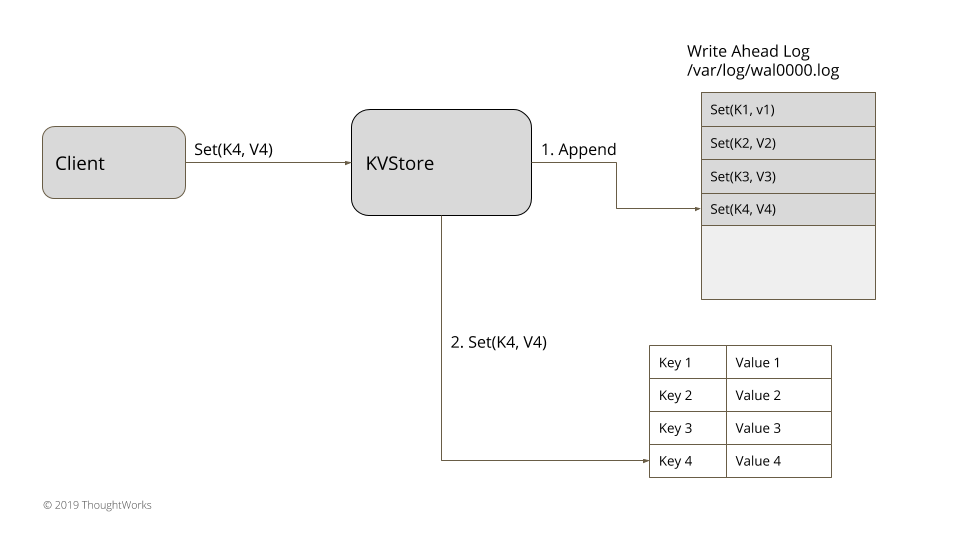
class KVStore {
public KVStore(Config config) {
this.config = config;
this.wal = WriteAheadLog.openWAL(config);
this.applyLog();
}
public void applyLog() {
List<WALEntry> walEntries = wal.readAll();
applyEntries(walEntries);
}
private void applyEntries(List<WALEntry> walEntries) {
for (WALEntry walEntry : walEntries) {
Command command = deserialize(walEntry);
if (command instanceof SetValueCommand) {
SetValueCommand setValueCommand = (SetValueCommand)command;
kv.put(setValueCommand.key, setValueCommand.value);
}
}
}
public void initialiseFromSnapshot(SnapShot snapShot) {
kv.putAll(snapShot.deserializeState());
}
}
实现考虑
首先是保证 WAL 日志真的写入了磁盘。所有编程语言提供的文件处理库提供了一种机制,强制操作系统将文件更改flush落盘。在flush时,需要考虑的是一种权衡。对于日志的每一条记录都flush一次,保证了强持久性,但是严重影响了性能并且很快会成为性能瓶颈。如果是异步flush,性能会提高,但是如果在flush前程序崩溃,则有可能造成日志丢失。大部分的实现都采用批处理,减少flush带来的性能影响,同时也尽量少丢数据。
另外,我们还需要保证日志文件没有损坏。为了处理这个问题,日志条目通常伴随 CRC 记录写入,然后在读取文件时进行验证。
同时,采用单个日志文件可能变得很难管理(很难清理老日志,重启时读取文件过大)。为了解决这个问题,通常采用之前提到的分段日志(Segmented Log)或者最低水位线(Low-Water Mark)来减少程序启动时读取的文件大小以及清理老的日志。
最后,要考虑重试带来的重复问题,也就是幂等性。由于 WAL 日志仅附加,在发生客户端通信失败和重试时,日志可能包含重复的条目。当读取日志条目时,可能会需要确保重复项被忽略。但是如果存储类似于 HashMap,其中对同一键的更新是幂等的,则不需要排重,但是可能会存在 ABA 更新问题。一般都需要实现某种机制来标记每个请求的唯一标识符并检测重复请求。
举例
各种 MQ 中的类似于 CommitLog 的日志
MQ 中的消息存储,由于消息队列的特性导致消息存储和日志类似,所以一般用日志直接作为存储。这个消息存储一般就是 WAL 这种设计模式,以 RocketMQ 为例子:
RocketMQ:
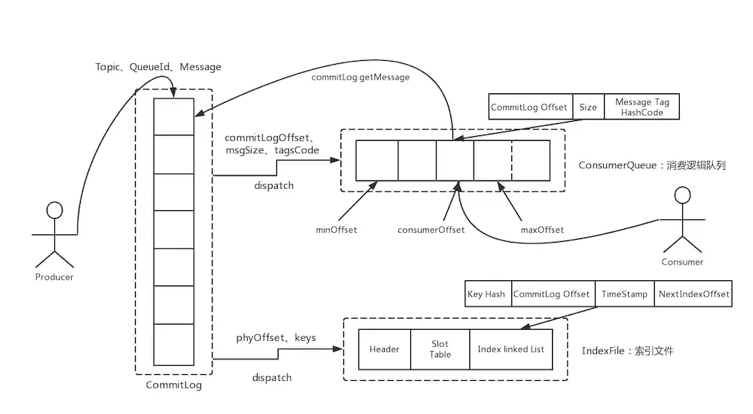
RocketMQ 存储首先将消息存储在 Commitlog 文件之中,这个文件采用的是 mmap (文件映射内存)技术写入与保存。关于这个技术,请参考另一篇文章JDK核心JAVA源码解析(5) - JAVA File MMAP原理解析
当消息来时,写入文件的核心方法是MappedFile的appendMessagesInner方法:
public AppendMessageResult appendMessagesInner(final MessageExt messageExt, final AppendMessageCallback cb) {
assert messageExt != null;
assert cb != null;
//获取当前写入位置
int currentPos = this.wrotePosition.get();
//如果当前写入位置小于文件大小则尝试写入
if (currentPos < this.fileSize) {
//mappedByteBuffer是公用的,在这里不能修改其position影响读取
//mappedByteBuffer是文件映射内存抽象出来的文件的内存ByteBuffer
//对这个buffer的写入,就相当于对文件的写入
//所以通过slice方法生成一个共享原有相同内存的新byteBuffer,设置position
//如果writeBuffer不为空,则证明启用了TransientStorePool,使用其中缓存的内存写入
ByteBuffer byteBuffer = writeBuffer != null ? writeBuffer.slice() : this.mappedByteBuffer.slice();
byteBuffer.position(currentPos);
AppendMessageResult result;
//分单条消息还有批量消息的情况
if (messageExt instanceof MessageExtBrokerInner) {
result = cb.doAppend(this.getFileFromOffset(), byteBuffer, this.fileSize - currentPos, (MessageExtBrokerInner) messageExt);
} else if (messageExt instanceof MessageExtBatch) {
result = cb.doAppend(this.getFileFromOffset(), byteBuffer, this.fileSize - currentPos, (MessageExtBatch) messageExt);
} else {
