����ץȡ(���ڡ������Ӱ���ĸ���ѡ��,���������š�,������߷֡���ʮ�����������,�����exe)�뿴Python�Զ��嶹���Ӱ����,����,��������ȡ��洢(����)
����ץȡ(�ڳ���ץȡ������,����GUI���,ͼ����ʾ�������Ի�,�������exe)�뿴 Python�Զ��嶹���Ӱ����,����,��������ȡ��洢(������)
�ҷ�����,�Ҳ�����д����,������дBUG������
����
�������ڶ����Ӱ�ĸ���ץȡ,����ħצ�����˶�����Ӿ�,����������������������Ӱ�ӵ�ץȡ,�����Ժ�Ҫ��Ҫ��ץ������鰡������
Ŀ��
��ɶԶ���Ӱ��,���������Ӱ,������Ӿ�,����һ�����а���Զ���ץȡ��GUI������Ƽ����exe
����
ʹ��Tkinter+PhantomJS+Selenium+Firefoxʵ��
ʵ�ֹ���
1.get����ҳ��,����ѡ��,�������,Ȼ�������������,�������� �C���������ʱlistbox��ֵ�ĵ������
2.ץȡÿ����Ӱ��������,���볬���Ӻ�,ץȡ��ǰ��Ӱ������������
3.���û���Ҫ��TOP��Ŀ���ڵ�һҳ��20��ʱ��,������ظ���,�ٳ���20����Ӱ,�ظ�2������
4.�����д����������,д��txt�еȲ���
ʵ��Ч��
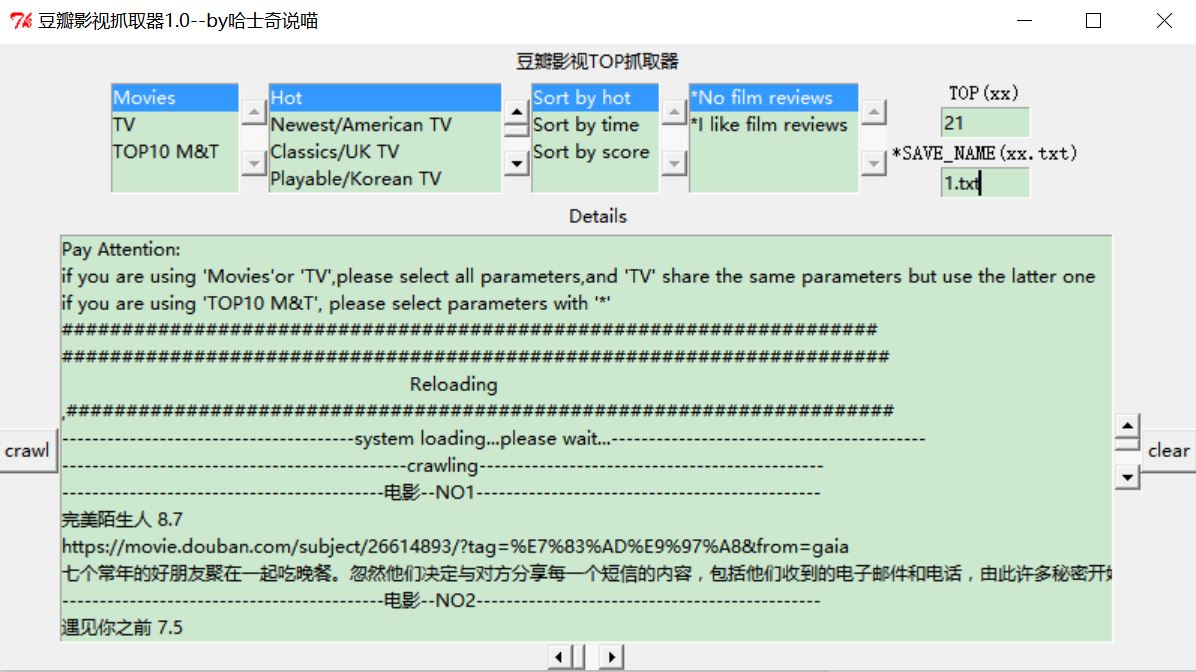
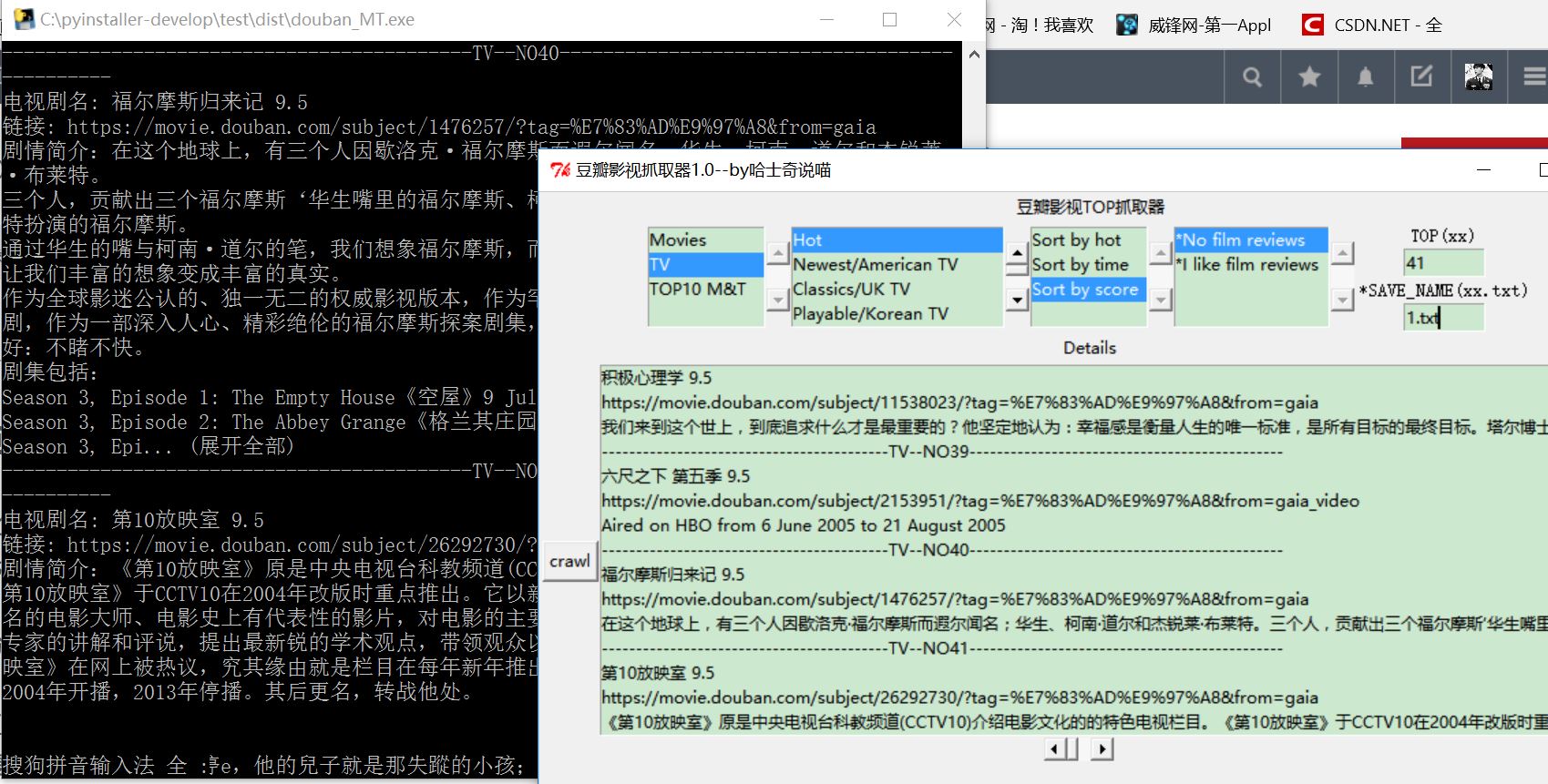
��ͼ��,�����һ���Ӱ��ѡ���������ʵ����ز���,
����˵��һ��,��һ��,Ӱ��ѡ��,�ڶ���,���ѡ��(���Ӿ翴������),������,����ʽ,������,�Ƿ��������,������TOP����,������,��������(��Ҫ��ʽΪxx.txt)
������exe�İ汾
���ϴ���Դ,������Ҫ���������������
����
from selenium import webdriver
import selenium.webdriver.support.ui as ui
import time
from Tkinter import *
print "---------------system loading...please wait...---------------"
def getURL_Title():
global save_name
SUMRESOURCES=0
url="https://movie.douban.com/"
driver_item=webdriver.Firefox()
wait = ui.WebDriverWait(driver_item,15)
Class_Dict={'Movies':1,'TV':2,'TOP10 M&T':3}
Kind_Dict={'Hot':1,'Newest/American TV':2,'Classics/UK TV':3,'Playable/Korean TV':4,'High Scores/Japanese TV':5,
'Wonderful but not popular/Chinese TV':6,'Chinese film/TVB':7,'Hollywood/Cartoon':8,
'Korea':9,'Japan':10,'Action movies':11,'Comedy':12,'Love story':13,
'Science fiction':14,'Thriller':15,'Horror film':16,'Whatever':17}
Sort_Dict={'Sort by hot':1,'Sort by time':2,'Sort by score':3}
Ask_Dict={'*No film reviews':0,'*I like film reviews':1}
try:
kind=Kind_Dict[Kind_Select.get(Kind_Select.curselection()).encode('utf-8')]
sort = Sort_Dict[Sort_Select.get(Sort_Select.curselection()).encode('utf-8')]
number = int(input_Top.get())
except:
print 'if you are using TOP10 M&T ,it\'s all right\n if not,please choice kind/sort/number '
class_MT = Class_Dict[MT_Select.get(MT_Select.curselection()).encode('utf=8')]
