词频统计,大数据,hadoop实验平台
节点功能规划
操作系统:CentOS7.2(1511)
Java JDK版本:jdk-8u65-linux-x64.tar.gz
Hadoop版本:hadoop-2.8.3.tar.gz
下载地址:
链接:https://pan.baidu.com/s/1iQfjO-d2ojA6mAeOOKb6CA
提取码:l0qp
| node1 |
node2 |
node3 |
| NameNode |
ResourceManage |
|
| DataNode |
DataNode |
DataNode |
| NodeManager |
NodeManager |
NodeManager |
| HistoryServer |
|
SecondaryNameNode |
配置主机IP地址和主机名称
三始主机分别命名为:node1,node2,node3,IP地址和主机名称对应关系如下:
| 序号 |
主机名 |
IP地址 |
备注 |
| 1 |
node1 |
192.168.100.11 |
主节点 |
| 2 |
node2 |
192.168.100.12 |
从节点 |
| 3 |
node3 |
192.168.100.13 |
从节点 |
修改主机名
在三个节点上分别执行修改主机名的命令:
node1:
[root@localhost ~]# hostnamectl set-hostname node1
node2:
[root@localhost ~]# hostnamectl set-hostname node2
node3:
[root@localhost ~]# hostnamectl set-hostname node3
按ctrl+d快捷键或输入exit,退出终端,重新登录后,查看主机名,如下图所示:

修改IP地址
以node1节点为例,在三个节点执行修改IP地址的操作(注意网卡名称因机器的不同可能不一样,例如,node1的网卡名为:eno16777736):
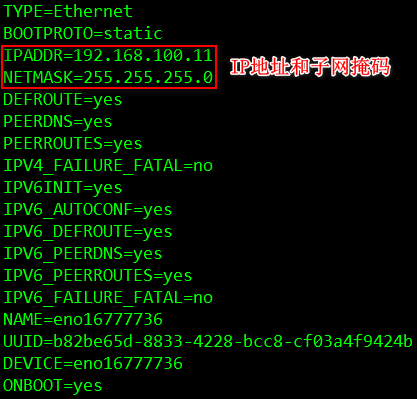
[root@node1 ~]# vi /etc/sysconfig/network-scripts/ifcfg-eno16777736
将node1,node2,node3节点的IP地址分别设置为:192.168.100.11,192.168.100.12,192.168.100.13
修改主机映射
在三个节点分别执行如下操作,添加主机名和IP地址的映射关系:
[root@node1 ~]# vi /etc/hosts

配置节点主机之间的免密登录
生成本节点公钥
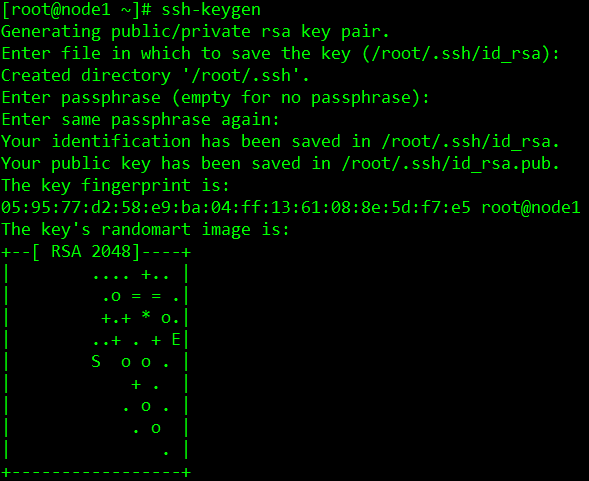
在node1,node2,node3三个节点上分别执行生成密钥的命令(遇到选择项,直接按回国键Enter):
[root@node1 ~]# ssh-keygen
进入.ssh目录,查看生成的公钥:
[root@node1 ~]# cd ~/.ssh/
[root@node1 .ssh]# ls
id_rsa id_rsa.pub
拷贝公钥
将生成的公钥拷贝至节点(包括自身节点):
node1节点:
[root@node1 .ssh]# ssh-copy-id -i id_rsa.pub root@node1
The authenticity of host 'node1 (192.168.100.11)' can't be established.
ECDSA key fingerprint is e1:6c:f3:7f:be:79:dc:87:15:97:51:4d:e5:b4:56:78.
Are you sure you want to continue connecting (yes/no)? yes
/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
root@node1's password:
Number of key(s) added: 1
Now try logging into the machine, with: "ssh 'root@node1'"
and check to make sure that only the key(s) you wanted were added.
[root@node1 .ssh]# ssh-copy-id -i id_rsa.pub root@node2
The authenticity of host 'node2 (192.168.100.12)' can't be established.
ECDSA key fingerprint is e1:6c:f3:7f:be:79:dc:87:15:97:51:4d:e5:b4:56:78.