return new AppendMessageResult(AppendMessageStatus.UNKNOWN_ERROR);
}
//增加写入大小
this.wrotePosition.addAndGet(result.getWroteBytes());
//更新最新消息保存时间
this.storeTimestamp = result.getStoreTimestamp();
return result;
}
log.error("MappedFile.appendMessage return null, wrotePosition: {} fileSize: {}", currentPos, this.fileSize);
return new AppendMessageResult(AppendMessageStatus.UNKNOWN_ERROR);
}
RocketMQ 将消息存储在 Commitlog 文件后,异步更新 ConsumeQueue 还有 Index 文件。这个 ConsumeQueue 还有 Index 文件可以理解为存储状态,CommitLog 在这里扮演的就是 WAL 日志的角色:只有写入到 ConsumeQueue 的消息才会被消费者消费,只有 Index 文件中存在的记录才能被读取定位到。如果消息成功写入 CommitLog 但是异步更新还没执行,RocketMQ 进程挂掉了,这样就存在了不一致。所以在 RocketMQ 启动的时候,会通过如下机制保证 Commitlog 与 ConsumeQueue 还有 Index 的最终一致性.
入口是DefaultMessageStore的load方法:
public boolean load() {
boolean result = true;
try {
//RocketMQ Broker启动时会创建${ROCKET_HOME}/store/abort文件,并添加JVM shutdownhook删除这个文件
//通过这个文件是否存判断是否为正常退出
boolean lastExitOK = !this.isTempFileExist();
log.info("last shutdown {}", lastExitOK ? "normally" : "abnormally");
//加载延迟队列消息,这里先忽略
if (null != scheduleMessageService) {
result = result && this.scheduleMessageService.load();
}
//加载 Commit Log 文件
result = result && this.commitLog.load();
//加载 Consume Queue 文件
result = result && this.loadConsumeQueue();
if (result) {
//加载存储检查点
this.storeCheckpoint =
new StoreCheckpoint(StorePathConfigHelper.getStoreCheckpoint(this.messageStoreConfig.getStorePathRootDir()));
//加载 index,如果不是正常退出,销毁所有索引上次刷盘时间小于索引文件最大消息时间戳的文件
this.indexService.load(lastExitOK);
//进行 recover 恢复之前状态
this.recover(lastExitOK);
log.info("load over, and the max phy offset = {}", this.getMaxPhyOffset());
}
} catch (Exception e) {
log.error("load exception", e);
result = false;
}
if (!result) {
this.allocateMappedFileService.shutdown();
}
return result;
}
进行恢复是DefaultMessageStore的recover方法:
private void recover(final boolean lastExitOK) {
long maxPhyOffsetOfConsumeQueue = this.recoverConsumeQueue();
//根据上次是否正常退出,采用不同的恢复方式
if (lastExitOK) {
this.commitLog.recoverNormally(maxPhyOffsetOfConsumeQueue);
} else {
this.commitLog.recoverAbnormally(maxPhyOffsetOfConsumeQueue);
}
this.recoverTopicQueueTable();
}
当上次正常退出时:
public void recoverNormally(long maxPhyOffsetOfConsumeQueue) {
boolean checkCRCOnRecover = this.defaultMessageStore.getMessageStoreConfig().isCheckCRCOnRecover();
final List<MappedFile> mappedFiles = this.mappedFileQueue.getMappedFiles();
if (!mappedFiles.isEmpty()) {
//只扫描最后三个文件
int index = mappedFiles.size() - 3;
if (index < 0)
index = 0;
MappedFile mappedFile = mappedFiles.get(index);
ByteBuffer byteBuffer = mappedFile.sliceByteBuffer();
long processOffset = mappedFile.getFileFromOffset();