ask_comments = Ask_Dict[Comment_Select.get(Comment_Select.curselection()).encode('utf-8')]
save_name=input_SN.get()
Ans.insert(END,"#####################################################################")
Ans.insert(END," Reloading ")
Ans.insert(END,",#####################################################################")
Ans.insert(END,"---------------------------------------system loading...please wait...------------------------------------------")
Ans.insert(END,"----------------------------------------------crawling----------------------------------------------")
Write_txt('\n##########################################################################################','\n##########################################################################################',save_name)
print "---------------------crawling...---------------------"
if class_MT==1:
driver_item.get(url)
wait.until(lambda driver: driver.find_element_by_xpath("//div[@class='fliter-wp']/div/form/div/div/label[%s]"%kind))
driver_item.find_element_by_xpath("//div[@class='fliter-wp']/div/form/div/div/label[%s]"%kind).click()
wait.until(lambda driver: driver.find_element_by_xpath("//div[@class='fliter-wp']/div/form/div[3]/div/label[%s]"%sort))
driver_item.find_element_by_xpath("//div[@class='fliter-wp']/div/form/div[3]/div/label[%s]"%sort).click()
num=number+1
num_time = num/20+2
wait.until(lambda driver: driver.find_element_by_xpath("//div[@class='list-wp']/div/a[20]"))
for times in range(1,num_time):
driver_item.find_element_by_xpath("//div[@class='list-wp']/a[@class='more']").click()
wait.until(lambda driver: driver.find_element_by_xpath("//div[@class='list-wp']/div/a[%d]"%(20*(times+1))))
for i in range(1,num):
wait.until(lambda driver: driver.find_element_by_xpath("//div[@class='list']/a[%d]"%num))
list_title=driver_item.find_element_by_xpath("//div[@class='list']/a[%d]"%i)
print '----------------------------------------------'+'NO' + str(SUMRESOURCES +1)+'----------------------------------------------'
print u'��Ӱ��: ' + list_title.text
print u'����: ' + list_title.get_attribute('href')
while list_title.text==driver_item.find_element_by_xpath("//div[@class='list']/a[%d]"%(i+20)).text:
print u'����ҳ������ظ���bug,��ʼ���¼���...'