Are you sure you want to continue connecting (yes/no)? yes
/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
root@node2's password:
Number of key(s) added: 1
Now try logging into the machine, with: "ssh 'root@node2'"
and check to make sure that only the key(s) you wanted were added.
[root@node1 .ssh]# ssh-copy-id -i id_rsa.pub root@node3
The authenticity of host 'node3 (192.168.100.13)' can't be established.
ECDSA key fingerprint is e1:6c:f3:7f:be:79:dc:87:15:97:51:4d:e5:b4:56:78.
Are you sure you want to continue connecting (yes/no)? yes
/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
root@node3's password:
Number of key(s) added: 1
Now try logging into the machine, with: "ssh 'root@node3'"
and check to make sure that only the key(s) you wanted were added.
node2节点:
[root@node2 .ssh]# ssh-copy-id -i id_rsa.pub root@node1
The authenticity of host 'node1 (192.168.100.11)' can't be established.
ECDSA key fingerprint is e1:6c:f3:7f:be:79:dc:87:15:97:51:4d:e5:b4:56:78.
Are you sure you want to continue connecting (yes/no)? yes
/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
root@node1's password:
Number of key(s) added: 1
Now try logging into the machine, with: "ssh 'root@node1'"
and check to make sure that only the key(s) you wanted were added.
[root@node2 .ssh]# ssh-copy-id -i id_rsa.pub root@node2
The authenticity of host 'node2 (192.168.100.12)' can't be established.
ECDSA key fingerprint is e1:6c:f3:7f:be:79:dc:87:15:97:51:4d:e5:b4:56:78.
Are you sure you want to continue connecting (yes/no)? yes
/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
root@node2's password:
Number of key(s) added: 1
Now try logging into the machine, with: "ssh 'root@node2'"
and check to make sure that only the key(s) you wanted were added.
[root@node2 .ssh]# ssh-copy-id -i id_rsa.pub root@node3
The authenticity of host 'node3 (192.168.100.13)' can't be established.
ECDSA key fingerprint is e1:6c:f3:7f:be:79:dc:87:15:97:51:4d:e5:b4:56:78.
Are you sure you want to continue connecting (yes/no)? yes
/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
root@node3's password:
Number of key(s) added: 1
Now try logging into the machine, with: "ssh 'root@node3'"
and check to make sure that only the key(s) you wanted were added.
node3节点:
[root@node3 .ssh]# ssh-copy-id -i id_rsa.pub root@node1
The authenticity of host 'node1 (192.168.100.11)' can't be established.
ECDSA key fingerprint is e1:6c:f3:7f:be:79:dc:87:15:97:51:4d:e5:b4:56:78.
Are you sure you want to continue connecting (yes/no)? yes
/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
root@node1's password:
Number of key(s) added: 1
Now try logging into the machine, with: "ssh 'root@node1'"
and check to make sure that only the key(s) you wanted were added.
[root@node3 .ssh]# ssh-copy-id -i id_rsa.pub root@node2
The authenticity of host 'node2 (192.168.100.12)' can't be established.
ECDSA key fingerprint is e1:6c:f3:7f:be:79:dc:87:15:97:51:4d:e5:b4:56:78.
Are you sure you want to continue connecting (yes/no)? yes
/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
root@node2's password:
Number of key(s) added: 1
Now try logging into the machine, with: "ssh 'root@node2'"
and check to make sure that only the key(s) you wanted were added.
[root@node3 .ssh]# ssh-copy-id -i id_rsa.pub root@node3
The authenticity of host 'node3 (192.168.100.13)' can't be established.
ECDSA key fingerprint is e1:6c:f3:7f:be:79:dc:87:15:97:51:4d:e5:b4:56:78.
Are you sure you want to continue connecting (yes/no)? yes
/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
root@node3's password:
Number of key(s) added: 1
Now try logging into the machine, with: "ssh 'root@node3'"
and check to make sure that only the key(s) you wanted were added.
测试免密登录
在三个节点上分别执行命令,访问相关节点(含自身节点),如果不需要输入密码进行身份验证,则表示成功(以node3节点上的操作为例):
[root@node3 .ssh]# ssh node1
Last login: Thu Jan 21 11:32:29 2021 from 192.168.100.1
[root@node1 ~]# exit
logout
Connection to node1 closed.
[root@node3 .ssh]# ssh node2
Last login: Thu Jan 21 16:01:47 2021 from node1
[root@node2 ~]# exit
logout
Connection to node2 closed.
[root@node3 .ssh]# ssh node3
Last login: Thu Jan 21 16:01:59 2021 from node1
[root@node3 ~]# exit
logout
Connection to node3 closed.
