通常情况下,我们都是使用一套kafka集群处理业务。但有些情况需要使用另一套kafka集群来进行数据同步和备份,比如需要更高的 SLA~
mirror maker2背景
通常情况下,我们都是使用一套kafka集群处理业务。但有些情况需要使用另一套kafka集群来进行数据同步和备份。在kafka早先版本的时候,kafka针对这种场景就有推出一个叫mirror maker的工具(mirror maker1,以下mm1即代表mirror maker1),用来同步两个kafka集群的数据。
最开始版本的mirror maker本质上就是一个消费者 + 生产者的程序。但它有诸多诸多不足,包括
- 目标集群的Topic使用默认配置创建,但通常需要手动repartition。
- acl和配置修改的时候不会自动同步,给多集群管理带来一些困难
- 消息会被
DefaultPartitioner打散到不同分区,即对一个topic ,目标集群的partition与源集群的partition不一致。
- 任何配置修改,都会使得集群变得不稳定。比如比较常见的增加topic到whitelist。
- 无法让源集群的producer或consumer直接使用目标集群的topic。
- 不保证exactly-once,可能出现重复数据到情况
- mm1支持的数据备份模式较简单,比如无法支持active <-> active互备
- rebalance会导致延迟
因为存在这些问题,mirror maker难以在生产环境中使用。所以kafka2.4版本,推出一个新的mirror maker2(以下mm2即代表mirror maker2)。mirror maker2基于kafka connect工具,解决了上面说的大部分问题。
今天主要介绍mirror maker2的设计,主要功能和部署。
设计和功能
整体设计
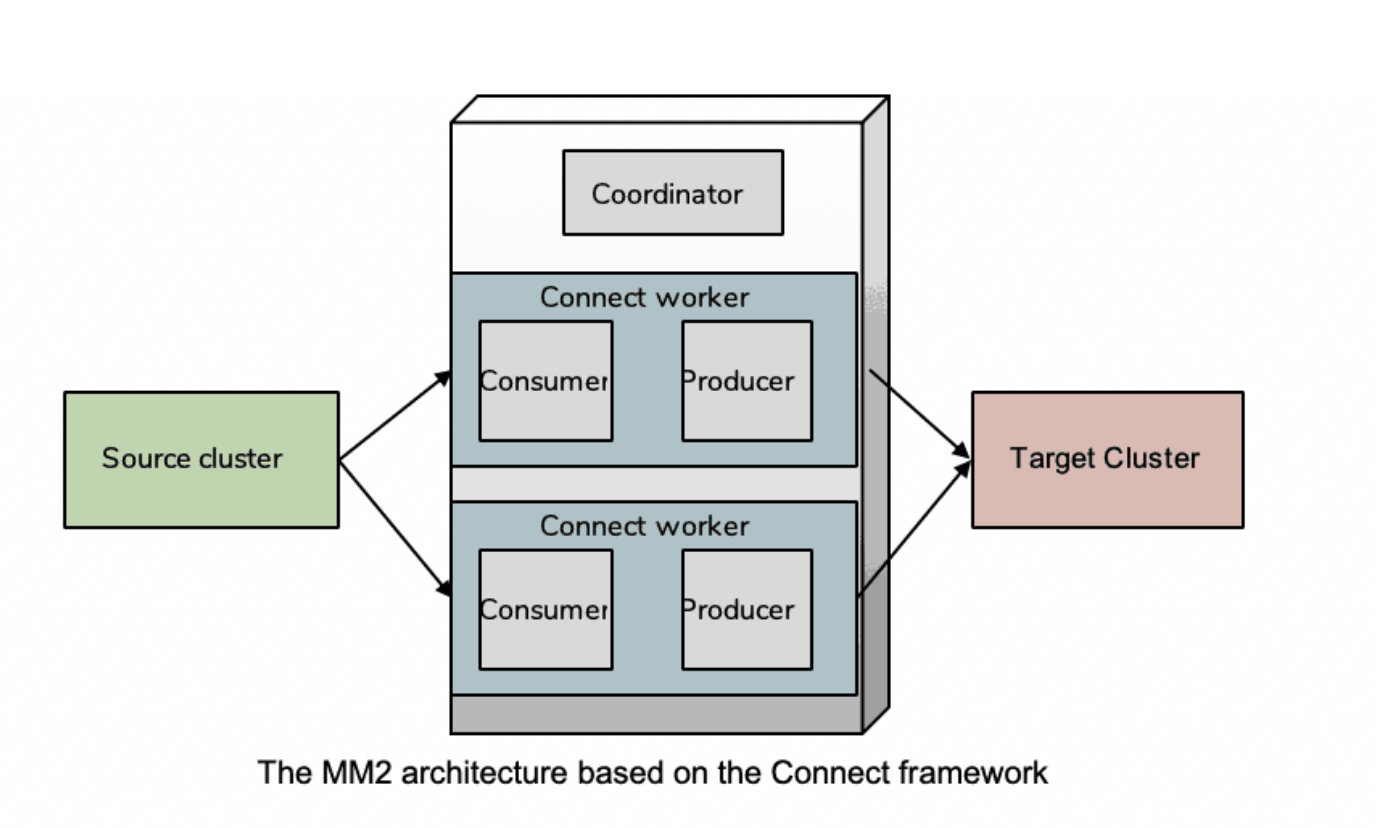
mirror maker2是基于kafka connect框架进行开发的,可以简单地将mirror maker2视作几个source connector和sink connector的组合。包括:
- MirrorSourceConnector, MirrorSourceTask:用来进行同步数据的connector
- MirrorCheckpointConnector, MirrorCheckpointTask:用来同步辅助信息的connector,这里的辅助信息主要是consumer的offset
- MirrorHeartbeatConnector, MirrorHeartbeatTask:维持心跳的connector
