1.���
������һƪ�н����������Ҫͬʱ���Ͷ���������ô����������ÿ������ijЩ��������ı��ء�����õ���jMeter����������ʵ�ʲ��Գ����У�����������������������¼���������Ӧ��token��Ϊ�´�����IJ������������ν�IJ���������
����������֮����������ϵ������һ��������������һ�����ص����ݣ���ʱ�����Ҫ�õ�����������Jmeter����ͨ�������ô��������еġ��������ʽ��ȡ����������������
����������Jmeter�����зdz���Ҫ��һ����������Ϊ�ڲ��Թ��̹���Щ�����Ǿ��������仯�ģ�Ҫ��ȡ��ʹ����Щ���ݣ���Ҫʹ�ù�����
���磺 �û���¼��session��Ϣ����ͬ����Щ����Ҫʹ��session������Ҫ�������̬����Ϣ���������� ���о��������ij������ڶ��������ύ�IJ���Ҫ�ӵ�һ������ķ��������л�ȡ��
2.ʲô��������
����ʲô�ǹ�����ͨ����������������֮��ͨ�����ݲ���������ϵ��һ�㣬������Ҫ��һ���������Ӧ��������Ϊ��һ���������Ρ������¼��IJ�������һ��ʵ�ֵ�¼����Ȼ�����ص�token��ȡ�������浽һ�������У�����������Ϊ���ʹ�á�
3.jmeter�ļ��ֲ���������ʽ
3.1�������ʽ��ȡ��
1����Ĭ�ϵIJ��Լƻ�������һ���߳��飬Ȼ������ȡ�������Ҽ����Ӻ��ô��������������ʽ��ȡ�����������ʽ��ȡ���������£�
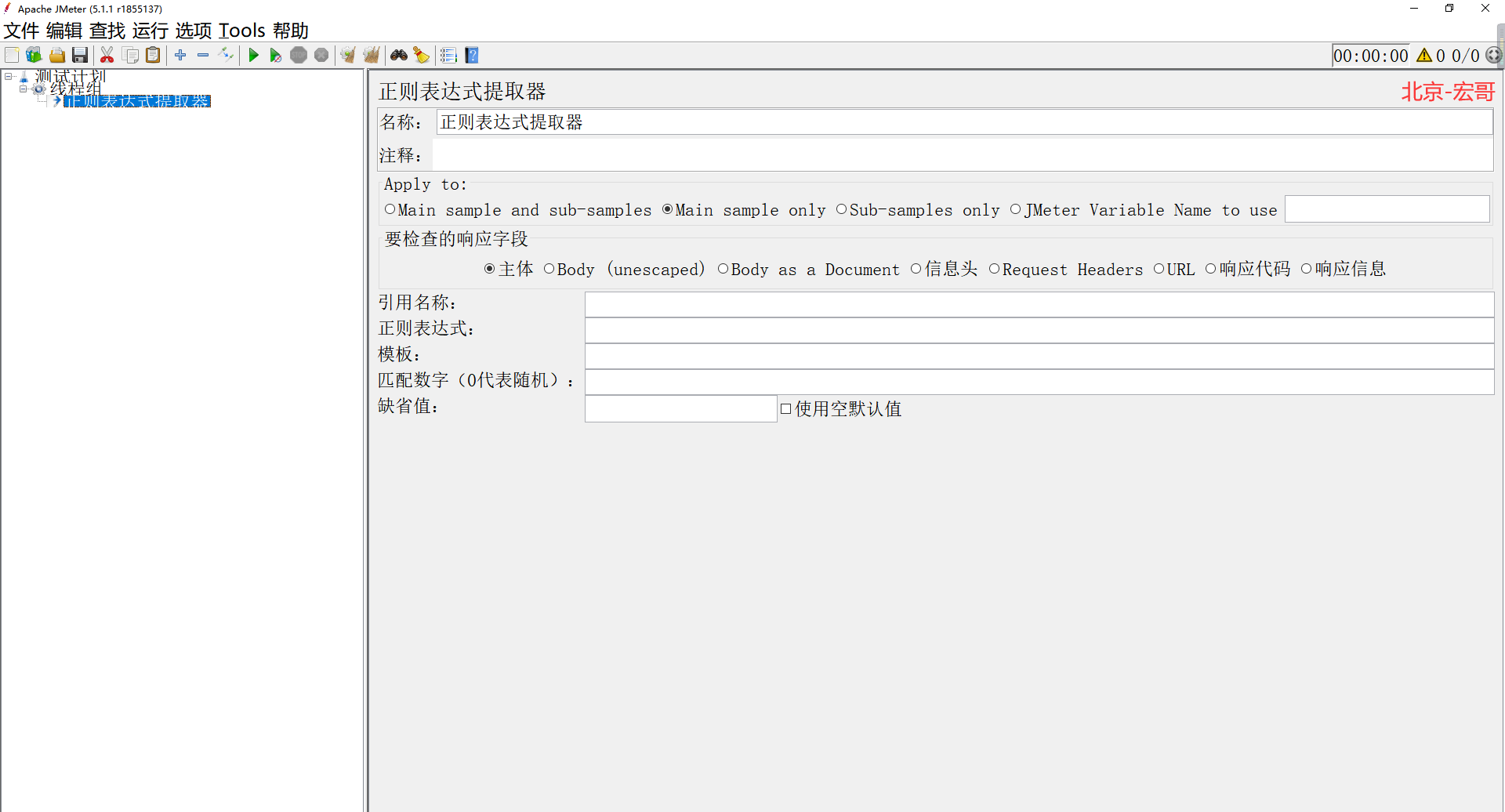
�ؼ�����˵����
�������ô�������������������߷�����Ӧ���ʱ��������
�������ʽ��ȡ���������û��ӷ���������Ӧ��ͨ��ʹ��perl���������ʽ��ȡֵ����Ԫ�ػ�������ָ����Χȡ���������������ʽ��ȡ����ֵ������ģ���ַ�������������洢�������ı������С�
APPly to:���÷�Χ���������ݵĶ��Է�Χ��
��������Main sample and sub-samples:�����ڸ��ڵ��ȡ��������Ӧ�ӽڵ��ȡ����
��������Main sample only���������ڸ��ڵ��ȡ����
��������Sub-samples only:���������ӽڵ��ȡ����
��������JMeter Variable:������jmeter����(������ڿ�����jmeter�ı�������)
Ҫ������Ӧ�ֶΣ���Ҫ������Ӧ���ĵķ�Χ
�����������壺��Ӧ���ĵ�����
��������Body(unescaped):���壬��Ӧ�������������滻�����е�htmlת�����ע��htmlת�������ʱ�����������ģ���˿����в���ȷ��ת������̫����ʹ��
��������Body as a Document���Ӳ�ͬ���͵��ļ�����ȡ�ı���ע�����ѡ��Ƚ�Ӱ������
��������Response Headers����Ӧ��Ϣͷ
��������Request Headers:������Ϣͷ
��������URL��ͳһ��Դ��λ������Internet������������Ϣ��Դ���ַ���
����������Ӧ����:��Ӧ״̬�룬����200��404��
����������Ӧ��Ϣ:��Ӧ��Ϣ
�������ƣ�Reference Name����Jmeter���������ƣ��洢��ȡ�Ľ�������¸�������Ҫ���õ�ֵ���ֶΡ�������������������ȡ����SOCIAL_NO��
�������ʽ��Regular Expression����ʹ���������ʽ������Ӧ���������������ʾ��ȡ�ַ����еIJ���ֵ���벻Ҫʹ�á�||���������㱾����Ҫƥ������ַ���
���õ��������ʽ��������
|
������
|
˵��
|
ʵ��
|
|
.
|
��ʾ�κε����ַ�
|
|
|
[ ]
|
�ַ������Ե����ַ�������Χ
|
[abc]��ʾa��b��c,[a-z]��ʾa-z�ĵ����ַ�
|
|
[^ ]
|
���ַ������Ե����ַ������ų���Χ
|
[^abc]��ʾ��a��b��c�ĵ����ַ�
|
|
*
|
ǰһ���ַ���λ�������չ
|
abc* ��ʾab��abc��abcc��abccc��
|
|
+
|
ǰһ���ַ�1�λ�������չ
|
abc+ ��ʾ abc��abcc��abccc��
|
|
��
|
ǰһ���ַ�0�λ�1����չ
|
abc? ��ʾ ab��abc
|
|
|
|
���ұ���ʽ������һ��
|
abc|def ��ʾ abc��def
|
|
{m}
|
��չǰһ���ַ�m��
|
ab{2}c ��ʾ abbc
|
|
{m,n}
|
��չǰһ���ַ�m��n��
|
ab{1,2}c ��ʾ abc��abbc
|
|
^
|
ƥ���ַ�����ͷ
|
^abc ��ʾ abc����һ���ַ����Ŀ�ͷ
|
|
$
|
ƥ���ַ�����β
|
abc$ ��ʾ abc����һ���ַ�����β
|
|
( )
|
�������ڲ�ֻ��ʹ��|������
|