关闭防火墙
三个节点都要执行:
[root@node1 .ssh]# systemctl stop firewalld
[root@node1 .ssh]# systemctl disable firewalld
Removed symlink /etc/systemd/system/dbus-org.fedoraproject.FirewallD1.service.
Removed symlink /etc/systemd/system/basic.target.wants/firewalld.service.
设置Selinux
三个节点都要设置selinux为disabled:
[root@node1 ~]# vi /etc/selinux/config

将selinux设置为disabled后,需要重启机器生效,也可以执行如下命令,将selinux设置为permissive(同样也要在三个节点操作):
[root@node1 ~]# setenforce 0
[root@node1 ~]# getenforce
Permissive
配置Java环境
在node1节点下创建目录/opt/jdk,将jdk包上传至此目录:
[root@node1 ~]# mkdir -p /opt/jdk
[root@node1 ~]# cd /opt/jdk
[root@node1 jdk]# ls
jdk-8u65-linux-x64.tar.gz
解压缩jdk-8u65-linux-x64.tar.gz至当前目录,完成后删除压缩包:
[root@node1 jdk]# tar zxvf jdk-8u65-linux-x64.tar.gz
[root@node1 jdk]# rm -f jdk-8u65-linux-x64.tar.gz
修改/etc/profile文件,添加Java环境配置信息:
[root@node1 jdk]# vi /etc/profile
#Java Start
export JAVA_HOME=/opt/jdk/jdk1.8.0_65
export PATH=$PATH:${JAVA_HOME}/bin
export CLASSPATH=.:${JAVA_HOME}/jre/lib/rt.jar:${JAVA_HOME}/lib/dt.jar:${JAVA_HOME}/lib/tools.jar
#Java End
使用Java环境配置信息生效:
[root@node1 jdk]# source /etc/profile
[root@node1 jdk]# java -version
java version "1.8.0_65"
Java(TM) SE Runtime Environment (build 1.8.0_65-b17)
Java HotSpot(TM) 64-Bit Server VM (build 25.65-b01, mixed mode)
配置Hadoop环境
在node1节点下创建目录/opt/hadoop,将hadoop包上传至此目录:
[root@node1 ~]# mkdir -p /opt/hadoop
[root@node1 ~]# cd /opt/hadoop/
[root@node1 hadoop]# ls
hadoop-2.8.3.tar.gz
解压缩hadoop-2.8.3.tar.gz至当前目录,完成后删除压缩包:
[root@node1 hadoop]# tar zxvf hadoop-2.8.3.tar.gz