long mappedFileOffset = 0;
while (true) {
//检验存储消息是否有效
DispatchRequest dispatchRequest = this.checkMessageAndReturnSize(byteBuffer, checkCRCOnRecover);
int size = dispatchRequest.getMsgSize();
//如果有效,添加这个偏移
if (dispatchRequest.isSuccess() && size > 0) {
mappedFileOffset += size;
}
//如果有效,但是大小是0,代表到了文件末尾,切换文件
else if (dispatchRequest.isSuccess() && size == 0) {
index++;
if (index >= mappedFiles.size()) {
// Current branch can not happen
log.info("recover last 3 physics file over, last mapped file " + mappedFile.getFileName());
break;
} else {
mappedFile = mappedFiles.get(index);
byteBuffer = mappedFile.sliceByteBuffer();
processOffset = mappedFile.getFileFromOffset();
mappedFileOffset = 0;
log.info("recover next physics file, " + mappedFile.getFileName());
}
}
//只有有无效的消息,就在这里停止,之后会丢弃掉这个消息之后的所有内容
else if (!dispatchRequest.isSuccess()) {
log.info("recover physics file end, " + mappedFile.getFileName());
break;
}
}
processOffset += mappedFileOffset;
this.mappedFileQueue.setFlushedWhere(processOffset);
this.mappedFileQueue.setCommittedWhere(processOffset);
//根据有效偏移量,删除这个偏移量以后的所有文件,以及所有文件(正常是只有最后一个有效文件,而不是所有文件)中大于这个偏移量的部分
this.mappedFileQueue.truncateDirtyFiles(processOffset);
//根据 commit log 中的有效偏移量,清理 consume queue
if (maxPhyOffsetOfConsumeQueue >= processOffset) {
log.warn("maxPhyOffsetOfConsumeQueue({}) >= processOffset({}), truncate dirty logic files", maxPhyOffsetOfConsumeQueue, processOffset);
this.defaultMessageStore.truncateDirtyLogicFiles(processOffset);
}
} else {
//所有commit log都删除了,那么偏移量就从0开始
log.warn("The commitlog files are deleted, and delete the consume queue files");
this.mappedFileQueue.setFlushedWhere(0);
this.mappedFileQueue.setCommittedWhere(0);
this.defaultMessageStore.destroyLogics();
}
}
当上次没有正常退出时:
public void recoverAbnormally(long maxPhyOffsetOfConsumeQueue) {
boolean checkCRCOnRecover = this.defaultMessageStore.getMessageStoreConfig().isCheckCRCOnRecover();
final List<MappedFile> mappedFiles = this.mappedFileQueue.getMappedFiles();
if (!mappedFiles.isEmpty()) {
// 从最后一个文件开始,向前寻找第一个正常的可以恢复消息的文件
// 从这个文件开始恢复消息,因为里面的消息有成功写入过 consumer queue 以及 index 的,所以从这里恢复一定能保证最终一致性
// 但是会造成某些已经写入过 consumer queue 的消息再次写入,也就是重复消费。
int index = mappedFiles.size() - 1;
MappedFile mappedFile = null;
for (; index >= 0; index--) {
mappedFile = mappedFiles.get(index);
//寻找第一个有正常消息的文件
if (this.isMappedFileMatchedRecover(mappedFile)) {
log.info("recover from this mapped file " + mappedFile.getFileName());
break;
}
}
//如果小于0,就恢复所有 commit log,或者代表没有 commit log
if (index < 0) {
index = 0;
mappedFile = mappedFiles.get(index);
}