(abc)��ʾabc,(abc|def)��ʾabc��def
|
|
\d
|
���֣��ȼ���0-9
|
|
|
\w
|
�����ַ����ȼ���[a-z0-9A-Z_]
|
|
ģ�壺�������������ʽ������õ���ʽ����ʵ�����һ�飬������һ����$0$������һ������ȫ����$1$������һ�����ĵ�1�����Դ����ƣ�$1$$2$�������������ʽһ�����еĵ�1���͵�2�������������һ���м�û�м����$3$,$4$�������������ʽһ�����еĵ�3���͵�4�������������һ������������
ƥ�����֣�0�����������ʽ������������1����ȫ����
ȱʡֵ�������ò���ʱ��ʾ���ݵ���Ϣ��ͨ��дһ��ERROR��
����������˵����������ã�Ȼ�����������һ�����������鿴�������������Ƿ�ȡ���˶�Ӧ��ֵ����ȡ���IJ���������ʱ��${sessionid_1}��${sessionid_2}...�������Ҫ�õ�ƥ����IJ����ĸ�����${sessionid_matchNr}��
3.2ʵ������
������������ر���䣬�Ǻ����������ӿ���ʵ��һ�¡������������ӿڣ�ͨ���������ʽ��ȡ��������һ���ӿڵij��д��룬��Ϊ�ڶ�������IJ������롣
��ȡ���д���ӿ�;
����http://toy1.weather.com.cn/search?cityname=beijing
���ݳ��д����ȡ�����ӿڣ�
����http://www.weather.com.cn/data/cityinfo/101010100.html
��������
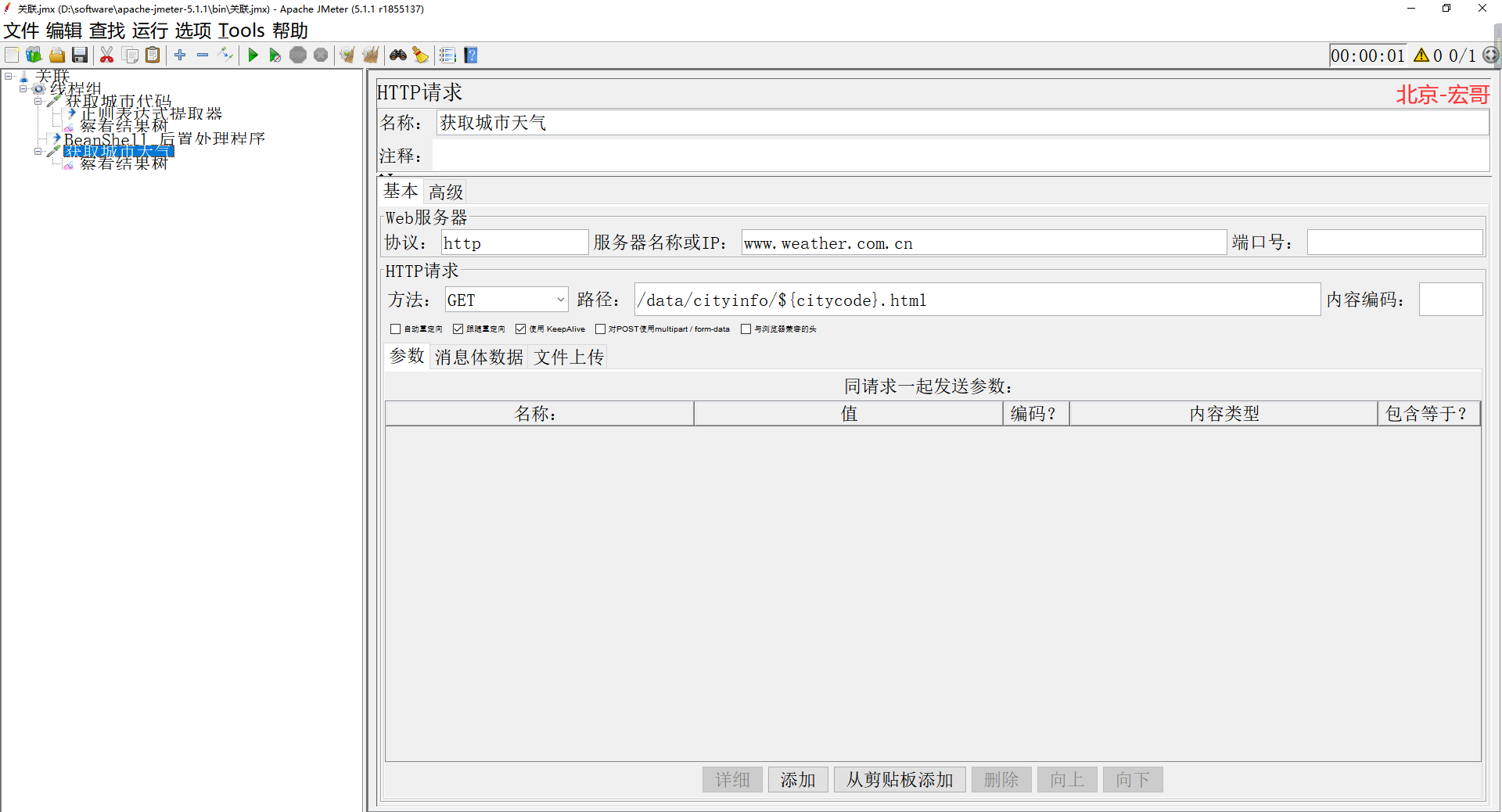
