�������ϵͳ������30��
һ����������ʱ���·
1��CPU�е�ʱ���·
��:
CPU�е�ʱ���·:ͨ��RS����������CPU��ʱ��
2�������ڴ����������
��:
CPU�ڴ���ָ��ʱ,һ����Ҫ�������¼�������:
1)ȡָ��(IF)
���ݳ��������PC�е�ָ���ַ,�Ӵ洢����ȡ��һ��ָ��,ͬʱ,����ָ���ֳ����Զ�����������һ��ָ������Ҫ��ָ���ַ,����������ַת�ơ�ָ��ʱ,��������ѡ�ת�Ƶ�ַ������PC,��Ȼ�õ��ġ���ַ����Ҫ��Щ�任������PC��
2)ָ������(ID)
��ȡָ������еõ���ָ����з���������,ȷ������ָ����Ҫ��ɵIJ���,�Ӷ�������Ӧ�IJ��������ź�,��������ִ��״̬�еĸ��ֲ�����
3)ָ��ִ��(EXE)
����ָ������õ��IJ��������ź�,����ִ��ָ���,Ȼ��ת�Ƶ����д��״̬��
4)�洢������(MEM)
������Ҫ���ʴ洢���IJ������������������ִ��,�ò�������Ĵ洢�������ݵ�ַ,������д�뵽�洢�������ݵ�ַ��ָ���Ĵ洢��Ԫ���ߴӴ洢���еõ����ݵ�ַ��Ԫ�е����ݡ�
5)����(WB)
ָ��ִ�еĽ�����߷��ʴ洢���еõ�������д����Ӧ��Ŀ�ļĴ����С�
������CPU,����һ��ʱ�����������������εĴ�����
3����ˮ�ߴ������Ļ���ԭ��
��:
��ˮ��(Pipeline)������ָ������ִ��ʱ�����ָ���ص����в�����һ�����д���ʵ�ּ�����ͨ�Ľ���һ��ʱ�����,�ֽ�����ɸ��ӹ���,ÿ�����̶�����Ч���������ӹ���ͬʱִ�С�ּ����ߴ���������Ч��,��ȡ��һ��ʱ�����������һ��ָ�
��������֯�ɽ�:ȡָ�����롢ִ�С��ô桢д����ͨ��һ��ָ������ܶ����,���Խ�������֯��һ���Ľ�����,�Ӷ����ڷ���һ��ͨ�ÿ����������ˮ�ߴ�����
�ο�:
��ˮ�ߴ������Ļ���ԭ��:https://blog.csdn.net/pankul/article/details/8769979
4��Data Hazard�Ĵ���
��:
��ˮ�߸�������������Ч��,��ȻҲ�����⡣��Щ�����֮Ϊ��ˮ��ð��(HaZard)��
1)�ṹð��
���ڴ�������Դ��ͻ,����ʵ��ijЩָ���ε����ʵ��,�ͳ�֮Ϊ�������нṹð�ա�
����,����Ĵ�������,����������Ǵ洢��һ���,��ô���׳�����������:�ڵ�һ��Cycle��,IF��MEMͬʱ���ʴ洢��������һ������Ҫ�ȴ�,��ʱhazard�ͳ����ˡ����ڵĴ������Ѿ�����˸�����:ָ��洢��L1P cache��,���ݴ洢��L1D cache��,��������,����Ӱ���������
2)����ð��
�����ˮ����ԭ�����Ⱥ�˳���ָ��ͬһʱ�̴���ʱ,���ܻᵼ�³��ַ����˴�������ݵ������
�ڻ�������,add R1,R2,R3���Ĵ���R2��R3�ĺ���R1,�ı�R1��ֵ;����������������:add R4,R1,R5���ʹ��R1��ֵ,����R1������һ������еĵ�5��cycle���ܸ��µ��Ĵ�����,�������ڵ�4��cycle��Ҫ����R1,Ҳ����˵�ڶ���ָ���ʱ��ʹ�ô����R1��ֵ,��������hazard�����ˡ�
�������:������ָ��������һ����ָ��:nop�����ǻ�Ӱ�촦������ָ���ִ��Ч�ʡ����ִ�������������,�Ѿ���forwarding�ķ�ʽ����ˡ�����ͼ(ûͼ�����ȷ��Ű�???)����������ڼ���ǰ��Դ��������������ˮ�ߵ�EX����MEM��,ֱ�ӽ�EX��MEM�Ĵ�����ֵ���ݸ�ALU������,�������ٴӼĴ������л�ȡ�����ˡ���˴�ʱ�Ĵ������е����ݿ�����û�б���ʱ���µġ�
3)����ð��
**����ˮ���е�ִ��ָ��ʱ,���ڲ��д����Ĺ�ϵ,����ܶ�ָ����ʵ������ˮ���п�ʼ������,����Ԥȡֵ�����롣��ô,�����ʱ�����г���һ����ת������ô����?**��Ϊ�����Ѿ��ܵ�������ַ��ִ��,��ˮ����֮ǰ�Ѿ����õ�Ԥȡֵ�����붯��������ʹ���ˡ���Щ�ᱻ��������ר�в���flush��,���¿�ʼ�µ���ˮ�ߡ���ʱ���ǿ��Գ�֮Ϊ�����˿���ð�ա�����������ڳ����Ч����ˮ�Ǵ��ںܴ����ʧ�ġ�
�������:Ҳ������jumpָ�����(���ᱻ����ʹ��,���ǻ������ˮ��)����nop����MIPS������,������jumpָ���������nop��䡣
��x86�ܹ���,��ͨ��Ӳ����ʵ��flush,����Ч����ˮ���ſ�,�Ա�֤��ȷ������ˮ�ߡ�������漰����֧Ԥ�⼼����ʹ�á�
������һЩ��������,�������ķ�ʽ������,����nop��ͬʱ�ڱ�������ͨ�������˼������Чָ�����nop������Ҳ���Ա�����ת������������ʧ��
5����ˮ������е���������
��:
1)ÿ�������õ�Ӳ��ʵ�ʲ����ǻ��������;���ӵļĴ���Ҳ�ᵼ���ӳ�����;ÿ�ε����ڻ���Ҳ��������һ�¡�
2)�������ˮ��ϵͳ,ÿ���ε�ʱ�䶼����ȵġ�ʵ����,�����ε�ʱ���Dz��ȵġ�����ʱ�����������Ľξ����ġ�
3)������ˮ�߹���,�Ĵ��������ӻ�����ӳ������ӳ�����ʱ�����ڵ�һ��������,Ҳ���Ϊ��ˮ����������һ����Լ���ء�
�����Ż���������
1���Ż���������
��:
1)�����Ż��ĵ�һ��������������Ҫ������,�ô��뾡������Ч��ִ���������Ĺ������������������Ҫ�ĺ������á��������Ժʹ洢�����á���Щ�Ż���������Ŀ��������κξ������ԡ�
2)�����Ż��ĵڶ���,���ô������ṩ��ָ���������,ͬʱִ�ж���ָ����
3)���Դ��ͳ�����Ż�,ʹ�ô�����������,�������������Dz�����������������ܵĹ���,���ַ����ܹ������ҵ������е�Ч�ʵĵط�,����ȷ��������Ӧ�������Ż��IJ��֡�
4)Amdahl����,�������˶�ϵͳij�����ֽ����Ż�������������Ч����
2���Ż��������������;������Լ���ʾ��������
��:csapp chapter5 p325
�Ż�������������:
�ִ����������ø��Ӿ��ܵ��㷨��ȥ��һ�������м������ʲôֵ,�Լ������DZ����ʹ�õġ�Ȼ�����ǻ�����һЩ����������ʽ,�ڼ�����ͬ�ĵط�ʹ��ͬһ������,�Լ�����һ�������ļ�����뱻ִ�еĴ�����
�Ż��������ľ�����:
�����������С�ĵضԳ���ֻ���ð�ȫ���Ż�,Ҳ���Ƕ��ڳ���������������п��ܵ����,��C���Ա��ṩ�ı�֤֮��,�Ż���õ��ij����δ�Ż��İ汾��һ������Ϊ,���Ʊ�����ֻ���а�ȫ���Ż�,������һЩ��ɲ�ϣ��������ʱ��Ϊ�Ŀ���ԭ��,������Ҳ��ζ�ų���Ա���뻨�Ѹ��������д������ʹ�������ܹ���֮ת������Ч��������,����ָ�����ָ��ͬһ���洢��λ�õ������Ϊ�洢������ʹ��(memory aliasing)���������һ����Ҫ�ķ����Ż�������,��Ҳ�ǿ����������Ʊ����������Ż��������ij����һ������:�������������ȷ������ָ���Ƿ�ִ��ͬһ��λ��,�ͱ������ʲô������п���,�����˿��ܵ��Ż����ԡ�
��ʾ��������:
���������ÿԪ�ص�������(Cycles Per Element CPE),��Ϊһ�ֱ�ʾ�������ܲ�ָ�����ǸĽ�����ķ���������С�������,�õ�һ������y=mx+b����,�������ӵ�ϵ��m����ÿ��Ԫ�ص�������CPE����Ч��
3���ض���ϵ�����Ӧ�����Ե������Ż�
��:
1)��ʹ��������ѡ��,�确-O1���ͻ����һЩ�������Ż�
2)����ѭ���ĵ�Ч��:����"�����ƶ�",�����Ż�����ʶ��Ҫִ�ж��(������ѭ����)���Ǽ���������ı�ļ���,����������ƶ�������ǰ�治��ȶ����ֵ�IJ���
3)���ٹ��̵���:�Ĵ�����ٺ����ĵ���,������Σ��һЩ�����ģ����
4)ѭ��չ��:ͨ������ÿ�ε��������Ԫ�ص�����,����ѭ���ĵ����������Ӷ���������ij��������,�����������˲�ֱ�������ڳ������IJ���������,����ѭ�����������������֧�����,���ṩ��һЩ����,���Խ�һ���仯����,�������������йؼ�·���ϵIJ�������
5)��߲�����:����ۼƱ���;���½�ϱ任
4����������
1)�Ĵ������
ѭ�������Եĺô��յ���������Ļ�������������ơ��ر��,IA32ָ�ֻ�к������ļĴ�������Ż��۵�ֵ(IA32ֻ��4��,x86-64����12��)��������ǵIJ��ж�p�����˿��õļĴ�������,��ô���������������(spilling),��ijЩ��ʱֵ��ŵ�ջ�С�һ�������������,���ܻἱ���½���
2)��֧Ԥ���Ԥ�����
����֧Ԥ����������ȷԤ��һ����֧�Ƿ�Ҫ��ת��ʱ��,������֧���ܻ��������ص�Ԥ�������
3)�����������û�мĴ�,��һЩͨ��ԭ��
(1)��Ҫ���ֹ�ϵ��Ԥ���֧
(2)��д�ʺ�����������ʵ�ֵĴ���
5��ȷ�Ϻ���������ƿ��
��:
���������ʱ��ָ�����Ż�ʲô�ط���������
1)��������
���������������г����һ���汾,���в����˹��ߴ���,��ȷ������ĸ���������Ҫ����ʱ��,�����ȷ����Ҫ����ע�����Ż��IJ��ֺ�����,����һ������ָ�����ڿ�������ʵ�Ļ�����������ʵ�ʳ����ͬʱ,��������(Unixϵͳ�ṩ��һ����������GPROF)��ͨ��,�������д����Ե����������г���,�����ܰ������ǶԵ��͵���������Ż�,�������ǻ�Ӧ��ȷ�������п��ܵ����,�������൱�����ܡ�����Ҫ��������õ����Ľ������ܵ��㷨(��������㷨)�ͻ��ı��ʵ����
2)Amdahl����(��ķ�������)
����Ҫ˼���������Ǽӿ�ϵͳһ���ֵ��ٶ�ʱ,��ϵͳ�������ܵ�Ӱ����������������ж���Ҫ���ٶ�����˶�����
��ķ����������ڲ��д���ϵͳ���о������ڹ̶�����������������д���Ч���ļ��ٱ�s,��ķ������������о����������¹�ʽ:
S=1/(1-a+a/n)
����,aΪ���м��㲿����ռ����,nΪ���д���������������,��1-a=0ʱ,(��û�д���,ֻ�в���)�����ٱ�s=n;��a=0ʱ(��ֻ�д���,û�в���),��С���ٱ�s=1;��n����ʱ,�����ٱ�s�� 1/(1-a),��Ҳ���Ǽ��ٱȵ����ޡ�����,�����д���ռ���������25%,���д������������ܲ����ܳ���4����һ��ʽ�ѱ�ѧ����������,������������ķ������ɡ�,Ҳ��Ϊ�������������(Amdahl law)��

�����洢���ṹ������洢��
1���ֲ���
��:
һ����д���õļ��������ͨ���������õľֲ��ԡ�
�����ٽ�������������õ��������������,����������ù����������������������,����Ϊ�ֲ���ԭ����
�ֲ���������ʽ:
ʱ��ֲ���:�����ù�һ�ε��ڴ�λ�ú��п����ڲ�Զ�Ľ����ٱ��������(ͨ����ѭ����)��
�ռ�ֲ���:һ���ڴ�λ�ñ�������һ��,��ô������������λ��Ҳ�ᱻ������
�ֲ��Ժ����ܵĹ�ϵ
1)�����þֲ��Եij���Ⱦֲ��Բ�ij������еø��졣
2)�ֲ���ԭ����������������ͨ�������Ϊ���ٻ���洢����������������õ�ָ���������,�Ӷ���߶�����ķ����ٶȡ�
3)�ظ�������ͬ�����ij��������õ�ʱ��ֲ���
4)���ھ��в���Ϊk������ģʽ�ij���,����ԽС,�ռ�ֲ���Խ�á�
5)���в���ΪI������ģʽ�ij�����кܺõĿռ�ֲ��ԡ�
6)���ڴ����Դ�������ȥ�ij���ռ�ֲ��Ի�ܲ
7)����ȡָ����˵,ѭ���кõ�ʱ��Ϳռ�ֲ��ԡ�
8)ѭ����ԽС,ѭ����������Խ��,�ֲ���Խ�á�
2���洢����νṹ
��:
�������Ŵ������ʹ洢�������ܷ�չ�ϵIJ���Խ��Խ��,�洢�������������Ƿ����ӳٷ������������Խ��Խ�����ϴ��������ܷ�չ����Ҫ��Ϊ����С�洢���ʹ���������֮�������ܷ���IJ��,ͨ���ڼ�����ڲ����ò�λ����洢����ϵ�ṹ��
���Կ���,�ٶ�Խ��������ԽС��Խ����CPU��CPU����ֱ�ӷ����ڲ��洢��,���ⲿ�洢������Ϣ��Ҫ��ȡ����,Ȼ����ܱ�CPU���ʡ�CPUִ��ָ��ʱ,��Ҫ�IJ������ֶ����ԼĴ���;����Ҫ��(��)�洢����ȡ(��)����ʱ,�ȷ���cache,�������cache��,���������,�������������,�����Ӳ��,��ʱ,��������Ӳ���ж����͵�����,Ȼ��������͵�cache,����ʹ��ʱһ��ֻ����������֮�临�ƴ���,�������Ǵ����ٴ洢�����Ƶ����ٴ洢�������͵ĵ�λ��һ��������,�����Ҫȷ��������Ĵ�С,������������佨����֮���ӳ���ϵ��
3����������ٻ�����ԭ��
��:
�ӿ�CPU�����ٶȵ���Ҫ��ʽ֮һ����CPU������֮�����Ӹ��ٻ���洢��(��Ƹ��ٻ������cache)��
cache��һ��С�������ٻ���洢��,�ɿ��ٵ�SRAM���,ֱ��������CPUоƬ��,�ٶȽϿ�,������CPU����ͬһ��������
��CPU������֮������cache,��ʦ�������б�Ƶ�����ʵĻ�Ծ���������ݿ鸴�Ƶ�cache�С����ڳ�����ʵľֲ���,����������,CPU��ֱ�Ӵ�cache��ȡ��ָ�������,�����ط������ٵ����档
Ϊ����cache������佻����Ϣ,cache������ռ䶼������Ϊ��ȵ�����
����,�����水��ÿ512�ֽڻ��ֳ�һ������,ͬʱ��cacheҲ���ֳ�ͬ����С������,���������е���Ϣ�Ϳ�����512�ֽ�Ϊ��λ�͵�cache�С�
���ǰ������е������Ϊ��,Ҳ��Ϊ�����,����cache������֮�����Ϣ������λ;cache�д��һ�������������Ϊ�л��,Ҳ��Ϊcache�С�
4�����ٻ�������ܵ�Ӱ��
��:
Ӱ��cache���ܵ����ؾ���ϵͳ�������ܵ���Ҫ����֮һ��cache������,�������������йء�
1)��������������й�
������Խ��,������Խ���������ȷ�ӳһ��������Ӧ��cache�еĸ���,��Ȼ,ֱ��ӳ��Ĺ�����Ϊ1;2·������ӳ��Ĺ�����Ϊ2,4·������ӳ��Ĺ�����Ϊ4,ȫ����ӳ��Ĺ�����Ϊcache������
2)��������cache�����й�
cache����Խ��,�����ʾ�Խ����
3)�������������Ĵ�С�й�
���ô�Ľ�����λ�ܺܺõ����ÿռ�ֲ���,���ǽϴ���������Ҫ���ѽ϶��ʱ������ȡ,���,ȱʧ��ʧ�����ɴ˿ɼ�,�����Ĵ�С��������,����̫��,Ҳ���ܴ�С��
����,���cacheʱ��Ҫ����һ������:
���õ������Ƕ༶cache������cache��ָ��cache�Ƿֿ����Ǻ���һ������-����-cache�CCPI֮�����ʲô�ܹ�����������DRAMоƬ���ڲ��ṹ���洢�����ߵ������������͵�,Ҳ����cache����й�,����Ӱ��ϵͳ�������ܡ�
�������Щ������м���˵��:
Ŀǰcache�����϶���CPUоƬ��,��ʹ��L1��L2cache,����L3cache,CPU�ķ���˳��ΪL1cache��L2cache��L3cache��
ͨ��L1cache���÷���cache,������cache��ָ��cache�ֿ�����,�ֱ������ݺ�ָ�ָ��cache��ʱ��Ϊ����cache(code cache)��L2cache��L3cacheΪ����cache,�����ݺ�ָ�����һ��cache�С�
���ڶ༶cache�и���cache������λ����,ʹ�ö����ǵ����Ŀ��������ͬ������ٶ�������cache����ô,����L1cache,ͨ������ע�ٶȶ���Ҫ���кܸߵ�������,��Ϊ,��ʹ������,�����Ե�L2cache,L2cache���ٶȱ������ٶȿ�Ķ�;������L2cache,��Ҫ���������������,��Ϊ��������,����뵽���ٵ������з���,��ȱʧ��ʧ��ܴ��Ӱ���������ܡ�
5����ַ�ռ�
��:
ÿ��������Դ�����롢��ࡢ���ӵȴ������ɿ�ִ�еĶ�����Ŀ�����ʱ,����ӳ�䵽ͬ���������ַ�ռ�,���,���н��̵������ַ�ռ���һ�µ�,���������������ƺ�ʵ��,Ҳ���˳���ļ��ع��̡�
����洢����Ϊ�����ṩ��һ������������ַ�ռ�(Ҳ��Ϊ����ַ�ռ�),��������ʹ��̴洢���ij��������ƴ�����һ������,ʹ��ÿ�����̶�����ռʹ������,��������ռ伫��
���������ô�:
1)ÿ�����̾���һ�µ������ַ�ռ�,�Ӷ����Լ洢����
2)�������濴���Ǵ��̴洢����һ������,�������н����浱ǰ��ij���κ�������,��������Ҫ�ڴ��̺�����֮�������Ϣ����,ʹ��������ռ�õ�����Ч����
3)ÿ�����̵������ַ�ռ���˽�е�,���,���Ա������Խ��̲������������ƻ���
6������洢��
��:
һ��ϵͳ�еĽ��������������̹���CPU��������Դ��,Ȼ��,����������γ�һЩ��������,���̫��Ľ�����Ҫ̫��Ĵ洢��,��ô�����е�һЩ���������С���һ������û�пռ���õ�ʱ��,�Ǿ������������á��洢�������ױ��Ⱥ�,���һ�����̲�С��д������һ������ʹ�õĴ洢��,���Ϳ���ʧȥԭ�ȵ�����Ϊ�˸���Ч�Ĺ����洢��,����ϵͳ������һ�ֶ�����ij������,��������洢����
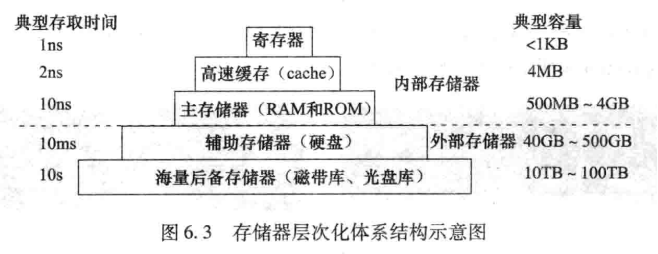
Ŀǰ,�ڷ�������̨ʽ���ͱʼDZ��ȸ���ͨ�ü����ϵͳ�ж���������洢�������ڲ�������洢�����ļ������,ָ��ִ��ʱ,ͨ���洢����������(Memory Management Unit,���MMU)��ָ���е�����ַ(Ҳ�������ַ�����ַ,��дΪVA)ת��Ϊ�����������ַ(Ҳ�������ַ��ʵ��ַ,��дΪPA)���ڵ�ַת����������Ӳ������Ƿ����˷�����Ϣ����������ַԽ������ԽȨ,���ɲ���ϵͳ������Ӧ���쳣�������ɴ˿��Կ���,����洢�����Ƚ���˱�̿ռ���������,�ֽ���˶����������������İ�ȫ���⡣
��ͼ�Ǿ�������洢���Ƶ�CPU�����������ʾ��ͼ,��ͼ�п�֪,CPUִ��ָ��ʱ����������ָ���������������ַ,��Ҫͨ��MMU�������ַת��Ϊ�����������ַ���ܷ�������,MMU������CPUоƬ�С�ͼ����ʾMMU��һ�������ַת��Ϊ������ַ4,�Ӷ�����4��5��6��7��4����Ԫ���������4�ֽ������͵�CPU����ͼ����һ����ʾ��ͼ,����û�п���cache�������
7�������ڴ�Ĺ���
��:
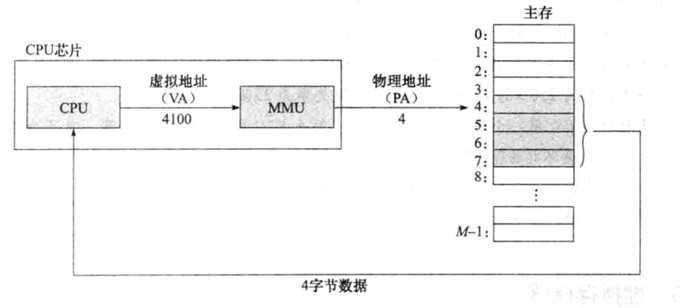
1)�����ҳ�洢����
ÿ�η��ʽ�����ǰ��Ҫ��ҳ���������,����������������Ծ��ҳ����ڴ�������������ij����Ϣ����ҳ��������ʱ����ȱҳ�쳣,��ʱ,Ӳ��������OS�ں��е�ȱҳ��������,��ȱʧҳ��Ӵ��̵������档
��������С���,����ҳ�Ĵ�СҪ��ö�����ΪDRAM��SRAM��Լ��10~100��,�����̱�DRAM��Լ��100000�,��������ȱҳ���������Ĵ���Ҫ��cacheȱʧ��ö���
����,���ݴ��̵�����,����������λ���õ�ʱ��Ҫ�ȴ��̶�дһ�����ݵ�ʱ�䳤��Լ100000��,Ҳ����������һ�����ݵĶ�д��������ݵĶ�дҪ��100000�������ǵ�ȱҳ���۵ľ�ʹ��̷��ʵ�һ�����ݵĿ���,ͨ��������ʹ���֮�佻����ҳ�Ĵ�С�趨�ñȽϴ�,���͵���4KB��8KB��,������Խ��Խ������ơ�
��Ϊȱҳ�������۽ϴ�,��������������ǹؼ�,���,������ҳ�������ҳ֮�����ȫ����ӳ�䷽ʽ������,������д����ʱ,���ڴ��̷����ٶȺ���,����,����ÿ��д������ͬʱдDRAM�ʹ���,���,�ڴ���һ��������ʱ,���û�д��ʽ,������ȫд��ʽ��
2)����ֶδ洢����
���ݳ����ģ�黯����,�ɰ���������ṹ���ֳɶ����Զ����IJ���,����,���̡����ݱ����������еȡ���Щ��Զ����IJ��ֱ���Ϊ��,������Ϊ����������λ���Ա���������ε���,�γɶμ�����,�Ӷ�������ģ�ϴ�ij�������ͨ���ж���������㡢�γ��ȡ����������û��������ݽṹ����κű�ʶ,�Ա��ڳ���ı�д�����������Ż��Ͳ���ϵͳ�ĵ��ȹ����ȡ�
���Ѷ���Ϊ������Ϣ��λ������-����֮�䴫�ͺͶ�λ���ֶη�ʽ��,������ؼ�ain��ʵ�ʳ����еĶ�������,ÿ�����������е�λ�ü�¼�ڶα���,�εij��ȿɱ�,���Զα������г���ָʾ,���γ���ÿ��������һ���α�,ÿ�����ڶα�����һ���α���,����ָ����Ӧ���������е�λ�á��γ�������Ȩ�ޡ�ʹ�ú�װ������ȡ��α�����Ҳ��һ�����ٶ�λ��,���Դ��������,��Ҫʱ��������,��һ��פ���������С�
�ڷֶ�ʽ����洢����,�����ַ�ɶκźͶ��ڵ�ַ��ɡ�ͨ���α��������ַת��������������ַ,�ֶ�ʽ����ϵͳ���ŵ��Ƕεķֽ���������Ȼ�ֽ����Ӧ;�ε���������ʹ�����ڱ��롢�������ĺͱ���,Ҳ���ڶ��������;ijЩ���͵Ķ�(��ѡ�ջ�����е�)���ж�̬�ɱ䳤��,�������ɵ����Ա���Ч��������ռ䡣����,���ڶεij��ȸ�����ͬ,�ε������յ㲻��,������ռ��������鷳,������������������������հ�����ռ�,����˷ѡ�
�ֶ�ʽ�ͷ�ҳʽ�洢����������ȱ��,��˿��Բ������߽�ϵĶ�ҳʽ�洢������ʽ��
3)�����ҳʽ�洢����
�ڶ�ҳʽ����洢����,����ģ��ֶ�,�����ٷ�ҳ,�öα���ҳ��(ÿ��һ��ҳ��)����������λ�������α���ÿ�������Ӧһ����,ÿ���α����а���һ��ָ��ö�ҳ����ʼλ�õ�ָ��,�Լ��ö������Ŀ��ƺʹ洢������Ϣ,��ҳ��ָ���öθ�ҳ�������е�λ���Լ��Ƿ�װ�롢�ĵ�״̬��Ϣ��
����ĵ��������ҳ����,�����ֿ�����ʵ�ֹ����ͱ��������,�����з�ҳʽ�ͷֶ�ʽ�洢�������ŵ㡣����ȱ�����ڵ�ַӳ�������Ҫ��β����
8�������ӳ��
��:
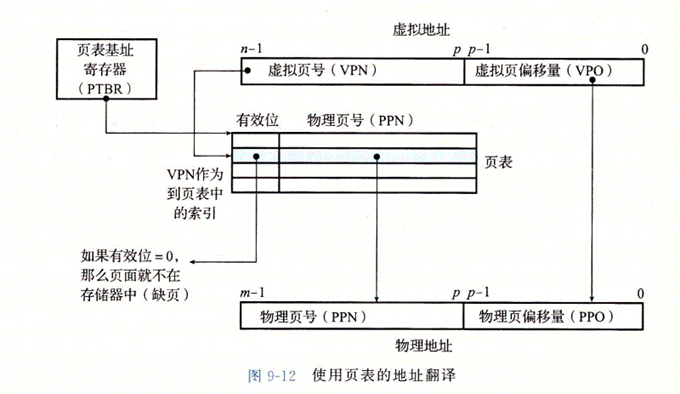
9����ת��������TLB
��:
��ַת��������,�ô�ʱ����Ҫ�������ҳ��,Ȼ����ܸ���ת���õ���������ַ�ٷ��������Դ洢ָ������ݡ����ȱҳ,��Ҫ����ҳ���滻��ҳ���ĵ�,��������Ĵ������ࡣ���,��������洢���ƺ�,ʹ�÷ô���������ˡ�Ϊ�˼��ٷô����,������ҳ�������Ծ�ļ���ҳ����Ƶ����ٻ�����,�����ڸ������е�ҳ������ɵ�ҳ����Ϊ��ת��������(Translation Lookaside Buffer,TLB),ͨ����Ϊ���,��Ӧ�س������е�ҳ��Ϊ������
10����̬�洢������������ռ�
��:
���ǿ���ͨ��mmap��munmap��������ɾ������洢������,���Կ�����˵ʹ��������������,����û�кܺõ���ֲ��,�����������ʹ�ö�̬�洢���������������̿ռ��еĶ�����̬�洢������ά����һ�����̵�����洢������,��Ϊ�ѡ����´ӵ�λ��ַ���λ����������,����ÿ������,�ں�ά����һ��brk,��ָ��ѵĶ�����
������������Ϊһ�鲻ͬ��С�Ŀ�ļ�����ά����ÿ�������һ������������洢��Ƭ,Ҫô���ѷ����,Ҫô�ǿ��еġ��ѷ������ʽ�ر���Ϊ��ӦӦ�ó���ʹ�á����п���������䡣һ���ѷ���Ŀ鱣���ѷ���״̬,ֱ�������ͷ�,�����ͷ�Ҫô��Ӧ�ó�����ʽִ�е�,Ҫô�Ǵ洢����ʽִ�е�,���Ƕ�����ʽ��������洢���,��֮ͬ���������ĸ�ʵ���������ͷ��ѷ���Ŀ顣
Ҫ����ʽ���ͷ��ѷ���Ŀ顣��C�����е�malloc��free,C++�е�new��delete��������
Ҫ����������һ���ѷ���Ŀ��ʱ���ٱ�����ʹ��,��ô���ͷ�����顣��ʽ������Ҳ���������ռ���(Garbage collector),��java���Ծ��������Ʒ�������
�������ǿ���malloc��free��ʵ������ι���һ��C�����16�ֵ�С�ѵġ�ÿ���������һ��4�ֽڵ��֡����߱���ľ��ζ�Ӧ���ѷ����(����Ӱ)�Ϳ��п�(����Ӱ),��ʼʱ,�Ѷ���һ����СΪ16���ֵġ�˫�ֶ���ġ����п���ɵġ�
- a)��������һ��4�ֵĿ�,malloc����Ӧ��:�ӿ��п��ǰ���г�һ��4�ֵĿ�,������һ��ָ�������ĵ�һ���ֵ�ָ��p1
- b)��������һ��5�ֵĿ�,malloc����Ӧ��:�ӿ��п��ǰ���ַ���һ��6�ֵĿ�,����ָ��p2,����һ����������Ϊ�˱��ֿ��п���˫�ֱ߽����ġ�
- c)��������һ��6�ֵĿ�,��malloc�ʹӿ��п��ǰ���г�һ��6�ֵĿ顣����ָ��p3
- d)�����ͷ���b�з������6�ֵĿ顣��Ҫע�����,�ڵ���free����֮��,ָ��p2��Ȼָ���ͷŵĿ�,������һ���µ�malloc�������³�ʼ��֮ǰ�����ڳ�������ʹ��p2
- e)��������һ��2�ֵĿ顣�����������,malloc������ǰһ�����ͷ��˵Ŀ��һ����,������ָ���¿��ָ��p4
**�����ռ�����һ�ֶ�̬�洢��������,���Զ��ͷų�������Ҫ���ѷ���顣��Щ���Ϊ�������Զ����նѴ洢�Ĺ��̽��������ռ���**��java������о�ʹ�������ƵĻ���,Ӧ����ʽ����ѿ�,���ǴӲ���ʽ���ͷ����ǡ������ռ�����ʱʶ��������,����Ӧ�ص���free,����Щ��Żص����������С�
�����ռ������洢����Ϊһ������ɴ�ͼ,��ͼ�Ľڵ㱻�ֳ�һ����ڵ��һ��ѽڵ㡣ÿ���ѽڵ��Ӧ�ڶ���һ���ѷ���顣�����p->q��ζ�ſ��е�ij��λ��ָ���q�е�ij��λ�á����ڵ��Ӧ������һ�ֲ��ٶ��е�λ��,�����а���ָ�����ָ�롣��Щλ�ÿ����ǼĴ���������ı���,����������洢���ж�ȡ���������ڵ�ȫ��������
������һ����������ڵ����������p������·��ʱ,����˵�ڵ�p�ǿɴ�ġ����κ�ʱ��,���ɴ�ڵ��Ӧ������,�Dz��ܱ�Ӧ���ٴ�ʹ�õġ������ռ����Ľ�ɫ����ά���ɴ�ͼ��ij�ֱ�ʾ,��ͨ���ͷŲ��ɴ�ڵ㽫���Ƿ��ظ���������,�����ڻ������ǡ�
�ġ����ӡ����̼��������
1����̬����
��:
1)�����ض�λ���ļ�����������ȫ���ӵġ��ɼ��ء������е�Ŀ���ļ�;
2)���ض�λĿ���ļ��ɸ���������ݽ����;
��ɾ�̬����,������Ҫ���������������:
1)���Ž���,��ÿһ�������������ú�һ�����Ŷ����������;
2)�ض�λ:���ض�λ��Ŀ���ļ���ַ���Ǵ��㿪ʼ��,������ͨ����ÿ�����Ŷ�����һ���ڴ�λ�ù�������,�Ӷ��ض�λ��Щ��,Ȼ�������ж���Щ���ŵ�����,ʹ������ָ������ڴ�λ�á�
2��Ŀ���ļ�
��:
����:���ض�λĿ���ļ�;��ִ��Ŀ���ļ�;����Ŀ���ļ�;
���ض�λĿ���ļ�:
���������ƴ��������,����ʽ�����ڱ���ʱ���������ض�λĿ���ļ��ϲ�����,����һ����ִ��Ŀ���ļ���
��ִ��Ŀ���ļ�:
���������ƴ��������,����ʽ���Ա�ֱ�Ӹ��Ƶ��ڴ沢ִ�С�
����Ŀ���ļ�:
һ���������͵Ŀ��ض�λĿ���ļ�,�����ڼ��ػ�������ʱ����̬�ļ��ؽ��ڴ沢���ӡ�
3�����źͷ��ű�
��:
����:���ű���¼��Ŀ��ģ�鶨��ķ��ź����õķ�����Ϣ��
���ַ�������:
1)��ģ��m���岢�ܱ�����ģ�����õ�ȫ�ַ���,�Ǿ�̬��C������ȫ������;
2)������ģ�鶨�岢��ģ��m���õ�ȫ�ֱ���;
3)��Ŀ��ģ�鶨������õľֲ�����,����Ϊ��̬ȫ�ֱ����ͺ���;
���Ž���:���ӷ�����������Ŷ���
1)ȫ�ַ��ŵĶ��ֶ�������
ǿ����:�ѱ���ʼ����ȫ�������ͺ���
������:δ����ʼ����ȫ������
2)����
(1)�������ж��ͬ����ǿ����
(2)�����һ��ǿ���źͶ��������ͬ��,ѡǿ����
(3)����ж��������ͬ��,����������ѡһ��
3)���ŵĵ�ַ��������ȷ��,�����ŵĴ�С�Լ��������ڱ��������Ѿ�ȷ����,����ֻ����������ض�λ����ȷ�Ϸ��ŵĵ�ַ,ͬ���������ҽ���һ����ַ
4)��̬���ӿ�ѡ��ʽ
(1)һ����ض�λĿ���ļ�
(2)������ص�Ŀ��ģ������һ�������ļ�-��̬��(�浵�ļ�)
5)ʹ�þ�̬������������
����:
���Ž���ʱ,�����������Ұ��������ڱ��������������������ϳ��ֵ�˳����ɨ����ض�λĿ���ļ��ʹ浵�ļ�(��.c .o)��
������ά����������:����Ŀ��ģ�鼯��E;δ����ļ���U;����ļ���D;
ɨ�迪ʼ,���������ж�����f��ʲô,����Ŀ���ļ�,f���ӵ�E,��U/D����Ӧf�еķ��Ŷ��������;��f�Ǵ浵�ļ�,�������ͳ���ƥ��U��δ�����ķ��ź��ɴ浵�ļ���Ա����ķ���,���浵�ļ���Աm�����Ѷ���ķ���,m��E,��U/D;������������ɨ���,U�ǿ�,�����������������ֹ,��������ϲ����ض�λE�е�Ŀ���ļ�
4���ض�λ�ͼ���
��:
1)�ض�λ(�ɽ�Ͼ�̬���ӵ�������������)
��Ҫ������:
(1)�ض�λ�ںͷ��Ŷ���:�ۺ�����Ŀ���ļ�����ͬ��,��������ʼ������ʱ�ڴ��ַ����ÿһ���ں�ÿһ�����š���
(2)�ض�λ���еķ�������,�������Ĵ���ں����ݽ��е�ÿ����������,ʹ������ִ����ȷ������ʱ��ַ��
2)����:
(1)һ������,�����������δ֪�ķ�������,�ͻ�����һ���ض�λ��Ŀ,������ض�λ��Ŀ�����.rel.text��,�ѳ�ʼ�����ݵ��ض�λ��Ŀ����.rel.data��
�ض�λ�ṹ�����ݽṹ:
typedef struct
{
? long offset;
? long type:32;
? symbol:32;
? long addend;
}EIf64_Rela
(2)�������õ��ض�λ
ֻ�����ֻ������ض�λ����:�������;�������á�
3)���ء���
(1)����:elf��ִ���ļ��ĸ�ʽ�����ض�λ�ĸ�ʽ�Ǻ����Ƶ�
(2)��ִ��Ŀ���ļ��ļ���
��������Ŀ���ļ��Ĵ�������ݸ��Ƶ��ڴ���,Ȼ����ת����ڵ������м�_start�����ĵ�ַ;
5����̬���ӿ�
��:
1)���ֵ�ԭ��:
Ϊ�˽����̬��ά����������鷳�Լ��ܶ�ÿ����ڴ����кܶ������ɵ��ڴ��˷ѡ�
2)��̬����:
�������ڼ��ػ�����ʱ�����������ڴ�λ��,�������ڴ��еij�����������,�ɶ�̬��������ɡ�
3)���ϸ��:
��̬���Ӳ��Ḵ�ƹ�����Ĵ�������ݶ�,���Ḵ��һЩ�ض�λ��Ϣ�ͷ��ű�;
��Ϣ�ͷ��ű�
�������л���һ��.interp��,����ڰ�����̬��������·����,��̬��������������һ������Ŀ����(Id-linux.so)��
������һ����ִ���ļ�ʱ,��������ͨ��.interp�ڵ���Ϣ�ҵ���̬������������,����̬�������ض�λ��ص�.so�������������:
λ���ش���PIC(position independent code):����������Ҫ�����̹�����Ҫ��ʹ��λ���ش���,λ���ش����ǿ��Լ��ص��ڴ������λ��,�������������ļ����Լ��غ��ض�λ;
6���쳣�ͽ���
��:
�쳣���ǿ�����ͻ��,������Ӧ������״̬�е�ij���仯,һ������Ӳ��ʵ��,һ�����ɲ���ϵͳ��ʵ��,ÿ���쳣���ᱻ����һ���쳣��,һЩ��Ӳ�������������,��������:�ڴ�ȱҳ���㷨������ڴ����Υ�桢����,һЩ���ں�����߷���,���õ���ϵͳ���ú��ⲿI/O�豸���ź�,�쳣�����·���:�жϡ����ϡ����塢��ֹ�������ж����첽������,�жϺ�����������������ָ��,������ͬ�������Ƿ�������ָ��,������ͬ����,��DZ�ڿɻָ��Ĵ������(ȱҳ),���ص�ǰ��ָ��,��ֹ��ͬ����,���ɻָ�,���᷵�ء