[root@node1 hadoop]# rm -f hadoop-2.8.3.tar.gz
添加Java环境信息
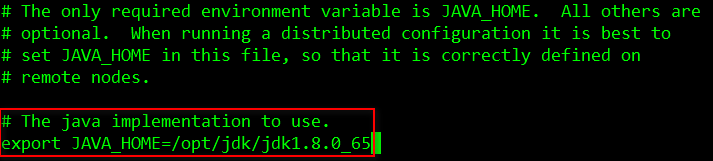
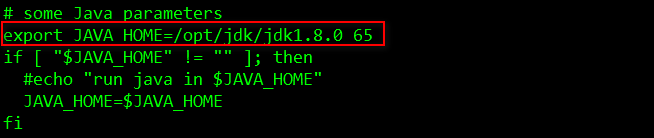
依次修改etc目录下 hadoop-env.sh、mapred-env.sh、yarn-env.sh文件中的JDK路径,将其分别指向/opt/jdk/jdk1.8.0_65/,注意在编辑配置文件时,先把# export前的符号”#“去掉:
[root@node1 ~]# cd /opt/hadoop/hadoop-2.8.3/etc/hadoop/
[root@node1 hadoop]# vi hadoop-env.sh
[root@node1 hadoop]# vi mapred-env.sh

[root@node1 hadoop]# vi yarn-env.sh
配置core-site.xml
在三个节点上分别创建hadoop临时目录/opt/datas/tmp:
[root@node1 ~]# mkdir -p /opt/datas/tmp
[root@node2 ~]# mkdir -p /opt/datas/tmp
[root@node3 ~]# mkdir -p /opt/datas/tmp
在node1节点上修改core-site.xml配置信息:
[root@node1 ~]# vi /opt/hadoop/hadoop-2.8.3/etc/hadoop/core-site.xml
添加如下内容:
<configuration>
<property>
<!-- NameNode主机地址及端口号 -->
<name>fs.defaultFS</name>
<value>hdfs://node1:8020</value>
</property>
<!-- hadoop临时目录的地址 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/data/tmp</value>
</property>
</configuration>
配置hdfs-site.xml
在三个节点分别创建好存放NameNode数据的目录/opt/datas/dfs/namenode,以及存入DataNode数据的目录/opt/datas/dfs/datanode(以node1上的操作为例,node2和node3上的操作相同):
[root@node1 ~]# mkdir -p /opt/datas/dfs/namenode
[root@node1 ~]# mkdir -p /opt/datas/dfs/datanode
编辑hdfs-site.xml文件,配置相关信息:
[root@node1 ~]# vi /opt/hadoop/hadoop-2.8.3/etc/hadoop/hdfs-site.xml
<configuration>
<!-- 指定创建的副本数 -->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- 指定SecondaryNameNode的地址和端口号,将node2作为SecondaryNameNode服务器 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node2:50090</value>
</property>
<!-- NameNode 数据存放路径 -->