1.����http����ȡ�����ij��д��룬���Ӳ쿴�����������ͼ��ʾ��

2.���к�����Ӧ�����и���Ŀ�������ǰ����ַ���������֤���Ƶ��ַ�������Ψһ�ԡ� ����ͼ��ʾ��
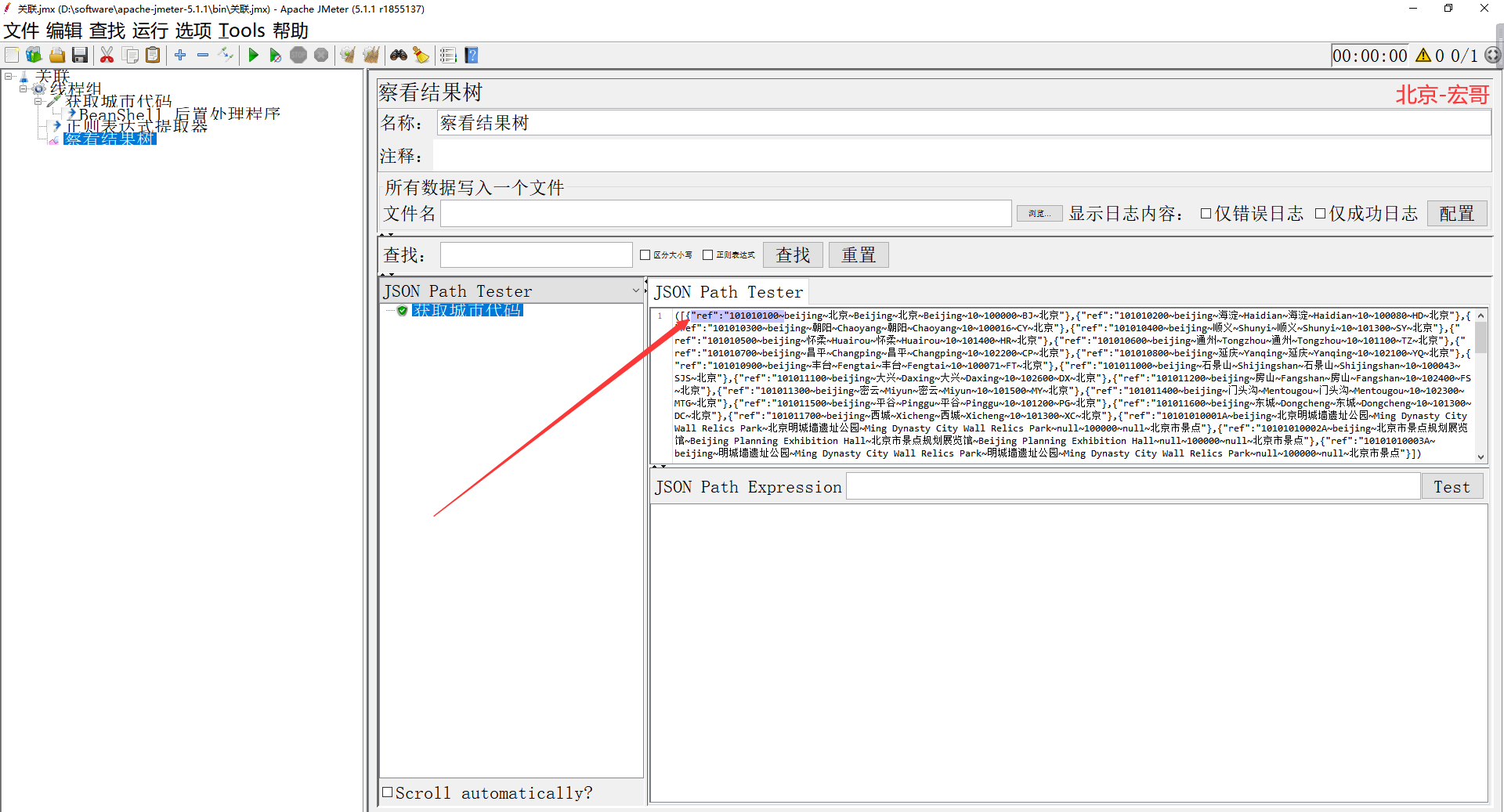
3.�����������ʽ��ȡ������д��ȡ����ز�����(�������ʽ�� "ref":"(.*?)~ )������ͼ��ʾ��
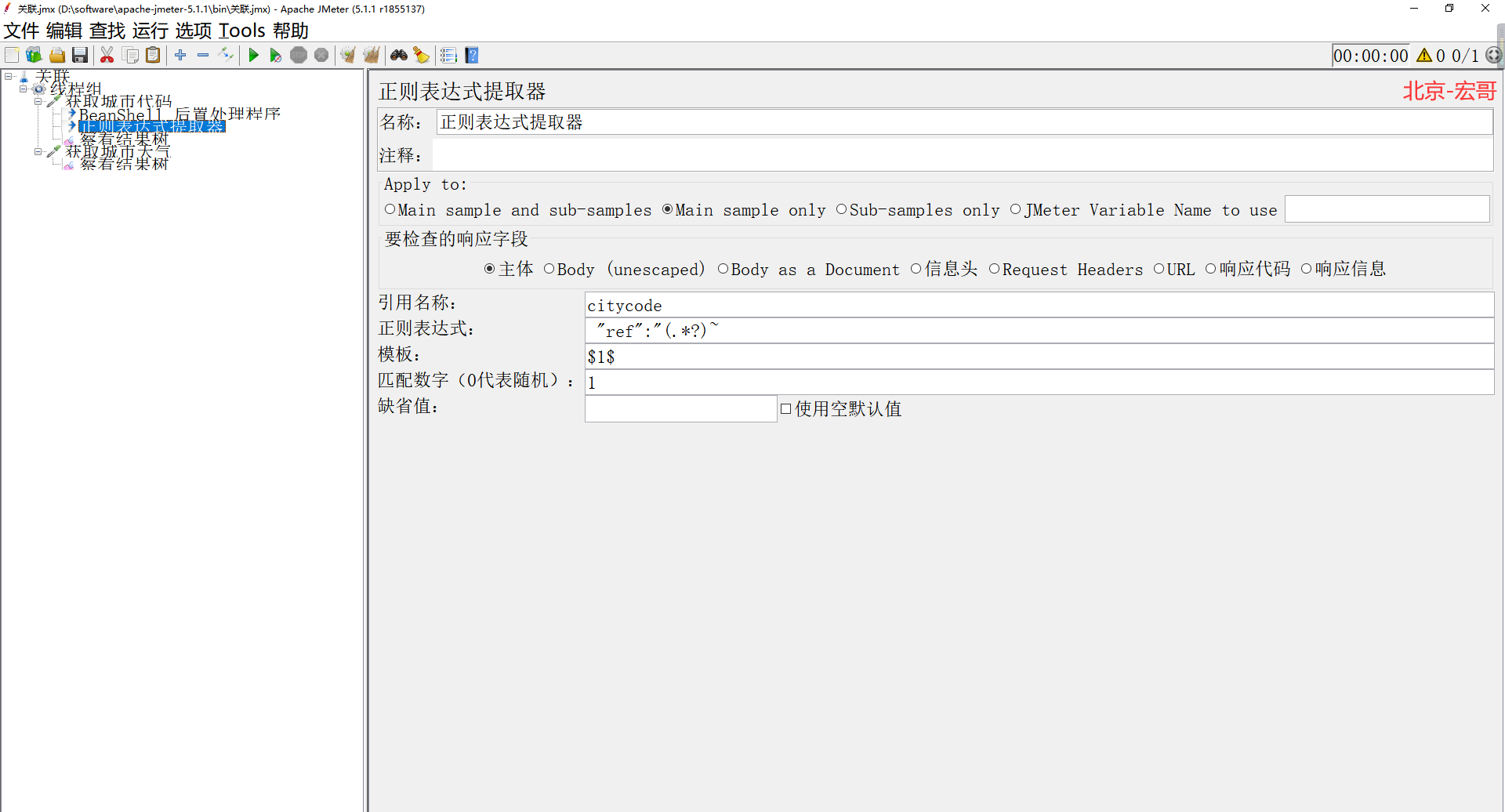
4.���ӻ�ȡ���������������Ӳ쿴�������ʹ��${citycode}�滻101010100��ʹ��${xx}��������������ȡ�IJ���������ͼ��ʾ��
5.���棬���к쿴���������Ӧ�������ͼ��ʾ��
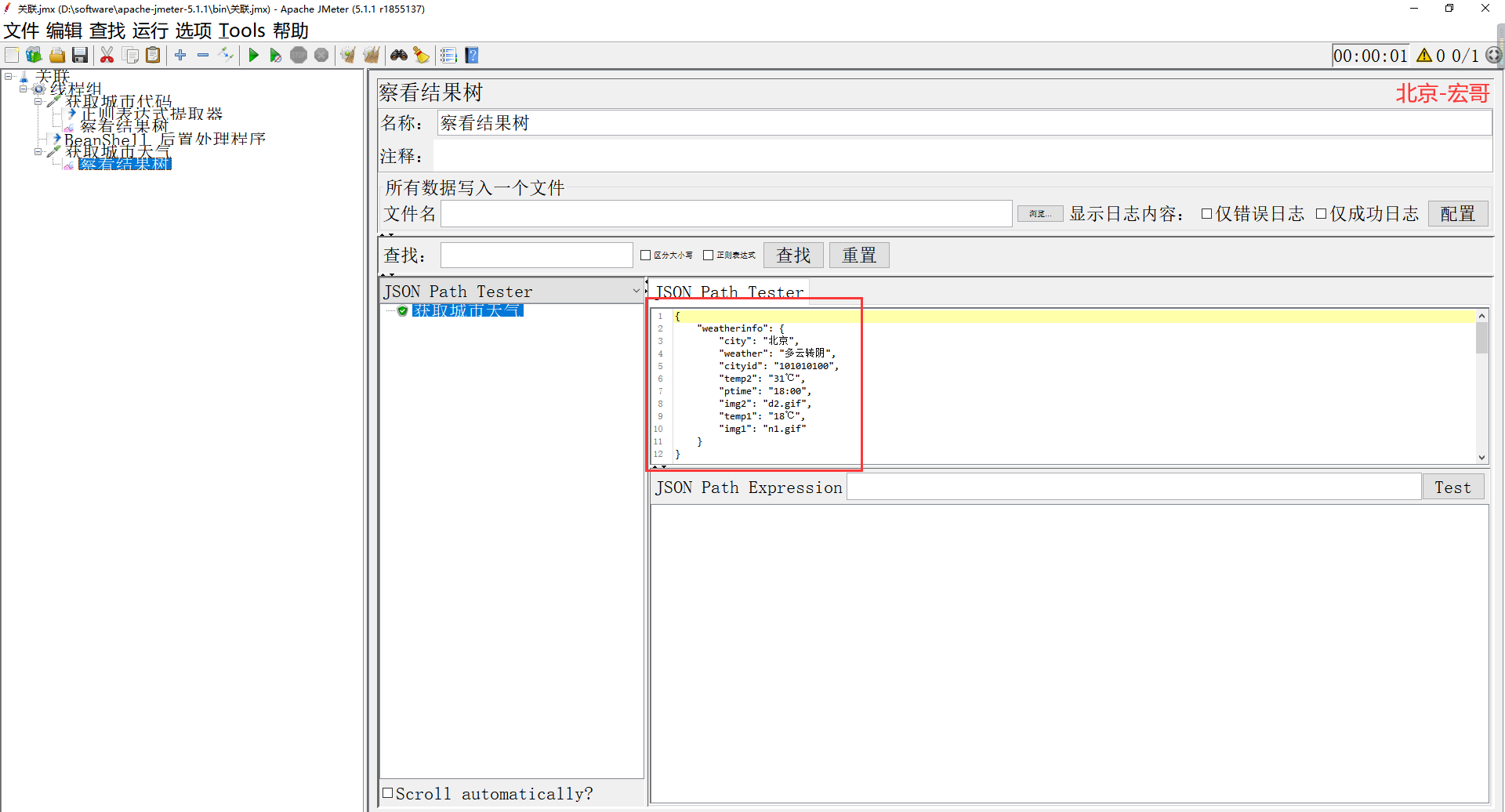
3.2json path postprocessor��JSON Extractor��
�����ô�����ǰ�ӿ���Ӧ���ص�json����ȡ���ݣ���Ϊ���������ڲ�ͬ�������д��ݡ����£��ӵ�½�ӿڷ��ص�json����ȡuser id������������Ϊid�������������п���ֱ�ӵ������������������Ϊpost�������β������restful�ӿڷdz����á�
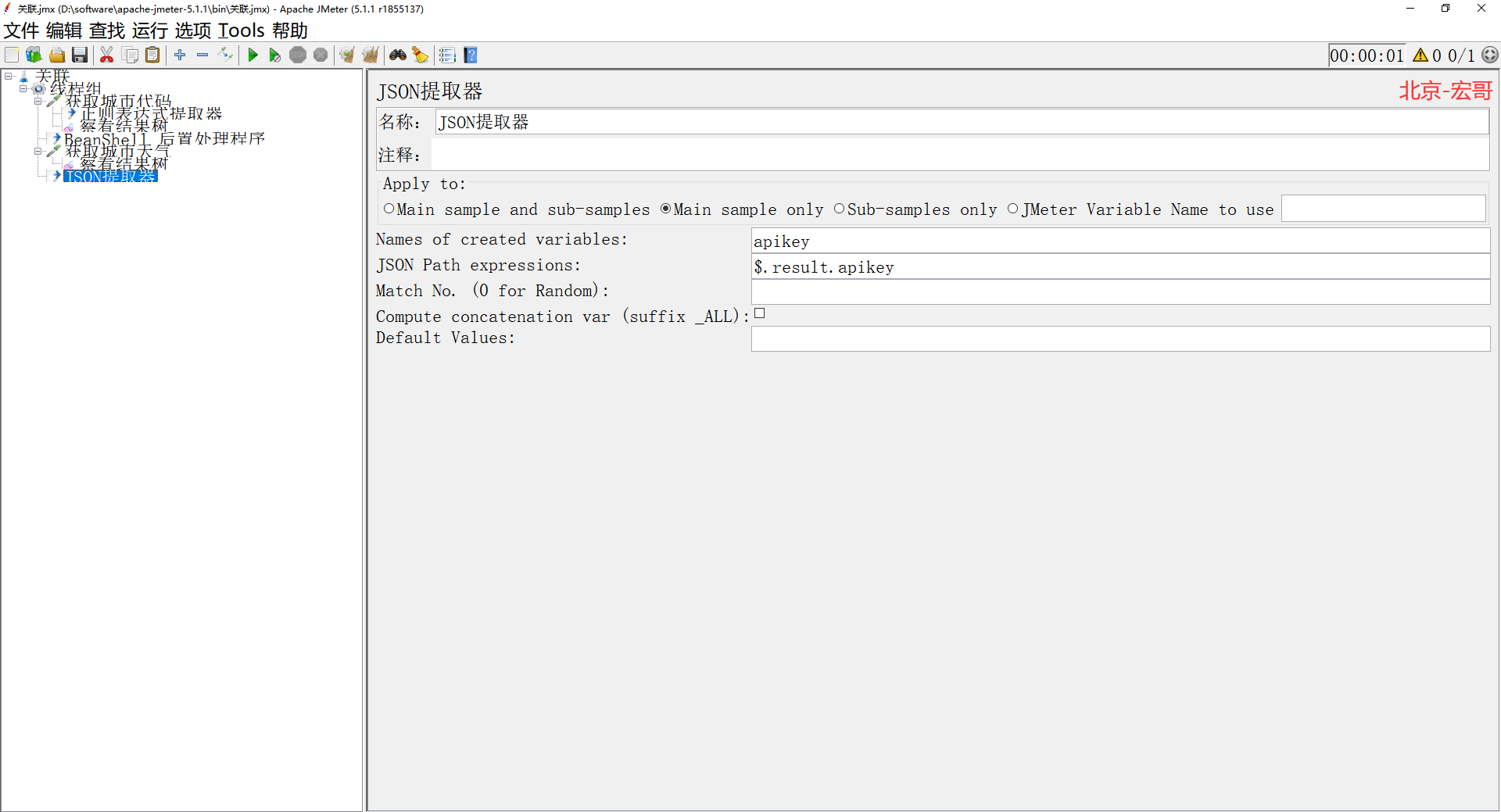
�ؼ�����˵����
Variable names : ����
JSONPath Expression��JSON����ʽ
Match Numbers��ƥ���ĸ�����Ϊ�ռ�Ĭ�ϵ�һ��
Default Value��δȡ��ֵ��ʱ��Ĭ��ֵ
���緵��ֵ���£�
{
"code": 200,
"message": "�ɹ�!",