ByteBuffer byteBuffer = mappedFile.sliceByteBuffer();
long processOffset = mappedFile.getFileFromOffset();
long mappedFileOffset = 0;
while (true) {
//验证消息有效性
DispatchRequest dispatchRequest = this.checkMessageAndReturnSize(byteBuffer, checkCRCOnRecover);
int size = dispatchRequest.getMsgSize();
//如果消息有效
if (dispatchRequest.isSuccess()) {
if (size > 0) {
mappedFileOffset += size;
if (this.defaultMessageStore.getMessageStoreConfig().isDuplicationEnable()) {
//如果允许消息重复转发,则需要判断当前消息是否消息偏移小于已确认的偏移,只有小于的进行重新分发
if (dispatchRequest.getCommitLogOffset() < this.defaultMessageStore.getConfirmOffset()) {
//重新分发消息,也就是更新 consume queue 和 index
this.defaultMessageStore.doDispatch(dispatchRequest);
}
} else {
//重新分发消息,也就是更新 consume queue 和 index
this.defaultMessageStore.doDispatch(dispatchRequest);
}
}
//大小为0代表已经读完,切换下一个文件
else if (size == 0) {
index++;
if (index >= mappedFiles.size()) {
// The current branch under normal circumstances should
// not happen
log.info("recover physics file over, last mapped file " + mappedFile.getFileName());
break;
} else {
mappedFile = mappedFiles.get(index);
byteBuffer = mappedFile.sliceByteBuffer();
processOffset = mappedFile.getFileFromOffset();
mappedFileOffset = 0;
log.info("recover next physics file, " + mappedFile.getFileName());
}
}
} else {
log.info("recover physics file end, " + mappedFile.getFileName() + " pos=" + byteBuffer.position());
break;
}
}
//更新偏移
processOffset += mappedFileOffset;
this.mappedFileQueue.setFlushedWhere(processOffset);
this.mappedFileQueue.setCommittedWhere(processOffset);
this.mappedFileQueue.truncateDirtyFiles(processOffset);
//清理
if (maxPhyOffsetOfConsumeQueue >= processOffset) {
log.warn("maxPhyOffsetOfConsumeQueue({}) >= processOffset({}), truncate dirty logic files", maxPhyOffsetOfConsumeQueue, processOffset);
this.defaultMessageStore.truncateDirtyLogicFiles(processOffset);
}
}
// Commitlog case files are deleted
else {
log.warn("The commitlog files are deleted, and delete the consume queue files");
this.mappedFileQueue.setFlushedWhere(0);
this.mappedFileQueue.setCommittedWhere(0);
this.defaultMessageStore.destroyLogics();
}
}
总结起来就是:
- 首先,根据 abort 文件是否存在判断上次是否正常退出。
- 对于正常退出的:
- 扫描倒数三个文件,记录有效消息的偏移
- 扫描到某个无效消息结束,或者扫描完整个文件
- 设置最新偏移,同时根据这个偏移量清理 commit log 和 consume queue
- 对于没有正常退出的:
- 从最后一个文件开始,向前寻找第一个正常的可以恢复消息的文件
- 从这个文件开始恢复并重发消息,因为里面的消息有成功写入过 consumer queue 以及 index 的,所以从这里恢复一定能保证最终一致性。但是会造成某些已经写入过 consumer queue 的消息再次写入,也就是重复消费。
- 更新偏移,清理
数据库
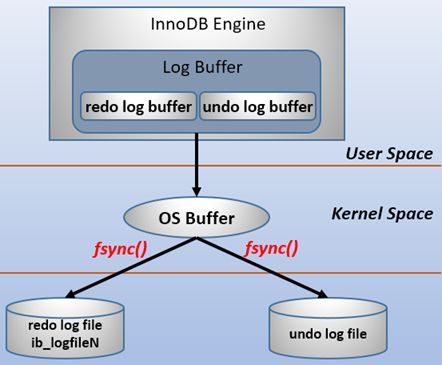
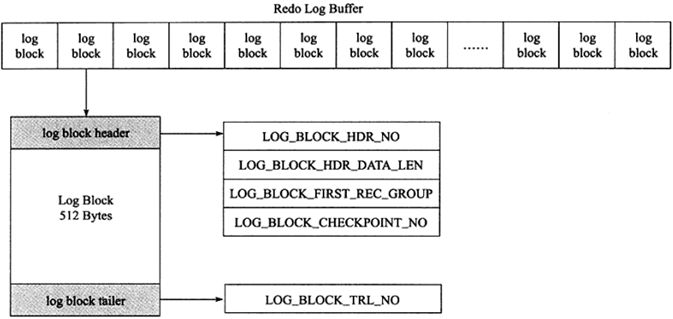
基本上所有的数据库都会有 WAL 类似的设计,例如 MySQL 的 Innodb redo log 等等。
一致性存储
例如 ZK 还有 ETCD 这样的一致性中间件。
bk