<property>
<name>dfs.namenode.name.dir</name>
<value>/opt/datas/dfs/namenode</value>
</property>
<!-- DataNode 数据存放路径 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>/opt/datas/dfs/datanode</value>
</property>
</configuration>
配置slaves
slaves文件用于指定hdfs DataNode 工作节点,编辑slaves文件:
[root@node1 ~]# vi /opt/hadoop/hadoop-2.8.3/etc/hadoop/slaves
将文件内容修改为:

配置yarn-site.xml
编辑yarn-site.xml文件:
[root@node1 ~]# vi /opt/hadoop/hadoop-2.8.3/etc/hadoop/yarn-site.xml
修改文件内容:
<configuration>
<!-- NodeManager上运行的附属服务,需配置成mapreduce_shuffle,才能运行MapReduce程序 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定ResourceManager服务器-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node2</value>
</property>
<!-- 配置是否启用日志聚集功能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 配置聚集的日志在hdfs上最长保存时间 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>106800</value>
</property>
</configuration>
配置mapred-site.xml
以mapred-site.xml.template为模板,复制一个mapred-site.xml文件:
[root@node1 ~]# cp /opt/hadoop/hadoop-2.8.3/etc/hadoop/mapred-site.xml.template /opt/hadoop/hadoop-2.8.3/etc/hadoop/mapred-site.xml
编辑mapred-site.xml文件:
[root@node1 ~]# vi /opt/hadoop/hadoop-2.8.3/etc/hadoop/mapred-site.xml
<configuration>
<!-- 设置mapreduce任务运行在yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- 设置mapreduce历史服务器地址及端口号 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>node1:10020</value>
</property>
<!-- 设置mapreduce历史服务器的web页面地址和端口号 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>node1:19888</value>
</property>
</configuration>
