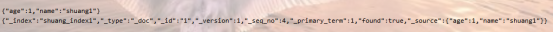{"took":770,"timed_out":false,"_shards":{"total":1,"successful":1,"skipped":0,"failed":0},"hits":{"total":{"value":5,"relation":"eq"},"max_score":0.08701137,"hits":[{"_index":"shuang_index2","_type":"_doc","_id":"1","_score":0.08701137,"_source":{"name":"shuang a","age":"1"}},{"_index":"shuang_index2","_type":"_doc","_id":"2","_score":0.08701137,"_source":{"name":"shuang b","age":"2"}},{"_index":"shuang_index2","_type":"_doc","_id":"3","_score":0.08701137,"_source":{"name":"shuang c","age":"3"}},{"_index":"shuang_index2","_type":"_doc","_id":"4","_score":0.08701137,"_source":{"name":"shuang d","age":"4"}},{"_index":"shuang_index2","_type":"_doc","_id":"5","_score":0.08701137,"_source":{"name":"shuang e","age":"5"}}]}}
{name=shuang a, age=1}
{name=shuang b, age=2}
{name=shuang c, age=3}
{name=shuang d, age=4}
{name=shuang e, age=5}
十一,es集群

如图3个es服务构成的集群,索引test分成了5片,一个副本(粗框的),而book一个分片一个副本。保证了如果有一个服务坏了,其他服务也能执行所有工作。
一个搜索请求必须询问请求的索引中所有分片的某个副本来进行匹配。假设一个索引有5个主分片,每个主分片有1个副分片,共10个分片,一次搜索请求会由5个分片来共同完成,它们可能是主分片,也可能是副分片。也就是说,一次搜索请求只会命中所有分片副本中的一个。
ElasticSearch极简入门总结就结束了感谢您的阅读