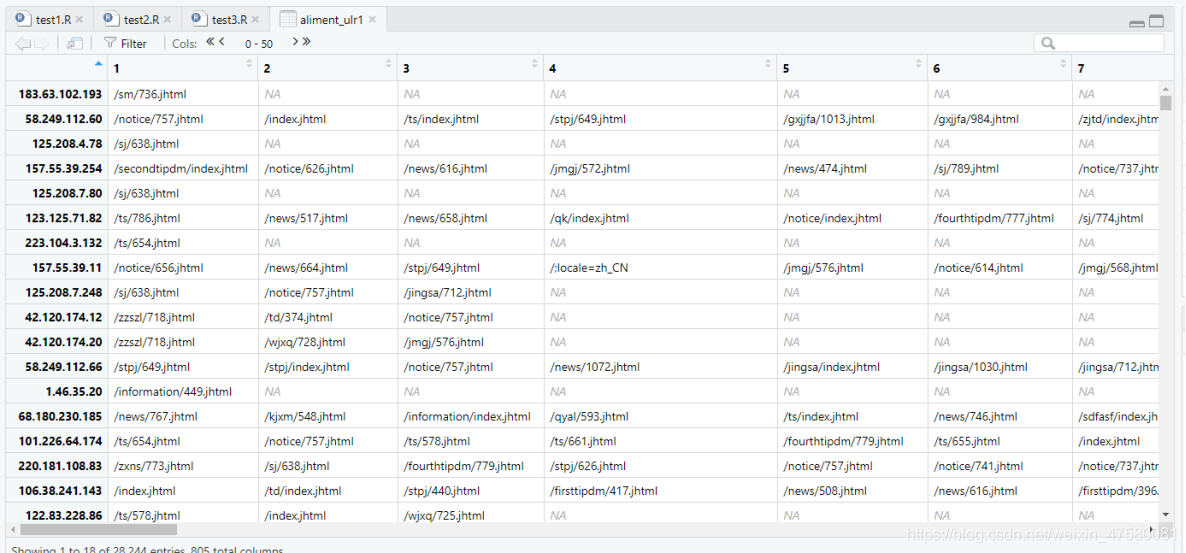
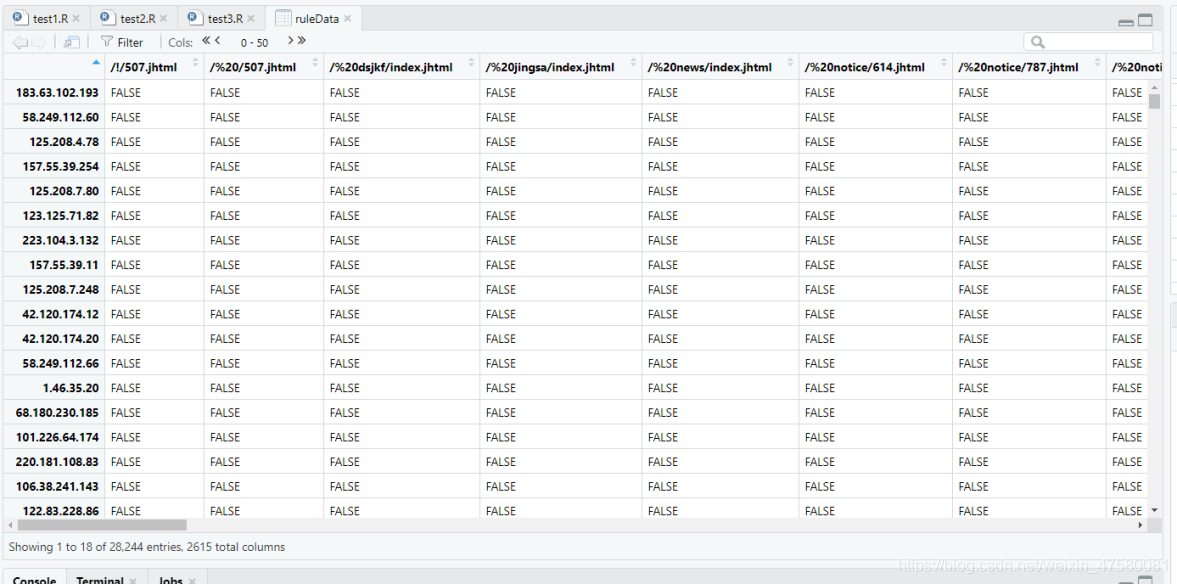
trans <- as(aliment_ulr, "transactions")
rules <- apriori(trans, parameter = list(support = 0.01, confidence = 0.3))
summary(rules)
inspect(sort(rules, by = list('support'))[1:10])
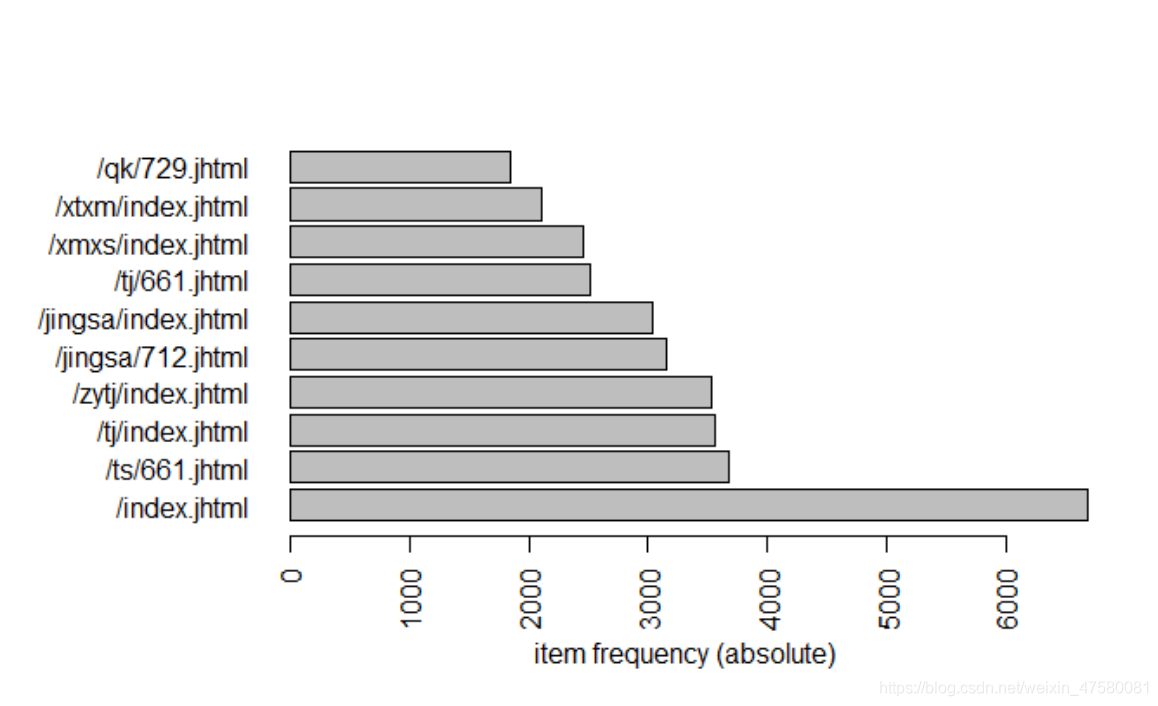
itemFrequencyPlot(trans, type = 'absolute', topN = 10, horiz = T)
write(rules, "./rules.csv", sep = ",", row.names = FALSE)
result <- read.csv("./rules.csv", stringsAsFactors = FALSE)
meal.recom <- strsplit(result$rules, "=>")
lhs <- 0
rhs <- 0
for (i in 1:length(meal.recom)) {
lhs[i] <- gsub("[{|}+\n]|\\s", "", meal.recom[[i]][1])
rhs[i] <- gsub("[{|}+\n]|\\s", "", meal.recom[[i]][2])
}
rules.new <- data.frame(lhs = lhs, rhs = rhs, support = result$support,
confidence = result$confidence, lift = result$lift)
