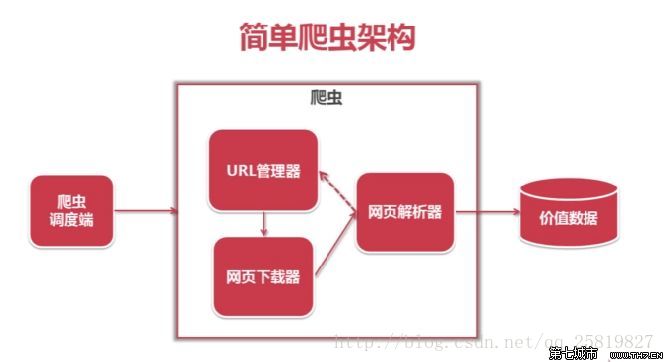
爬虫主要就是要过滤掉网页中无用的信息,抓取网页中有用的信息
一般的爬虫架构为:
在python爬虫之前先要对网页的结构知识有一定的了解,如网页的标签,网页的语言等知识,推荐去W3School:
W3school链接进行了解
在进行爬虫之前还要有一些工具:
1.首先Python 的开发环境:这里我选择了python2.7,开发的IDE为了安装调试方便选择了用VS2013上的python插件,在VS上进行开发(python程序的调试与c的调试差不多较为熟悉);
2.网页源代码的查看工具:虽然每一个浏览器都能进行网页源代码的查看,但这里我还是推荐用火狐浏览器和FirBug插件(同时这两个也是网页开发人员必用的工具之一);
FirBug插件的安装可以在右边的添加组件中安装;
其次来看试着看网页的源代码,这里我以我们要爬取的篮球数据为例:
如我要爬取网页中的Team Comparison表格内容为例:

先右键选中如我要爬取的比分32-49,点击右键选择选择用firBug查看元素,(FirBug的还有一个好处是在查看源码时会在网页上显示源码所显示的样式,在网页中我的位置及内容)网页下方就会跳出网页的源码以及32-49比分所在的位置及源码如下图:
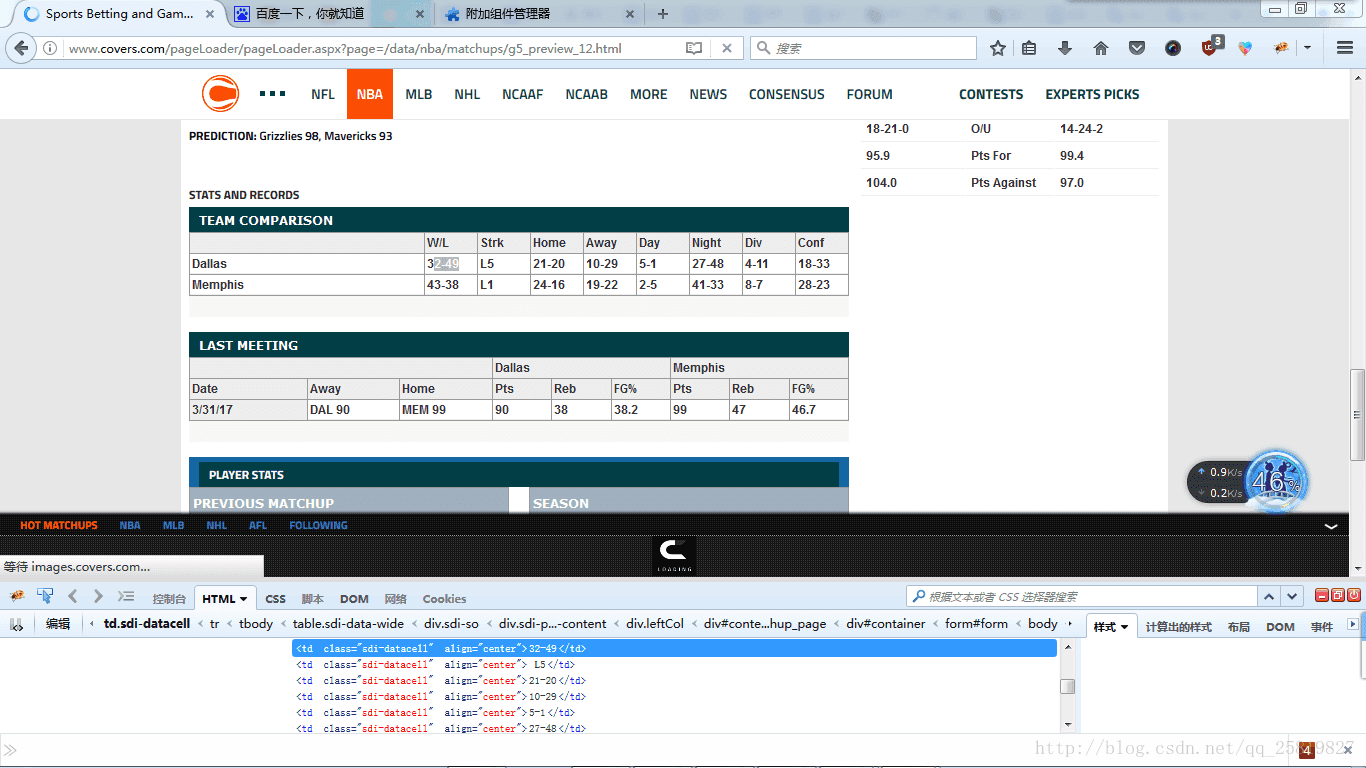
可以看到32-49为网页的源码为:
<td class="sdi-datacell" align="center">32-49</td>
其中td为标签的名字,class为类的名字,align为格式,32-49为标签的内容,为我们要爬取的内容;
但类似的标签以及类的名字在同一个网页中有很多,光靠这两个元素无法爬下我们所需要的数据,这时就需要查看这一标签的父标签,或再上一级的标签来提取更多我们要爬取数据的特征,来过滤其他我们所不要爬取的数据,如我们这里选取这张表格所在的标签作为我我们进行筛选的第二个
特征:
<div class="sdi-so">
<h3>Team Comparison</h3>
再来我们来分析网页的URL:
如我们要爬取的网页的URL为:
http://www.covers.com/pageLoader/pageLoader.aspx?page=/data/nba/matchups/g5_preview_12.html
因为有搭网站的经验,所以可以这里
www.covers.com为域名;
/pageLoader/pageLoader.aspxpage=/data/nba/matchups/g5_preview_12.html,可能为放在服务器上的网页根目录的/pageLoader/pageLoader.aspx?page=/data/nba/matchups/地址中的网页,
为了管理方便,相同类型的网页都会放在同一个文件夹下,以类似的命名方式命名:如这边的网页是以g5_preview_12.html命名的所以类似的网页会改变g5中的5,或者_12 中的12,通过改变这两个数字,我们发现类似网页可以改变12数字来得到,
再来学习爬虫:
这里python爬虫主要用到了
urllib2
BeautifulSoup
这两个库,BeautifulSoup的详细文档可以在以下网站中查看:
https://www.crummy.com/software/BeautifulSoup/bs4/doc/index.zh.html
