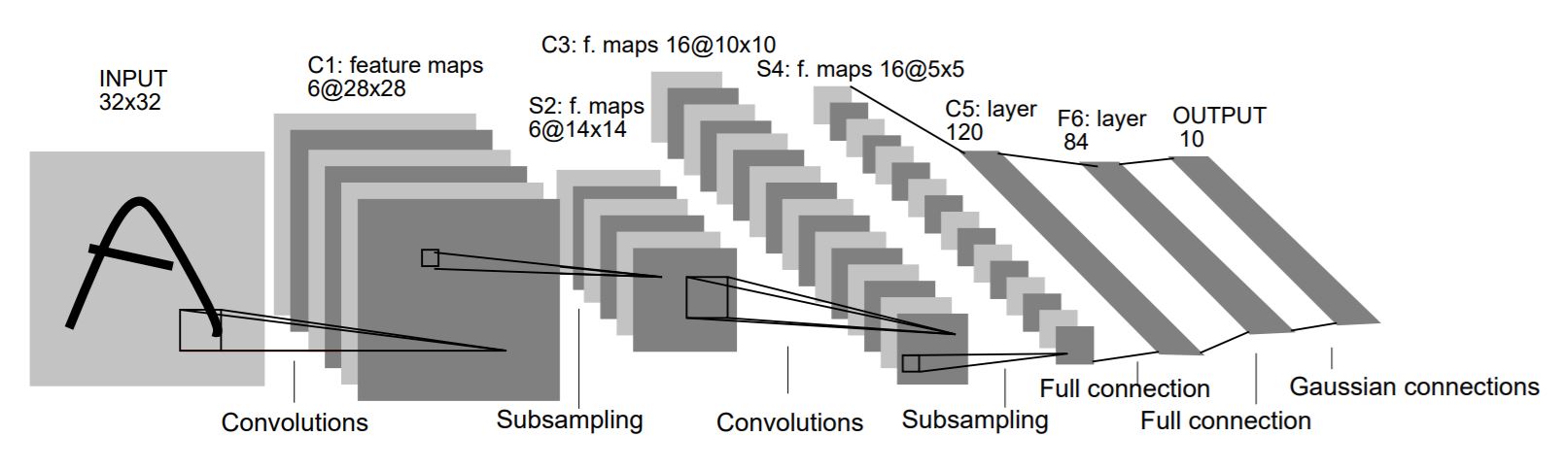
def __init__(self, in_channel, out_channel, kernel_size = 5):
super(MapConv, self).__init__()
#定义特征图的映射方式
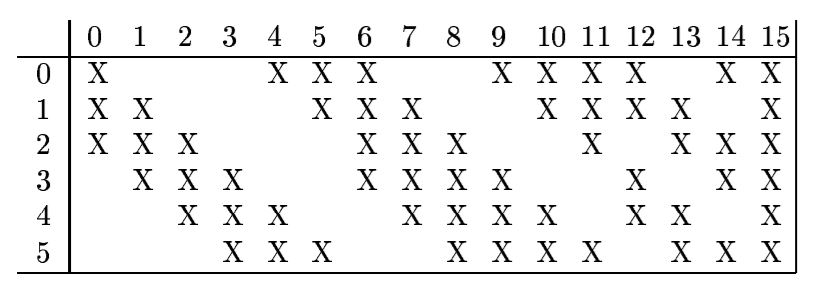
mapInfo = [[1, 0, 0, 0, 1, 1, 1, 0, 0, 1, 1, 1, 1, 0, 1, 1],
[1, 1, 0, 0, 0, 1, 1, 1, 0, 0, 1, 1, 1, 1, 0, 1],
[1, 1, 1, 0, 0, 0, 1, 1, 1, 0, 0, 1, 0, 1, 1, 1],
[0, 1, 1, 1, 0, 0, 1, 1, 1, 1, 0, 0, 1, 0, 1, 1],
[0, 0, 1, 1, 1, 0, 0, 1, 1, 1, 1, 0, 1, 1, 0, 1],
[0, 0, 0, 1, 1, 1, 0, 0, 1, 1, 1, 1, 0, 1, 1, 1]]
mapInfo = torch.tensor(mapInfo, dtype = torch.long)
self.register_buffer("mapInfo", mapInfo) #在Module中的buffer中的参数是不会被求梯度的
self.in_channel = in_channel
self.out_channel = out_channel
self.convs = {} #将每一个定义的卷积层都放进这个字典
#对每一个新建立的卷积层都进行注册,使其真正成为模块并且方便调用
for i in range(self.out_channel):
conv = nn.Conv2d(mapInfo[:, i].sum().item(), 1, kernel_size)
convName = "conv{}".format(i)
self.convs[convName] = conv
self.add_module(convName, conv)
这个里面就用到了我们之前提到的在Module里面重要的三个字典中的剩下两个,可能对于萌新小伙伴来说,这段代码初看起来真的复杂地要死,所以这里我们来一点点地解读这个函数。
首先,对于调用父类进行初始化,然后定义我们的映射信息这些部分我们就不看了,没啥看头,重点是我们来看一下下面这一行代码:
self.register_buffer("mapInfo", mapInfo)
在前面说三大字典的时候我们提到过,在Module的_buffer中的参数是不会被求导的,可以看成是常量。但是如果直接定义一个量放在Module里面的话,他实际上并没有被放在_buffer中,因此我们需要调用从Module类中继承得到的register_buffer方法,来将我们定义的mapInfo强制注册到_buffer这个字典中。
接下来比较重要的是下面的for循环部分:
for i in range(self.out_channel):
conv = nn.Conv2d(mapInfo[:, i].sum().item(), 1, kernel_size)
convName = "conv{}".format(i)
self.convs[convName] = conv
self.add_module(convName, conv)
为什么不能像之前那样一个一个定义卷积层呢?很简单,因为这里如果一个一个做的话,要自己定义16个卷积层,而且到写forward函数中,还要至少写16次输出······反正我是写不来,如果有铁头娃想这么写的话可以去试一下,那滋味一定是酸爽得要死┓( ′?` )┏
首先是关于每一个单独的卷积层的定义部分:
conv = nn.Conv2d(mapInfo[:, i].sum().item(), 1, kernel_size)
前面我们提到,C3卷积层中的每一个特征图都是从前面的输入里面挑出几个来做卷积的,并且讲那个映射图的时候说过要一列一列地读,也就是说卷积层的输入的通道数in_channels是由mapInfo里面每一列有几个 “1”(X)决定的。
接下来是整个循环的剩余部分:
convName = "conv{}".format(i)
self.convs[convName] = conv
self.add_module(convName, conv)
这部分看起来稍稍有一点复杂,但实际上逻辑还是蛮简单的。在我们自定义的Module的子类中,如果里面有其他的Module子类作为成员(比如Conv2d),那么框架会将这个子类的实例化对象的对象名作为key,实际对象作为value注册到_module中,但是由于这里我们使用的是循环,所以卷积层的对象名就只有conv一个。
