1. �½���Ŀ
���������������scrapy startproject scrapytest, ����
Ȼ����Զ���������Ӧ���ļ�������
2. ��itmes.py�ļ�
��scrapy����Զ�������items.py�ļ�������
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class ScrapytestItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
pass
��д����Ĵ��룬ȷ����Ҫ��ȡ����Ϣ���������ű��⣬url��ʱ�䣬��Դ����Դ��url�����ŵ����ݵ�
class ScrapytestItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field()
timestamp = scrapy.Field()
category = scrapy.Field()
content = scrapy.Field()
url = scrapy.Field()
pass
3. ����spider������һ������ģ��
3.1 ����crawl����ģ��
�������д������� ����һ��crawl����ģ�壨ע�����ļ��ĸ�Ŀ¼���棬ָ������������-t ��ʾʹ�ú����crawlģ�壩������spider�ļ�������һ��news163.py�ļ�
scrapy genspider -t crawl codingce news.163.com
Ȼ��һ�������crawl'ģ���һ���ģ����ʲô���𣬶���������ȡ������һЩ�������������������������һЩ�����Ϣ����ȡ
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
class CodingceSpider(CrawlSpider):
name = 'codingce'
allowed_domains = ['163.com']
start_urls = ['http://news.163.com/']
rules = (
Rule(LinkExtractor(allow=r'Items/'), callback='parse_item', follow=True),
)
def parse_item(self, response):
item = {}
#item['domain_id'] = response.xpath('//input[@]/@value').get()
#item['name'] = response.xpath('//div[@]').get()