在profile文件中配置hadoop环境信息
编辑环境配置文件/etc/profile:
[root@node1 ~]# vi /etc/profile
#Hadoop Start
export HADOOP_HOME=/opt/hadoop/hadoop-2.8.3
export PATH=$PATH:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin
#Hadoop End
让环境配置信息生效:
[root@node1 ~]# source /etc/profile
分发内容至节点
在node2,node3节点上创建目录/opt/jdk,/opt/hadoop:
[root@node2 ~]# mkdir -p /opt/jdk
[root@node2 ~]# mkdir -p /opt/hadoop
分发jdk至node2,node3:
[root@node1 ~]# scp -r /opt/jdk/jdk1.8.0_65/ node2:/opt/jdk
[root@node1 ~]# scp -r /opt/jdk/jdk1.8.0_65/ node3:/opt/jdk
分发hadoop至node2,node3:
[root@node1 ~]# scp -r /opt/hadoop/hadoop-2.8.3/ node2:/opt/hadoop
[root@node1 ~]# scp -r /opt/hadoop/hadoop-2.8.3/ node3:/opt/hadoop
分发profile至node2,node3:
[root@node1 ~]# scp /etc/profile node2:/etc/profile
[root@node1 ~]# scp /etc/profile node3:/etc/profile
在node2,node3节点上执行命令使配置生效:
node2:
[root@node2 ~]# source /etc/profile
node3:
[root@node3 ~]# source /etc/profile
格式化NameNode
如果需要重新格式化NameNode,需要先将原来NameNode和DataNode下的文件全部删,不然会报错,因为每次格式化,默认是创建一个集群ID,并写入NameNode和DataNode的VERSION文件中(VERSION文件所在目录为dfs/namenode/current 和 dfs/datanode/current),重新格式化时,默认会生成一个新的集群ID,如果不删除原来的目录,会导致NameNode中的VERSION文件中是新的集群ID,而DataNode中是旧的集群ID,从而不一致,导致报错,另一种方法是格式化时指定集群ID参数,指定为旧的集群ID。
NameNode和DataNode所在目录是在hdfs-site.xml中dfs.namenode.name.dir、dfs.datanode.data.dir所配置。
[root@node1 ~]# cd /opt/hadoop/hadoop-2.8.3/bin/
[root@node1 bin]# ./hdfs namenode -format
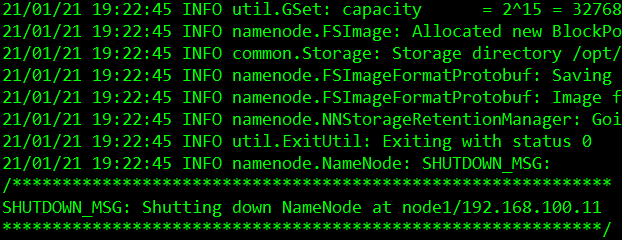
启动集群
启动HDFS
[root@node1 ~]# cd /opt/hadoop/hadoop-2.8.3/sbin/
[root@node1 sbin]# ./start-dfs.sh