为了解决这个问题,我们可以自行定义一个字典convs,然后将自行定义的convName作为key,实际对象作为value,放到这个自定义的字典里面。但是放到这个字典还是没有被注册进_module里面,因此我们需要用从Module类中继承的add_module()方法,将(convName,conv)作为键值对注册到字典里面,这样我们才能在forward方法中,直接调用convs字典中的内容用来进行卷积计算。详细的关于这部分的说明还是参考一下我在上面提到的两个博客的链接。
解释完这个函数之后,接下来是forward函数:
def forward(self, x):
outs = [] #对每一个卷积层通过映射来计算卷积,结果存储在这里
for i in range(self.out_channel):
mapIdx = self.mapInfo[:, i].nonzero().squeeze()
convInput = x.index_select(1, mapIdx)
convOutput = self.convs['conv{}'.format(i)](convInput)
outs.append(convOutput)
return torch.cat(outs, dim = 1)
我们还是直接来看for循环里面的部分,其实这部分如果是有numpy基础的人会觉得很简单,但是毕竟这是面向小白和萌新的博客,所以就稍微听我啰嗦一下吧。
由于我们在看mapInfo的时候是按列看的,也就是说为了取到每一个输出特征图对应的输入特征图,我们应该把mapInfo每一列的非零元素的下标取出来,也就是mapInfo[:, i].nonzero()。nonzero这个函数的返回值是调用这个函数的tensor里面的,所有非零元素的下标,并且每一个非零点下标自成一维。举个例子的话,对mapInfo的第0列,调用nonzero的结果应该是:
[[0], [1], [2]],shape:[3, 1]
之所以要在后面加一个squeeze,是因为后续的index_select函数,这个操作要求要求后面对应的下标序列必须是一个一维的,也就是说需要把[[0], [1], [2]]变成[0, 1, 2],从shape:[3, 1]变成shape:[3],因此需要一个squeeze操作进行压缩。
接下来就是刚刚才提到的index_select操作,这个函数实际上是下面这个样子:
index_select(dim, index)
还有一些其他参数就不列出来了,这个函数的功能是,在指定的dim维度上,根据index指定的索引,将对应的所有元素进行一个返回。
对于我们编写的函数来说,x的shape是[batch_size, c, h, w],而我们需要从里面找到的是从mapInfo中找到的所有非零的channel,也就是说我们需要指定dim=1,也就是convInput = x.index_select(1, mapIdx)
剩下的内容就和之前介绍的Subsampling的内容差不多了,同样的对于每一组输入得到一组卷积,然后最后把所有卷积结果拼起来。
那现在我们把这个类的完整的代码放在一起好啦:
class MapConv(nn.Module):
def __init__(self, in_channel, out_channel, kernel_size = 5):
super(MapConv, self).__init__()
#定义特征图的映射方式
mapInfo = [[1, 0, 0, 0, 1, 1, 1, 0, 0, 1, 1, 1, 1, 0, 1, 1],
[1, 1, 0, 0, 0, 1, 1, 1, 0, 0, 1, 1, 1, 1, 0, 1],
[1, 1, 1, 0, 0, 0, 1, 1, 1, 0, 0, 1, 0, 1, 1, 1],
[0, 1, 1, 1, 0, 0, 1, 1, 1, 1, 0, 0, 1, 0, 1, 1],
[0, 0, 1, 1, 1, 0, 0, 1, 1, 1, 1, 0, 1, 1, 0, 1],
[0, 0, 0, 1, 1, 1, 0, 0, 1, 1, 1, 1, 0, 1, 1, 1]]
mapInfo = torch.tensor(mapInfo, dtype = torch.long)
self.register_buffer("mapInfo", mapInfo) #在Module中的buffer中的参数是不会被求梯度的
self.in_channel = in_channel
self.out_channel = out_channel
self.convs = {} #将每一个定义的卷积层都放进这个字典
#对每一个新建立的卷积层都进行注册,使其真正成为模块并且方便调用