#item['description'] = response.xpath('//div[@]').get()
return item
3.2 ����֪ʶ��selectorsѡ����
֧��xpath��css,xpath�����
/html/head/title
/html/head/title/text()
//td (�����ȡ�Ļ���������/)
//div[@class=��mine']
3.3. ������ҳ����
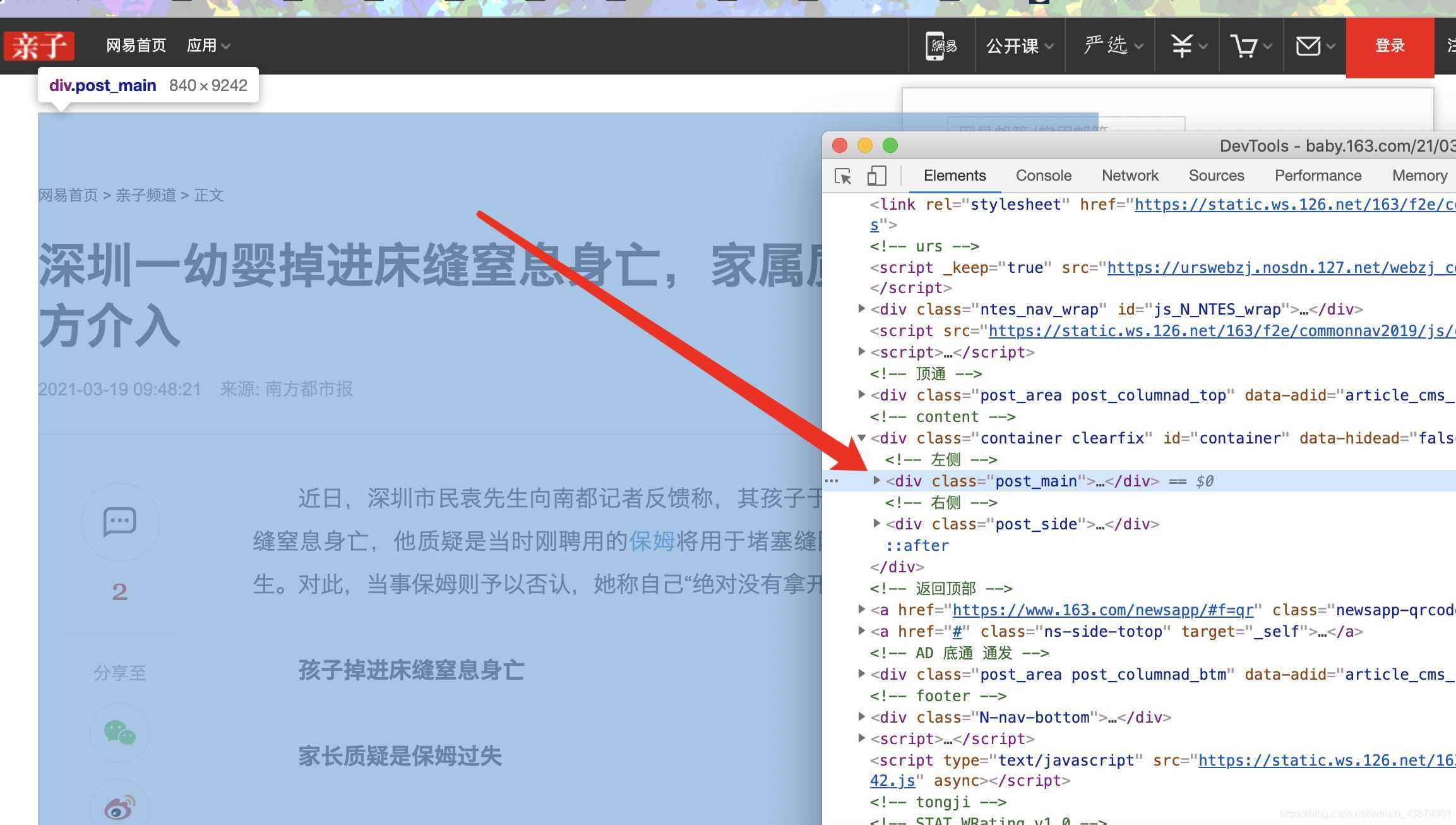
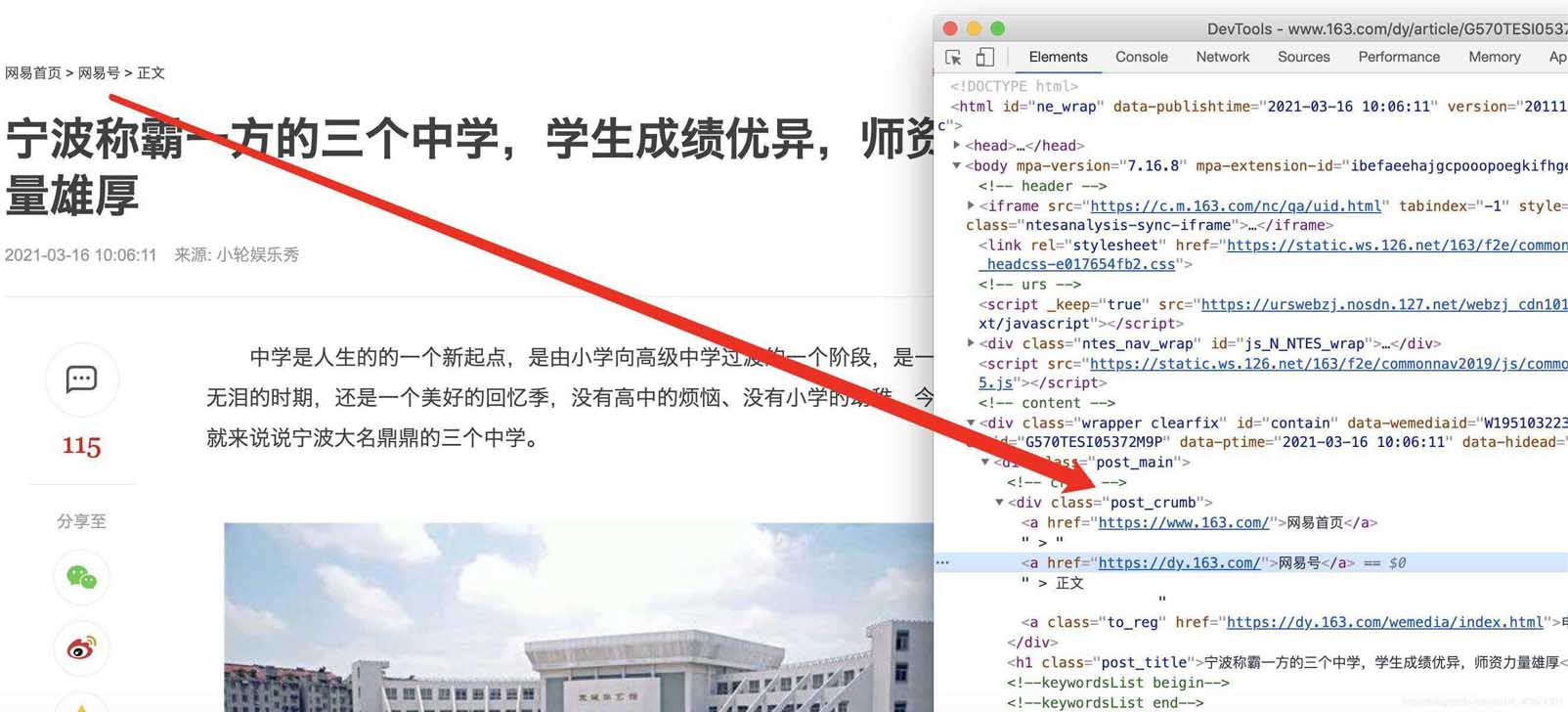
�ڹȸ�chrome������£�������ҳ���ŵ���վ��ѡ��鿴Դ���룬ȷ�����ǿ��Ի�ȡ��itmes.py�ļ������ݣ���ʵ�������Ҫ��ȡ�ľ��Dz鿴����ҳԴ����֮��ȷ�����Ի�ȡ�ģ�
ȷ�ϱ��⡢ʱ�䡢url����Դurl�����ݿ���ͨ�����ͱ�ǩ��Ӧ�ϣ��������IJ���
����
����

ʱ��
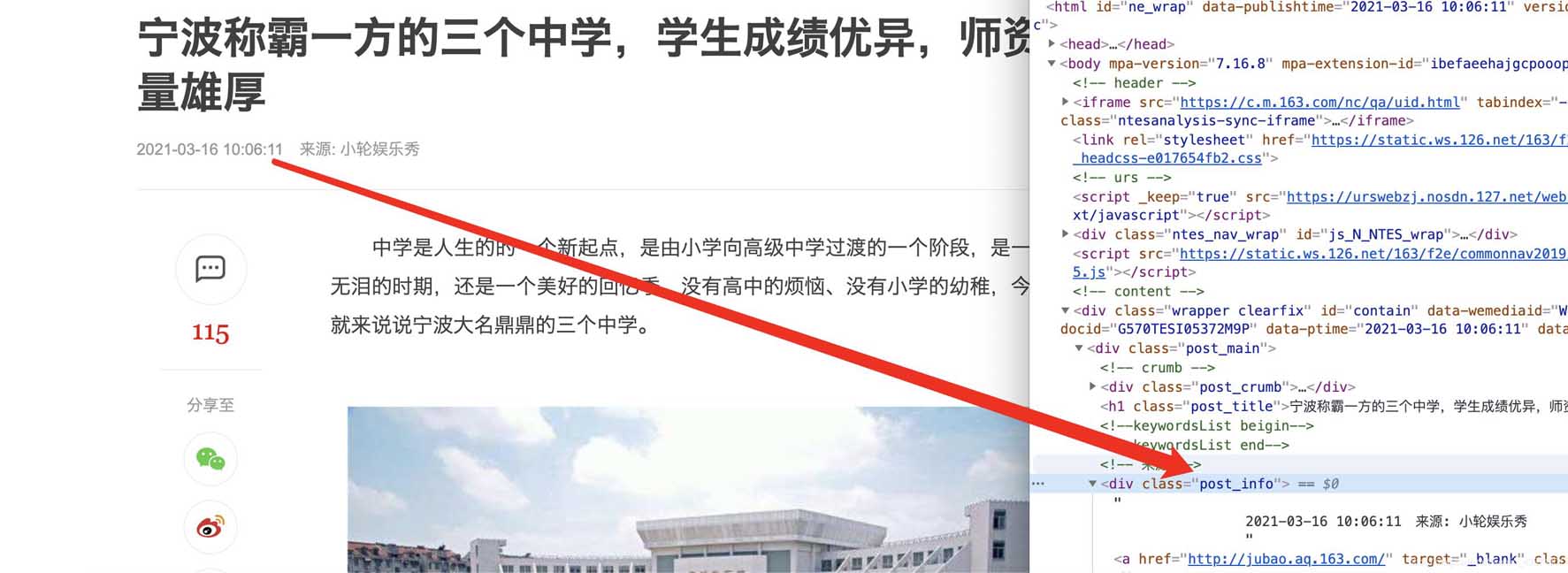
����
4. ��spider�´����������ļ�
4.1 �����
����������ģ�壬���д���ı�д�����˵���ϵͳ�Զ������������⣬���ǻ���Ҫ����news.items(������漰���˰��ĸ����ˣ��ʼ˵�ĨCinit�C.py�ļ�����˵������ļ��о���һ��������ֱ�ӵ��룬����Ҫ��װ)
ע�⣺ʹ�õ���ExampleSpiderһ��Ҫ�̳���CrawlSpider����Ϊ�ʼ���Ǵ����ľ���һ����crawl'������ģ�壬��Ӧ��
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from scrapytest.items import ScrapytestItem
class CodingceSpider(CrawlSpider):
name = 'codingce'
allowed_domains = ['163.com']
start_urls = ['http://news.163.com/']
rules = (
Rule(LinkExtractor(allow=r'.*\.163\.com/\d{2}/\d{4}/\d{2}/.*\.html'), callback='parse', follow=True),
)
def parse(self, response):
item = {}
content = '<br>'.join(response.css('.post_content p::text').getall())