Starting namenodes on [node1]
node1: starting namenode, logging to /opt/hadoop/hadoop-2.8.3/logs/hadoop-root-namenode-node1.out
node3: starting datanode, logging to /opt/hadoop/hadoop-2.8.3/logs/hadoop-root-datanode-node3.out
node2: starting datanode, logging to /opt/hadoop/hadoop-2.8.3/logs/hadoop-root-datanode-node2.out
node1: starting datanode, logging to /opt/hadoop/hadoop-2.8.3/logs/hadoop-root-datanode-node1.out
Starting secondary namenodes [node2]
node2: starting secondarynamenode, logging to /opt/hadoop/hadoop-2.8.3/logs/hadoop-root-secondarynamenode-node2.out
[root@node1 sbin]#
jps 命令查看进程启动情况,能看到node1节点启动了 NameNode 和 DataNode进程。
[root@node1 sbin]# jps
1588 NameNode
1717 DataNode
1930 Jps
启动YARN
在node2节点上执行命令:
[root@node2 ~]# cd /opt/hadoop/hadoop-2.8.3/sbin/
[root@node2 sbin]# ./start-yarn.sh
starting yarn daemons
starting resourcemanager, logging to /opt/hadoop/hadoop-2.8.3/logs/yarn-root-resourcemanager-node2.out
node3: starting nodemanager, logging to /opt/hadoop/hadoop-2.8.3/logs/yarn-root-nodemanager-node3.out
node1: starting nodemanager, logging to /opt/hadoop/hadoop-2.8.3/logs/yarn-root-nodemanager-node1.out
node2: starting nodemanager, logging to /opt/hadoop/hadoop-2.8.3/logs/yarn-root-nodemanager-node2.out
[root@node2 sbin]#
jps 命令查看进程启动情况,能看到node2节点启动了ResourceManager进程:
[root@node2 sbin]# jps
2629 NodeManager
2937 Jps
1434 DataNode
1531 SecondaryNameNode
2525 ResourceManager
[root@node2 sbin]#
