МђЕЅЪЕЯжipДњРэЃЌЮЊСЫВЛТєЙуИцЃЌ
ЧыздаазМБИвЛИіipДњРэЕФЦНЬЈ
Р§ШчЮвгУЕФетИіЦНЬЈ,УПДЮЬсШЁ10Иіip

ДгЩЯУцПЩвдПДЕНЪ§ОнИёЪНЪЧЮФБОЃЌЛЛааЪЧ\r\nЃЌЗУЮЪСДНгжЎКѓДѓИХОЭЪЧГЄетбљЕФ,scrapyРяУцЕФipашвЊМгЩЯЧАзКhttp://
Р§Шч:http://117.95.41.21:34854
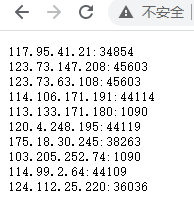
OKЃЌФЧЯждквбОзМБИКУСЫipСЫЃЌЯШИјФуУЧТХвЛЯТЫМТЗЁЃ
ipГиКЭМЦЪ§ЦїЗХдкsettingЮФМў
ЕквЛДЮЧыЧѓЕФЪБКђвЊЬюТњipГи,ЫљвддкХРГцЮФМўЕФstart_requestsКЏЪ§ЯТЪж
ИќЛЛipЕФЕиЗНЪЧmiddlewaresЕФЯТдиЦїжаМфМўРрЕФprocess_requestКЏЪ§,вђЮЊУПИіЧыЧѓЗЂЦ№ЧАЖМЛсОЙ§етИіКЏЪ§
ЪзЯШЪЧsettingЮФМў,ЦфЪЕОЭЪЧМгСНОфДњТы
count = {'count': 0}
ipPool = []
ЛЙгаОЭЪЧПЊЦєЯТдиЦїжаМфМў,зЂвтЪЧЯТУцФЧИіdownloadЕФРр,жаМфМўЕФprocess_requestКЏЪ§ЕФЪБКђВХФмЩњаЇ
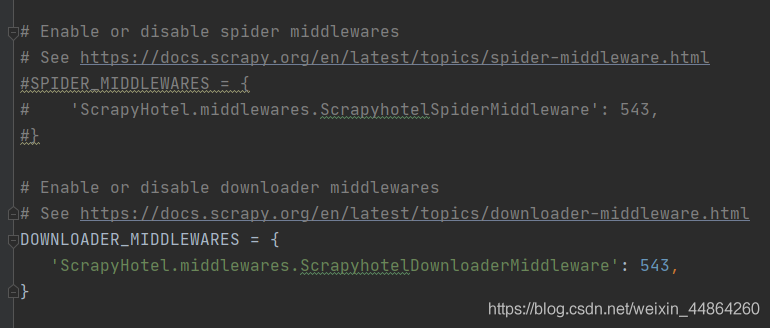
ЯТдиЦїжаМфМўЕФprocess_requestКЏЪ§,НјааipДњРэКЭЙЬЖЈДЮЪ§ИќЛЙipДњРэГи
# МЧЕУЕМАќ
from ФуЕФЯюФП.settings import ipPool, count
import random
import requests
def process_request(self, request, spider):
# ЫцЛњбЁжавЛИіip
ip = random.choice(ipPool)
print('ЕБЧАip', ip, '-----', count['count'])
# ИќЛЛrequestЕФip----------етОфЪЧжиЕу
request.meta['proxy'] = ip
# ШчЙћбЛЗДѓгкФГИіжЕ,ОЭЧхРэipГи,ИќЛЛipЕФФкШн
if count['count'] > 50:
print('-------------ЧаЛЛip------------------')
count['count'] = 0
ipPool.clear()
ips = requests.get('ФуЕФipЛёШЁЕФЕижЗ')
for ip in ips.text.split('\r\n'):
ipPool.append('http://' + ip)
# УПДЮЗУЮЪ,МЦЪ§Цї+1
count['count'] += 1
return None
зюКѓОЭЪЧХРГцЮФМўЕФstart_requestsКЏЪ§,ОЭЪЧЕквЛДЮЗЂЧыЧѓЧАвЊЯШЬюТњipГиЕФip
# МЧЕУЕМАќ
from ФуЕФЯюФП.settings import ipPool
import random
import requests
def start_requests(self):
# ЕквЛДЮЧыЧѓЗЂЦ№ЧАЯШЬюГфвЛЯТipГи
ips = requests.get('ФуЕФipЛёШЁЕФЕижЗ')
for ip in ips.text.split('\r\n'):
ipPool.append('http://' + ip)
МђЕЅЕФipДњРэвдМАЙЬЖЈДЮЪ§ОЭИќЛЛipГиОЭЭъГЩСЫ
js