for i in range(self.out_channel):
conv = nn.Conv2d(mapInfo[:, i].sum().item(), 1, kernel_size)
convName = "conv{}".format(i)
self.convs[convName] = conv
self.add_module(convName, conv)
def forward(self, x):
outs = [] #对每一个卷积层通过映射来计算卷积,结果存储在这里
for i in range(self.out_channel):
mapIdx = self.mapInfo[:, i].nonzero().squeeze()
convInput = x.index_select(1, mapIdx)
convOutput = self.convs['conv{}'.format(i)](convInput)
outs.append(convOutput)
return torch.cat(outs, dim = 1)
考虑到我们在开头提到的输入输出尺寸以及参数,最后我们应该做的定义如下所示:
self.C3 = MapConv(6, 16, 5)
和C1一样,这一层的后面也是没有激活函数的。
S4层
这个就很简单啦,就是把我们之前定义的Subsampling类拿过来用就行了,这里就说一下输入输出的尺寸还有参数好啦:
-
输入尺寸:C3的输出:[16, 10, 10]
-
输出尺寸:根据池化的核的大小,尺寸应该为[16, 5, 5]
-
参数:从输入的通道数判断,in_channel = 16
写出来的话应该是:
self.S4 = Subsampling(16)
这一层后面有激活函数,出现的问题和S2层一样,原因之后说
C5层
这个也好简单哟啊哈哈哈哈哈,再复杂下去我可能就要被逼疯了。
和C1层一样,这里是一个简单的卷积层,我们来分析一下输入输出尺寸以及定义参数:
-
输入尺寸:[16, 5, 5]
-
输出尺寸:[120, 1, 1]
-
参数:
- in_channel: 16
- out_channel: 120
- kernel_size: 5
- stride: 1
- padding: 0
写出来的话应该是这样的:
self.C5 = nn.Conv2d(16, 120, 5)
这里同样没有激活函数
F6层
这个也好简单啊哈哈哈哈哈(喂?120吗,这里有个疯子麻烦你们来处理一下)
这里是一个简单的线性全连接层,我们看到上一层的输入尺寸为[120, 1, 1],而线性层在不考虑batch_size的时候,要求输入维度不能这么多,这就需要用到view函数进行维度的重组,当然啦我们这一部分可以放到forward函数里面,这里我们就直接定义一个线性层就好啦:
self.F6 = nn.Linear(120, 84)
这里有一个激活函数,使用的就是和之前的LeNet-1989一样的:
\[y=1.7159Tanh({{2} \over {3} }x)
\]
Output层
终于要到最后了,我的妈啊,除了本科毕设我还是头一次日常写东西写这么多的,可把我累坏了。本来还想着最后一层能让人歇歇,结果发现最后一层虽然逻辑很简单,但是从代码行数来看真是恶心得一匹,因为里面涉及到一些数字编码的问题。总之我们先往下看一看吧。
这一层的操作也是“刀剑神域” 得不得了,论文在设计这一层的时候实际上相当于是在做一个特征匹配的工作。论文是将0-9这十个数字的像素编码提取出来,然后将这个像素编码展开形成一个向量。在F6层我们知道输出的向量的尺寸是[84],这个Output层的任务,就是求解F6层输出向量,和0-9的每一个展开成行向量的像素编码求一个平方和的距离,保证这个是一个正值。从结果上讲,如果这个距离是0,那就说明输出向量和该数字对应的行向量完全匹配。距离越小证明越接近,也就是概率越大;距离越大就证明越远离,也就是概率越低。
可能只是这么说有一点点不太好理解,我们来举个例子说明也许会更容易说明一些。我们先来看一下 “1”这个数字的编码大概长什么样子。为了让大家看得比较清楚,本来应该是黑色是+1,白色是-1,我这边就写成黑色是1,白色是0好了。
[0, 0, 0, 1, 1, 0, 0],
[0, 0, 1, 1, 1, 0, 0],
[0, 1, 1, 1, 1, 0, 0],
[0, 0, 0, 1, 1, 0, 0],
[0, 0, 0, 1, 1, 0, 0],
[0, 0, 0, 1, 1, 0, 0],
[0, 0, 0, 1, 1, 0, 0],
[0, 0, 0, 1, 1, 0, 0],
[0, 0, 0, 1, 1, 0, 0],
[1, 1, 1, 1, 1, 1, 1],
[0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0]