注意,如果不在ResourceManager主机上运行 $HADOOP_HOME/sbin/start-yarn.sh 命令的话,ResourceManager 进程将不会启动,需要到 ResourceManager 主机上执行./yarn-daemon.sh start resourcemanager 命令来启动ResourceManager进程。
启动日志服务器
在node1节点上启动MapReduce日志服务:
[root@node1 sbin]# ./mr-jobhistory-daemon.sh start historyserver
starting historyserver, logging to /opt/hadoop/hadoop-2.8.3/logs/mapred-root-historyserver-node1.out
[root@node1 sbin]#
jps 命令查看进程启动情况,能看到node1节点启动了JobHistoryServer进程:
[root@node1 sbin]# jps
1588 NameNode
1717 DataNode
2502 Jps
2462 JobHistoryServer
2303 NodeManager
[root@node1 sbin]#
查看HDFS Web页面
地址为 NameNode 进程运行主机ip,端口为50070(网址:http://192.168.100.11:50070):
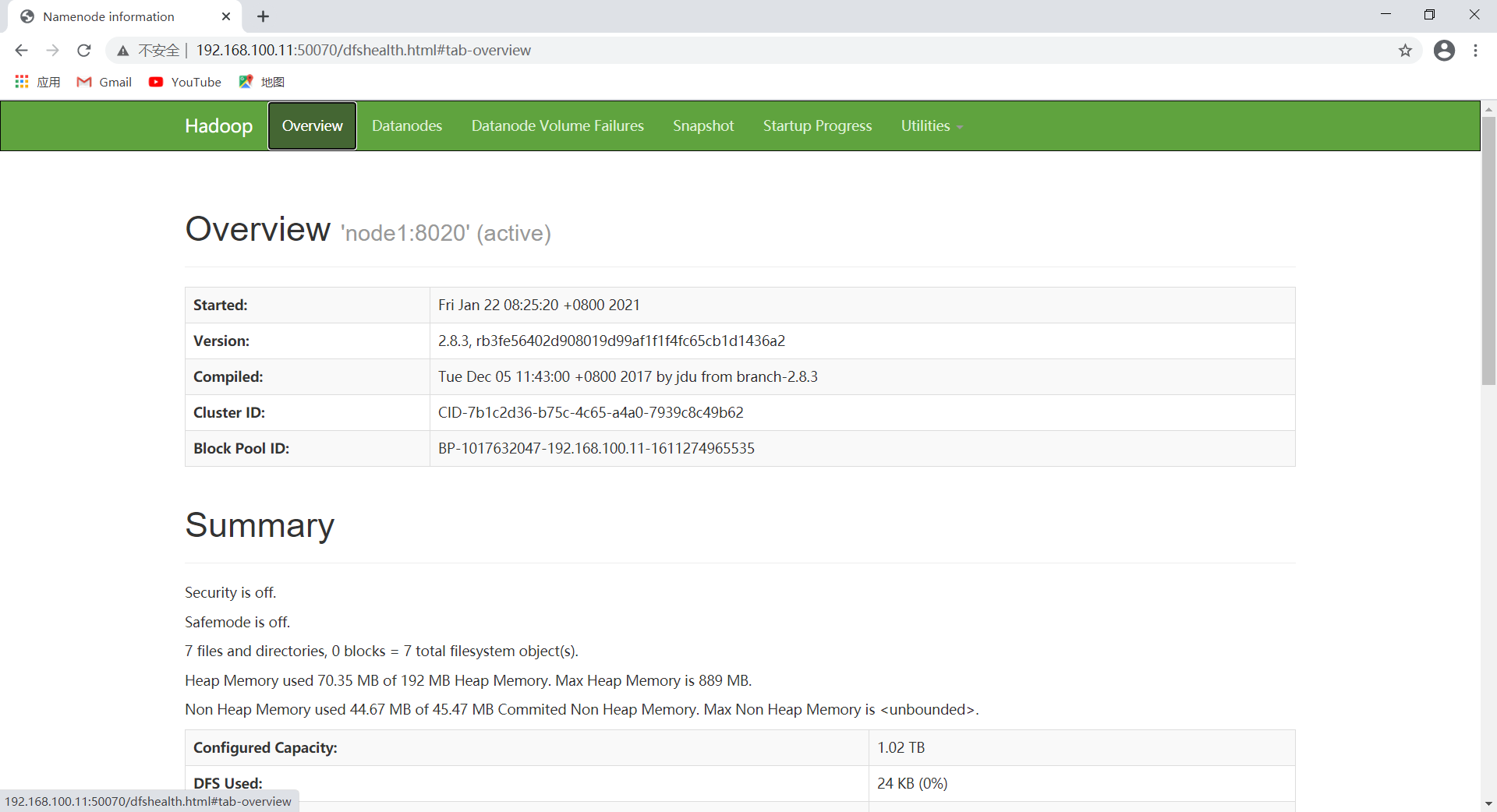
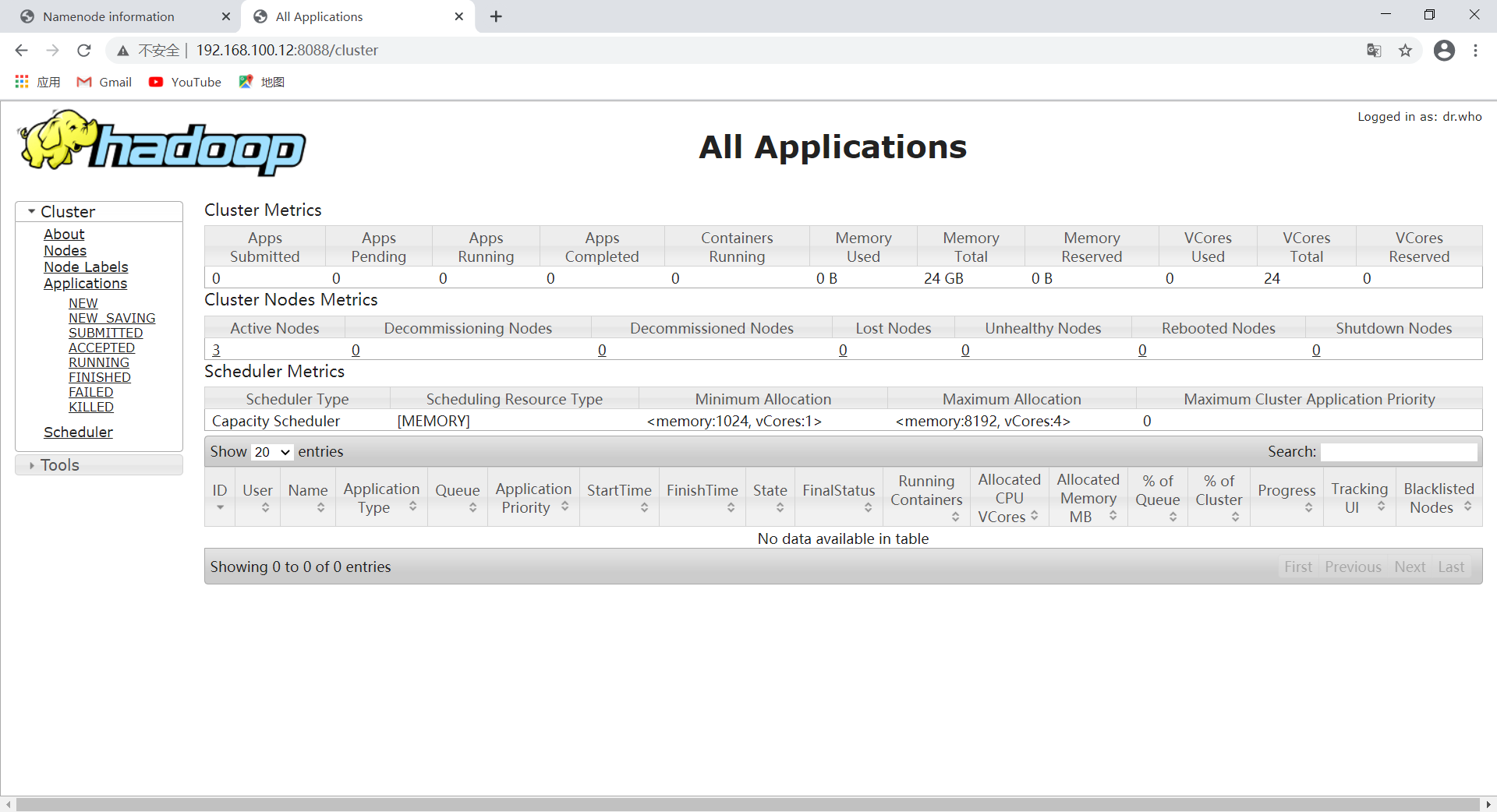
查看YARN Web页面
地址为node2主机ip,端口号为:8088(网址:http://192.168.100.12:8088)
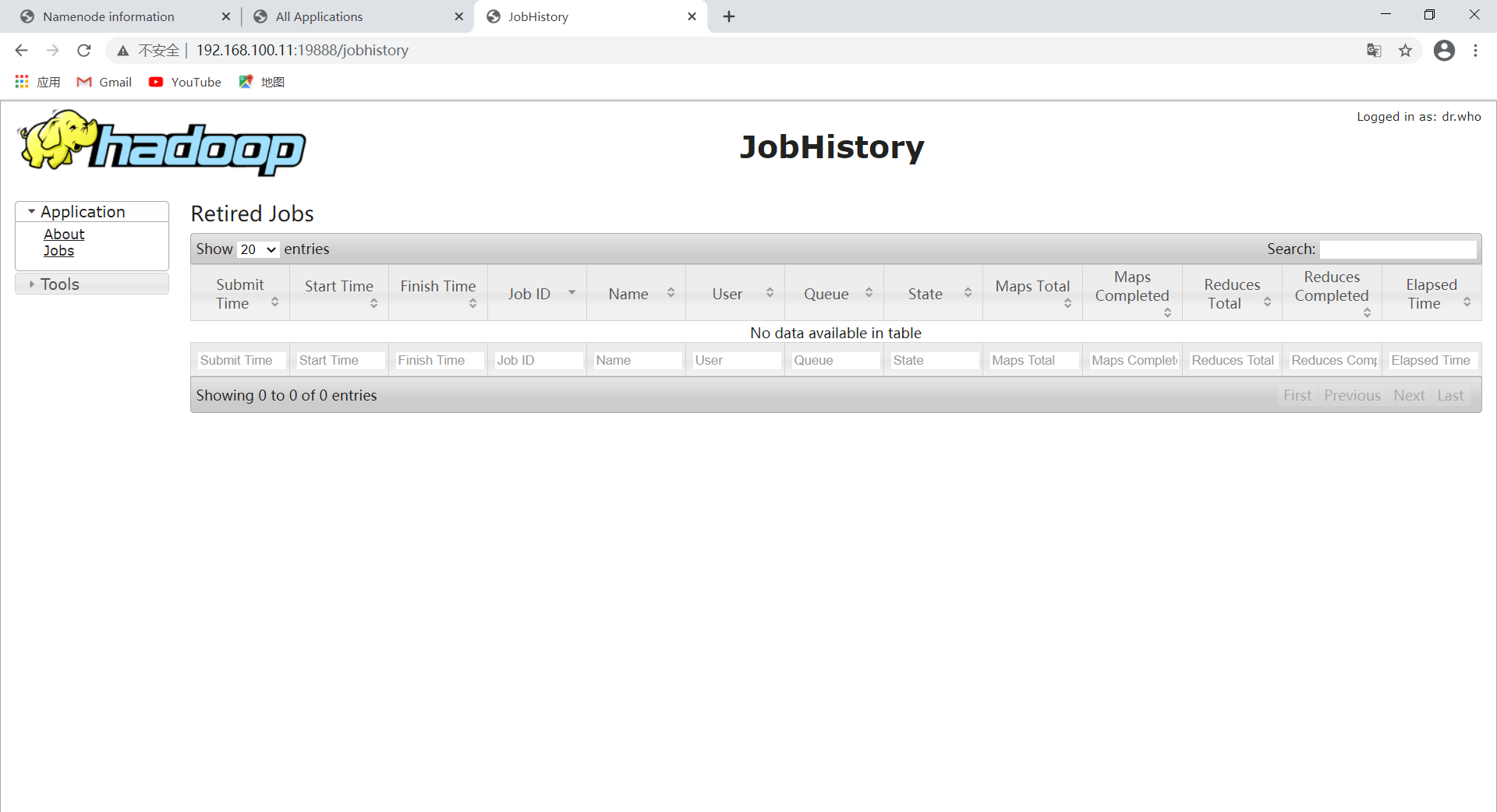
查看JobHistory Web 页面
地址为node1主机ip,端口号为:19888(网址:http://192.168.100.11:19888/jobhistory)
测试案例(使用分词工具统计样本词频)
在node1节点上准备样本文件
[root@node1 ~]# vi example.txt
在example.txt文件中添加如下内容:
hadoop mapreduce hive
hbase spark storm
sqoop hadoop hive
spark hadoop
在hdfs中创建输入目录/datas/input
[root@node1 ~]# hadoop fs -mkdir -p /datas/input
将样本文件example.txt上传至hdfs目录中
[root@node1 ~]# hadoop fs -put ~/example.txt /datas/input
运行hadoop自带的mapreduce Demo程序
[root@node1 ~]# hadoop jar /opt/hadoop/hadoop-2.8.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.8.3.jar wordcount /datas/input/example.txt /datas/output
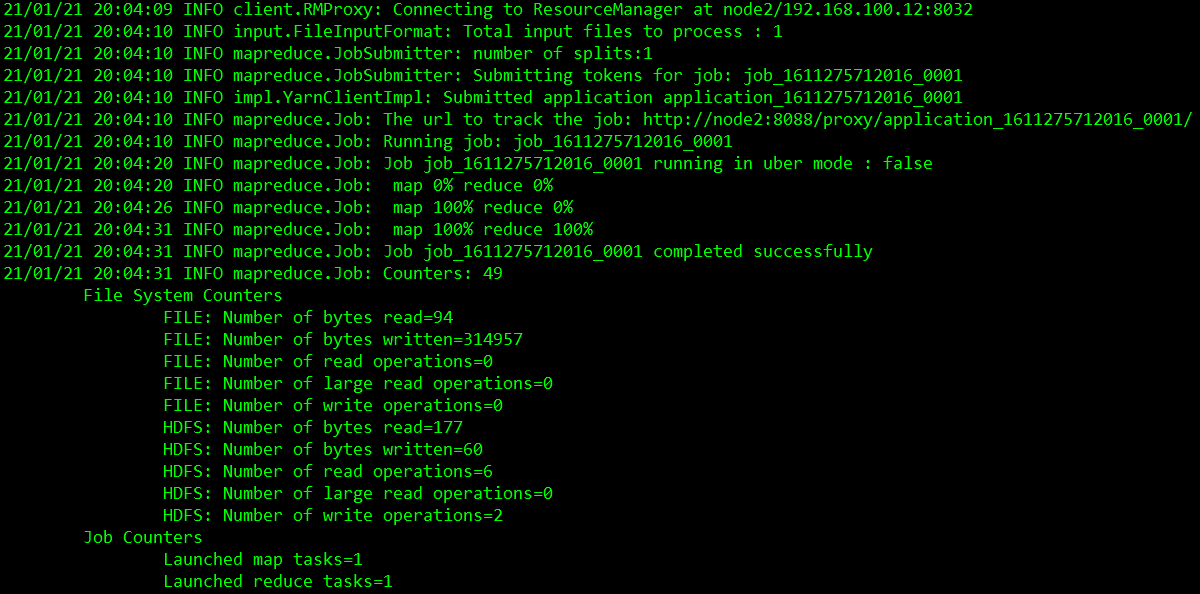
查看输出文件
[root@node1 ~]# hadoop fs -cat /datas/output/part-r-00000
hadoop 3
hbase 1
hive 2
mapreduce 1
spark 2
sqoop 1
storm 1
[root@node1 ~]#