write.csv(rules.new, "./rules_new.csv", row.names = FALSE)
5、根据关联规则模型的因素,计算推荐的综合评分
viemNum_data <- sqldf("select page_path,count(id) as viemSum from data group by page_path")
countryCount_data <- sqldf("select page_path,count(distinct country) as countryNum from data group by page_path")
userCount_data <- sqldf("select page_path,count(distinct ip) as userNumfrom from data group by page_path")
rules.new <- read.csv("./rules_new.csv", stringsAsFactors = FALSE)
A <- matrix(c(0, 2.5, 3, 4,
1.5, 0, 3, 4,
1.5, 2.5, 0, 4,
1.5, 2.5, 3, 0), 4, 4, byrow = T)
E <- c(1, 1, 1, 1)
rules.new$viemNum <- 0
rules.new$countryCount <- 0
rules.new$userCount <- 0
rules.new$mark <- 0
for (i in 1:nrow(rules.new)) {
viemNum.num <- which(viemNum_data$page_path == rules.new$rhs[i])
rules.new$viemNum[i] <- viemNum_data$viemSum[viemNum.num]
userCount.num <- which(countryCount_data$page_path == rules.new$rhs[i])
rules.new$userCount[i] <- countryCount_data$countryNum[userCount.num]
rules.new$countryCount[i] <- userCount_data$userNumfrom[userCount.num]
Y <- c(rules.new$viemNum[i]/10000, rules.new$countryCount[i]/1000,
rules.new$userCount[i]/1000, rules.new$confidence[i])
rules.new$mark[i] <- round((E - Y) %*% A %*% t(t(Y)), 3)
}
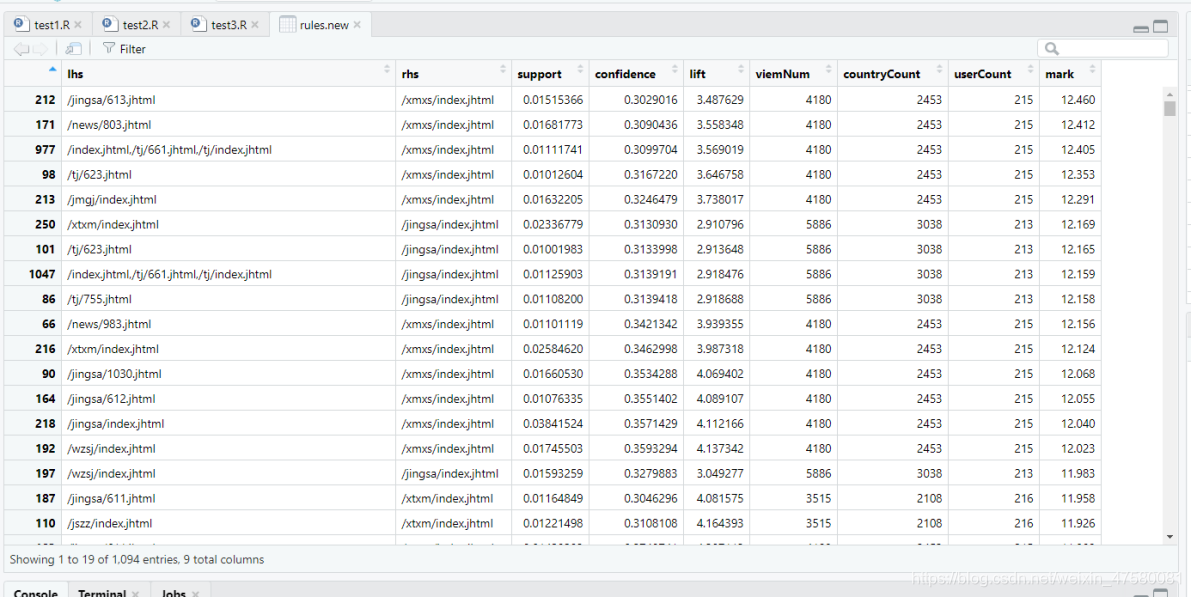
rules.new <- rules.new[order(rules.new$mark, decreasing = TRUE), ]
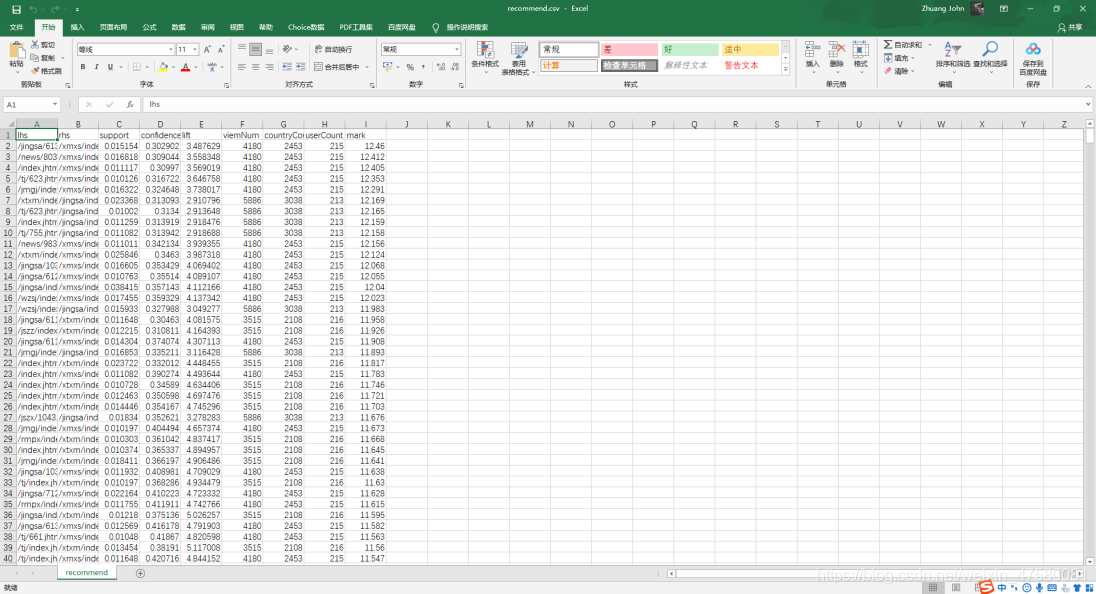
write.csv(rules.new, "./recommend.csv", row.names = FALSE)
五、实验结论:
综合评分分析:
实验中,我求出每个网站对应的访问总数量、地区数量和用户数量,根据综合评分公式对算法进行评分,最后可以根据每个网站对应的访问总数量、地区数量、用户数量以及评分对数据进行业务分析。
预测分析:
从绝对数量中可以看出“/index.jhtml”的访问量最高,对于输出的recommend.csv文件,可以通过设置前项网站或者后项网站,然后根据对应的访问总数量、地区数量、用户数量以及评分对数据进行业务分析,得出给观看前项的用户推荐更符合用户胃口的网站,从而更加高效地提高网站的访问量以及各网站之间的联系!
cs