driver_item.quit()
getURL_Title()
list_title_wr=list_title.text.encode('utf-8')
list_title_url_wr=list_title.get_attribute('href')
Ans.insert(END,'\n-------------------------------------------Movies--'+'NO' + str(SUMRESOURCES +1)+'----------------------------------------------',list_title_wr,list_title_url_wr)
Write_txt('\n------------------------------------------Movies--'+'NO' + str(SUMRESOURCES +1)+'----------------------------------------------','',save_name)
Write_txt(list_title_wr,list_title_url_wr,save_name)
SUMRESOURCES = SUMRESOURCES +1
try:
getDetails(str(list_title.get_attribute('href')),ask_comments)
except:
print 'can not get the details!'
driver_item.quit()
if class_MT == 2:
driver_item.get(url)
wait.until(lambda driver: driver.find_element_by_xpath("//div[@class='fliter-wp']/h2/a[2]"))
driver_item.find_element_by_xpath("//div[@class='fliter-wp']/h2/a[2]").click()
wait.until(lambda driver: driver.find_element_by_xpath("//div[@class='fliter-wp']/div/form/div/div/label[%s]"%kind))
driver_item.find_element_by_xpath("//div[@class='fliter-wp']/div/form/div/div/label[%s]"%kind).click()
wait.until(lambda driver: driver.find_element_by_xpath("//div[@class='fliter-wp']/div/form/div[3]/div/label[%s]"%sort))
driver_item.find_element_by_xpath("//div[@class='fliter-wp']/div/form/div[3]/div/label[%s]"%sort).click()
num=number+1
num_time = num/20+2
wait.until(lambda driver: driver.find_element_by_xpath("//div[@class='list-wp']/div/a[20]"))
for times in range(1,num_time):
driver_item.find_element_by_xpath("//div[@class='list-wp']//a[@class='more']").click()
wait.until(lambda driver: driver.find_element_by_xpath("//div[@class='list-wp']/div/a[%d]"%(20*(times+1))))
for i in range(1,num):
wait.until(lambda driver: driver.find_element_by_xpath("//div[@class='list']/a[%d]"%num))
list_title=driver_item.find_element_by_xpath("//div[@class='list']/a[%d]"%i)
print '-------------------------------------------TV--'+'NO' + str(SUMRESOURCES +1)+'----------------------------------------------'
print u'���Ӿ���: ' + list_title.text
print u'����: ' + list_title.get_attribute('href')
while list_title.text==driver_item.find_element_by_xpath("//div[@class='list']/a[%d]"%(i+20)).text:
print u'����ҳ������ظ���bug,��ʼ���¼���...'