在爬取网页时:
先要打开网页,然后在调用beautifulSoup库进行网页的分析,再用如.find函数找到要刚刚我们分析的特征所在的位置,并用.text来获取标签的内容即我们所要爬取的数据
如我们对照以下代码来进行分析:
response=urllib2.urlopen(url)
print response.getcode()
soup=BeautifulSoup(
response,
'html.parser',
from_encoding='utf-8'
)
links2=soup.find_all('div',class_="sdi-so",limit=2)
cishu=0
for i in links2:
if(cishu==1):
two=i.find_all('td',class_="sdi-datacell")
for q in two:
print q.text
table.write(row,col,q.text)
col=(col+1)%9
if(col==0):
row=row+1
row=row+1
file.save('NBA.xls')
cishu=cishu+1
urllib2.urlopen(url)为打开网页;
print response.getcode()为测试网页是否能被打开;
soup=BeautifulSoup(
response,
‘html.parser’,
from_encoding=’utf-8’
)
为代用Beautiful进行网页的分析;
links2=soup.find_all(‘div’,class_=”sdi-so”,limit=2)为进行特征值的查询与返回
其中我们要查找’div’,class_=”sdi-so”,的标签,limit=2为限制找两个(这是为过滤其他类似的标签)
for i in links2:
if(cishu==1):
two=i.find_all('td',class_="sdi-datacell")
for q in two:
print q.text
table.write(row,col,q.text)
col=(col+1)%9
if(col==0):
row=row+1
row=row+1
为在找到的’div’,class_=”sdi-so”,的标签中再进行相应的如’td’,class_=”sdi-datacell”标签的查找;
q.text为返回我们所要的数据
这里 row=row+1,row=row+1为我们将数据写入到excel文件时文件格式的整理所用的;
接下来是对抓取数据的保存:
这里我们用了excel来保存数据用到了包:
xdrlib,sys, xlwt
函数:
file=xlwt.Workbook()
table=file.add_sheet(‘shuju’,cell_overwrite_ok=True)
table.write(0,0,’team’)
table.write(0,1,’W/L’)
table.write(row,col,q.text)
file.save(‘NBA.xls’)
为最基本的excel写函数,这里不再累述;
最后我们爬下来数据保存格式后样式为:
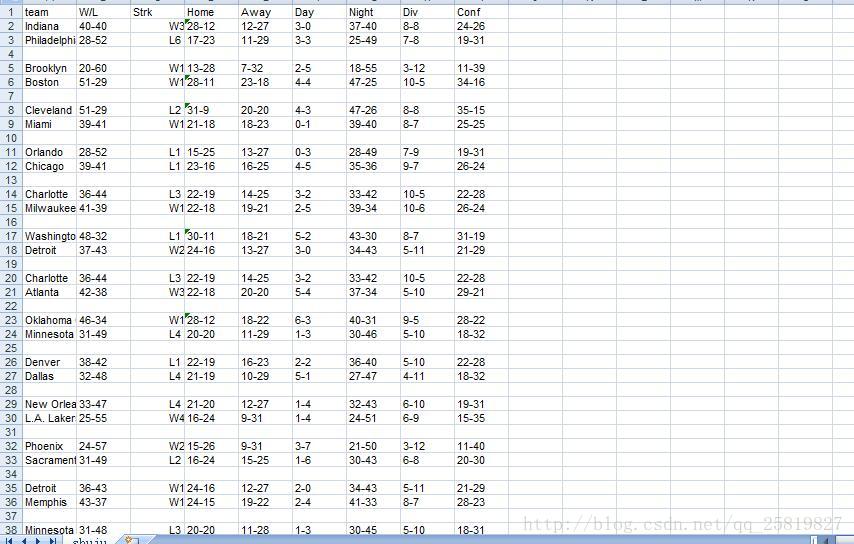
NICE

我所认为最深沉的爱,莫过于分开以后,我将自己,活成了你的样子。