"result": {
"apikey": "b9b3a96f7554e3bead2eccf16506c13e"
}
}
��json����ʽΪ��$.result.apikey
�������ֵ�����飬����Ҫ���������λ�ã���
{
"code": 200,
"message": "�ɹ�!",
"result": [{
"apikey": "b9b3a96f7554e3bead2eccf16506c13e"
}]
}
��json����ʽΪ��$.result[0].apikey����ȡ��һ��ֵ��
3.3XPath Extractor
jmeter�ṩ�ĶԹ�����֧�ְ�������2�����棺
���ܹ�������ҳ���ϵ�ָ�����ݱ����ڲ����У������������ʽ��ȡ����JSON Extractor��
���ܹ���GET��POST�����е�����ʹ�øò������滻��(XPath Extractor)
XPath Extractor��ʹ�÷������������ʽ��ȡ��(Regular Expression Extractor)���ƣ�ֻ������Expression��ָ���IJ����������ʽ�����Ǹ�����XPath·����
���ô�����(Post Processor)��������һ�ֶ�sampler�����������ܵ�����Ӧ���ݽ��д������������ķ��������뽫���ô�����Ԫ�����ں��ʵ�λ�ò��ܴﵽԤ�ڵ�Ч����
�½�һ���߳��飬Ȼ���Ҽ�-����-���ô�����-XPath Extractor��

�ؼ�����˵����
APPly to:���÷�Χ���������ݵĶ��Է�Χ��
Main sample and sub-samples:�����ڸ��ڵ��ȡ��������Ӧ�ӽڵ��ȡ����
Main sample only���������ڸ��ڵ��ȡ����
Sub-samples only:���������ӽڵ��ȡ����
JMeter Variable:������jmeter����(������ڿ�����jmeter�ı�������)
XML Parsing Options��Ҫ������XML����
Use Tidy������Ҫ������ҳ����HTML��ʽʱ������ѡ�и�ѡ������XML��XHTML��ʽ������RSS���أ�����ȡ��ѡ�У�
Quiet��ʾֻ��ʾ��Ҫ��HTMLҳ�棬Report errors��ʾ��ʾ��Ӧ������Show warnings��ʾ��ʾ���棻
Use Namespaces��������ø�ѡ�������XML��������ʹ�������ռ����ֱ棻
Validate XML������ҳ��Ԫ��ģʽ���м�������
Ignore Whitespace�����Կհ����ݣ�
Fetch external DTDs�����ѡ�и���ⲿ��ʹ��DTD��������ȡҳ�����ݣ�
Return entire XPath fragment of text content�������ı����ݵ�����XPathƬ�Σ�
Reference Name�������ȡ����ֵ�IJ�����
XPath Query��������ȡֵ��XPath����ʽ��
Default Value��������Ĭ��ֵ��
3.4�߽���ȡ��
��Boundary Extractor��ȡ������4.0�汾���Ƶ�һ��С���ܣ���������Ϊ�������������ã���LoadRunner��������߽��ұ߽����ơ�
���磺����Ҫע��ʱ��һ��ֵ��ÿ�ζ��DZ仯�ģ�
<input type="hidden" name="formhash" value="0ab4d9ec" />

�������֪��������߽���ұ߽�����ô����name="formhash" value="11cc937d"��
4.��
�����������ʽ��ȡ����XPath Extractor������������ȡ����ҳ���е��ض��ı��������䱣���ڲ����У������ַ�ʽ������ȱ�㡣�������ʽ��ȡ���������ڶ�ҳ���κ��ı�����ȡ����ȡ�������Ǹ����������ʽ��ҳ�������н����ı�ƥ��;��XPath Extractor�������ȡ����ҳ������Ԫ�ص��������ԡ���Ƚ϶��ԣ������Ҫ��ȡ���ı���ҳ����ijԪ�ص�����ֵ������ʹ��XPath Extractor;�������Ҫ��ȡ���ı���ҳ���ϵ�λ�ò��̶������߲���Ԫ�ص����ԣ�����ʹ���������ʽ��ȡ����
�������ʽ��ȡ����XPath Extractor������
���������ʽ��ȡ���������ڶ�ҳ���κ��ı�����ȡ����ȡ�������Ǹ����������ʽ��ҳ�������н����ı�ƥ�䣻
��XPath Extractor�������ȡ����ҳ������Ԫ�ص��������ԣ�
�������Ҫ��ȡ���ı���ҳ����ijԪ�ص�����ֵ������ʹ��XPath Extractor;
�������Ҫ��ȡ���ı���ҳ���ϵ�λ�ò��̶������߲���Ԫ�ص����ԣ�����ʹ���������ʽ��ȡ����
������ʵ��������ÿ�����ϰ���Լ�ʹ�õ������̶ȣ�ֻҪ���ܹ���������һ������Ĺ�����������һ������ķ��ؽ������ȡ�������ǿ���ʹ�õġ��������ֻ�������о��˼��ֳ��õķ�����
��������ʱ�䲻���ˣ�����ͽ���ͷ����������ˣ������ԥ����Ҫ��Ҫ�ؼҹ����ڣ���������һ���Ѿ���