前言
今天分享一下日常工作中遇到的性能问题和解决方案,比较零碎,后续会持续更新(运行环境为.net core 3.1)
本次分享的案例都是由实际生产而来,经过简化后作为举例
Part 1(作为简单数据载体时class和struct的性能对比)
关于class和struct的区别,根据经验,在实际开发的绝大多数场景,都会使用class作为数据类型,但是如果是作为简单数据的超大集合的类型,并且不涉及到拷贝、传参等其他操作的时候,可以考虑使用struct,因为相对于引用类型的class分配在堆上,作为值类型的struct是分配在栈上的,这样就拥有了更快的创建速度和节约了指针的空间,列举了3000万个元素的集合分别以class和struct作为类型,做如下测试(测试工具为vs自带的 Diagnostic Tools):
class Program {
static void Main (string[] args) {
var structs = new List<StructTest> ();
var stopwatch1 = new Stopwatch ();
stopwatch1.Start ();
for (int i = 0; i < 30000000; i++) {
structs.Add (new StructTest { Id = i, Value = i });
}
stopwatch1.Stop ();
var structsTotalMemory = GC.GetTotalMemory (true);
Console.WriteLine ($"使用结构体时消耗内存:{structsTotalMemory}字节,耗时:{stopwatch1.ElapsedMilliseconds}毫秒");
Console.ReadLine ();
}
public struct StructTest {
public int Id { get; set; }
public int Value { get; set; }
}
}

class Program {
static void Main (string[] args) {
var classes = new List<ClassTest> ();
var stopwatch2 = new Stopwatch ();
stopwatch2.Start ();
for (int i = 0; i < 30000000; i++) {
classes.Add (new ClassTest { Id = i, Value = i });
}
stopwatch2.Stop ();
var classesTotalMemory = GC.GetTotalMemory (true);
Console.WriteLine ($"使用类时消耗内存:{classesTotalMemory}字节,耗时:{ stopwatch2.ElapsedMilliseconds}毫秒");
Console.ReadLine ();
}
public struct StructTest {
public int Id { get; set; }
public int Value { get; set; }
}
}

通过计算,struct的空间消耗包含了:每个结构体包含两个存放在栈上的整型,每个整型占4个字节,每个结构体占8字节,乘以3000万个元素共计占用240,000,000字节, 跟实际测量值大体吻合;
而class的空间消耗较为复杂,包含了:每个类包含两个存在堆上的整型,每个整型占4字节,两个存在栈上的指针,因为是64位计算机所以每个指针占8字节,再加上类自身的指针8字节,每个类占24字节(4+4+8+8+8),乘以3000万个元素共计占用960,000,000字节,跟实际测量值大体吻合。时间消耗方面class因为存在内存分配,耗时5秒左右,远大于struct的1.5秒。
基于此次测试,
更多关于class和struct的关系和区别请移步微软官方文档 https://docs.microsoft.com/en-us/dotnet/standard/design-guidelines/choosing-between-class-and-struct
Part 2(集合嵌套遍历的优化)
关于嵌套集合遍历,我们以两层集合嵌套遍历,每个集合存放10000个乱序的整型,然后统计同时存在两个集合的元素个数,从上到下分别以常规嵌套循环,使用HashSet类型,参考PostgreSQL的MergeJoin思路举例:
class Program {
static void Main (string[] args) {
var l1s = new List<int> ();
var l2s = new List<int> ();
var rd = new Random ();
for (int i = 0; i < 10000; i++) {
l1s.Add (rd.Next (1, 10000));
l2s.Add (rd.Next (1, 10000));
}
var sw = new Stopwatch ();
sw.Start ();
var r = new HashSet<int> ();
foreach (var l1 in l1s) {
foreach (var l2 in l2s) {
if (l1 == l2) {
r.Add (l1);
}
}
}
sw.Stop ();
Console.WriteLine ($"共找到{r.Count}个元素同时存在于l1s和l2s,共计耗时{sw.ElapsedMilliseconds}毫秒");
Console.ReadLine ();
}

class Program {
static void Main (string[] args) {
var l1s = new HashSet<int> ();
var l2s = new HashSet<int> ();
var rd = new Random ();
while (l1s.Count < 10000)
l1s.Add (rd.Next (1, 100000));
while (l2s.Count < 10000)
l2s.Add (rd.Next (1, 100000));
var sw = new Stopwatch ();
sw.Start ();
var r = new List<int> ();
foreach (var l1 in l1s) {
if (l2s.Contains (l1)) {
r.Add (l1);
}
}
sw.Stop ();
Console.WriteLine ($"共找到{r.Count}个元素同时存在于l1s和l2s,共计耗时{sw.ElapsedMilliseconds}毫秒");
Console.ReadLine ();
}
class Program {
static void Main (string[] args) {
var l1s = new List<int> ();
var l2s = new List<int> ();
var rd = new Random ();
for (int i = 0; i < 10000; i++) {
l1s.Add (rd.Next (1, 10000));
l2s.Add (rd.Next (1, 10000));
}
var sw = new Stopwatch ();
sw.Start ();
var r = new List<int> ();
l1s = l1s.OrderBy (x => x).ToList ();
l2s = l2s.OrderBy (x => x).ToList ();
var l1index = 0;
var l2index = 0;
for (int i = 0; i < 10000; i++) {
var l1v = l1s[l1index];
var l2v = l2s[l2index];
if (l1v == l2v) {
r.Add (l1v);
l1index++;
l2index++;
}
if (l1v > l2v && l2index < 10000)
l2index++;
if (l1v < l2v && l1index < 10000)
l1index++;
if (l1index == 9999 && l2index == 9999)
break;
}
sw.Stop ();
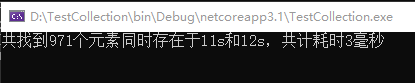
Console.WriteLine ($"共找到{r.Count}个元素同时存在于l1和l2s,共计耗时{sw.ElapsedMilliseconds}毫秒");
Console.ReadLine ();
}

由结果可见,常规嵌套遍历耗时1秒,时间复杂度为O(n2);使用HashSet耗时3毫秒,HashSet底层使用了哈希表,通过循环外层集合,对内层集合直接进行hash查找,时间复杂度为O(n); 参考PostgreSQL的MergeJoin思路实现耗时19毫秒,方法为先对集合进行排序,再标记当前位移,利用数组可以下标直接取值的特性取值后对比,时间复杂度为O(n)。由此可见,对于数据量较大的集合,嵌套循环要尤为重视起来。
更多关于merge join的设计思路请移步PostgreSQL的官方文档 https://www.postgresql.org/docs/12/planner-optimizer.html
要注意的是,无论是使用哈希表还是排序,都会引入额外的损耗,毕竟在计算机的世界里,要么以时间换空间,要么以空间换时间,如果想同时优化时间或空间可以办到吗?在某些场景上也是有可能的,可以参考我之前的博文,通过内存映射文件结合今天讲的内容,结合具体业务场景尝试一下。
如有任何问题,欢迎大家随时指正,分享和试错也是个学习的过程,谢谢大家~