if len(content) < 100:
return
return item
Rule(LinkExtractor(allow=r'..163.com/\d{2}/\d{4}/\d{2}/..html'), callback=��parse', follow=True), ���е�һ��allow��������д�������ʽ�ģ�Ҳ�����Ǻ���Ҫ��������ݣ����ڶ����ǻص���������������ʾ�Ƿ���������
���մ���
from datetime import datetime
import re
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from scrapytest.items import ScrapytestItem
class CodingceSpider(CrawlSpider):
name = 'codingce'
allowed_domains = ['163.com']
start_urls = ['http://news.163.com/']
rules = (
Rule(LinkExtractor(allow=r'.*\.163\.com/\d{2}/\d{4}/\d{2}/.*\.html'), callback='parse', follow=True),
)
def parse(self, response):
item = {}
content = '<br>'.join(response.css('.post_content p::text').getall())
if len(content) < 100:
return
title = response.css('h1::text').get()
category = response.css('.post_crumb a::text').getall()[-1]
print(category, "=======category")
time_text = response.css('.post_info::text').get()
timestamp_text = re.search(r'\d{4}-\d{2}-\d{2} \d{2}:\d{2}:\d{2}', time_text).group()
timestamp = datetime.fromisoformat(timestamp_text)
print(title, "=========title")
print(content, "===============content")
print(timestamp, "==============timestamp")
print(response.url)
return item

js