driver_item.quit()
getURL_Title()
list_title_wr=list_title.text.encode('utf-8')
list_title_url_wr=list_title.get_attribute('href')
Ans.insert(END,'\n------------------------------------------TV--'+'NO' + str(SUMRESOURCES +1)+'----------------------------------------------',list_title_wr,list_title_url_wr)
Write_txt('\n----------------------------------------TV--'+'NO' + str(SUMRESOURCES +1)+'----------------------------------------------','',save_name)
Write_txt(list_title_wr,list_title_url_wr,save_name)
SUMRESOURCES = SUMRESOURCES +1
try:
getDetails(str(list_title.get_attribute('href')),ask_comments)
except:
print 'can not get the details!'
driver_item.quit()
if class_MT==3:
driver_item.get(url)
for i in range(1,11):
wait.until(lambda driver: driver.find_element_by_xpath("//div[@class='billboard-bd']/table/tbody/tr"))
list_title=driver_item.find_element_by_xpath("//div[@class='billboard-bd']/table/tbody/tr[%d]/td[2]/a"%i)
print '----------------------------------------------'+'NO' + str(SUMRESOURCES +1)+'----------------------------------------------'
print u'Ӱ����: ' + list_title.text
print u'����: ' + list_title.get_attribute('href')
list_title_wr=list_title.text.encode('utf-8')
list_title_url_wr=list_title.get_attribute('href')
Ans.insert(END,'\n-------------------------------------------WeekTOP--'+'NO' + str(SUMRESOURCES +1)+'----------------------------------------------',list_title_wr,list_title_url_wr)
Write_txt('\n------------------------------------------WeekTOP--'+'NO' + str(SUMRESOURCES +1)+'----------------------------------------------','',save_name)
Write_txt(list_title_wr,list_title_url_wr,save_name)
SUMRESOURCES = SUMRESOURCES +1
try:
getDetails(str(list_title.get_attribute('href')),ask_comments)
except:
print 'can not get the details!'
driver_item.quit()
def getDetails(url,comments):
driver_detail = webdriver.PhantomJS(executable_path="phantomjs.exe")
wait1 = ui.WebDriverWait(driver_detail,15)
driver_detail.get(url)
wait1.until(lambda driver: driver.find_element_by_xpath("//div[@id='link-report']/span"))
drama = driver_detail.find_element_by_xpath("//div[@id='link-report']/span")
print u"������:"+drama.text
drama_wr=drama.text.encode('utf-8')
Ans.insert(END,drama_wr)
Write_txt(drama_wr,'',save_name)
if comments == 1:
print "--------------------------------------------Hot comments TOP----------------------------------------------"
for i in range(1,5):
try:
comments_hot = driver_detail.find_element_by_xpath("//div[@id='hot-comments']/div[%s]/div/p"%i)
print u"��������:"+comments_hot.text
comments_hot_wr=comments_hot.text.encode('utf-8')
Ans.insert(END,"--------------------------------------------Hot comments TOP%d----------------------------------------------"%i,comments_hot_wr)
Write_txt("--------------------------------------------Hot comments TOP%d----------------------------------------------"%i,'',save_name)
Write_txt(comments_hot_wr,'',save_name)
except:
print 'can not caught the comments!'
try:
driver_detail.find_element_by_xpath("//img[@class='bn-arrow']").click()
time.sleep(1)
comments_get = driver_detail.find_element_by_xpath("//div[@class='review-bd']/div[2]/div")
if comments_get.text.encode('utf-8')=='��ʾ: ��ƪӰ�������о�':
comments_deep=driver_detail.find_element_by_xpath("//div[@class='review-bd']/div[2]/div[2]")
else:
comments_deep = comments_get
print "--------------------------------------------long-comments---------------------------------------------"
print u"��ȳ���:"+comments_deep.text
comments_deep_wr=comments_deep.text.encode('utf-8')
Ans.insert(END,"--------------------------------------------long-comments---------------------------------------------\n",comments_deep_wr)
Write_txt("--------------------------------------------long-comments---------------------------------------------\n",'',save_name)
Write_txt(comments_deep_wr,'',save_name)
except:
print 'can not caught the deep_comments!'