不过虽然mirror maker2岁基于kafka connect框架,但它却做了一定的改造,可以单独部署一个mirror maker2集群,当然也可以部署在kafka connect单机或kafka connect集群环境上。这部分后面介绍部署的时候再介绍。
和mm1一样,在最简单的主从备份场景中,mm2建议部署在目标(target)集群,即从远端消费然后本地写入。如果部署在源集群端,那么出错的时候可能会出现丢数据的情况。
其整体架构如图:
内部topic设计
mm2会在kafka生成多个内部topic ,来存储源集群topic相关的状态和配置信息,以及维持心跳。主要有三个内部topic:
- hearbeat topic
- checkpoints topic
- offset sync topic
这几个内部topic都比较好理解,一看名字基本就知道是干嘛用的,值得一提的是这其中checkpoints和hearbeat功能都可以通过配置关闭。下面我们详细介绍下这几个topic的功能和数据格式。
heartbeat topic
在默认的配置中,源集群和目标集群都会有一个用于发送心跳的topic,consumer 客户端通过这个 topic,一方面可以确认当前的 connector 是否存活,另一方面确认源集群是否处于可用状态。
heartbeat topic的schema如下:
- target cluster:接收心跳集群
- source cluster:发送心跳的集群
- timestamp:时间戳
checkpoints topic
对应的connector(即MirrorCheckpointConnector)会定期向目标集群发送checkpoint信息,主要是consumer group提交的offset ,以及相关辅助信息。
checkpoints topic 的schema如下:
- consumer group id (String)
- topic (String) :包含源集群和目标集群的 topic
- partition (int)
- upstream offset (int): 源集群指定consumer group已提交的offset(latest committed offset in source cluster)
- downstream offset (int): 目标集群已同步的offset(latest committed offset translated to target cluster)
- metadata (String):partition元数据
- timestamp
mm2提供的另一个功能,consumer切换集群消费就是通过这个topic实现的。因为这个topic中存放了源集群consumer group的消费offset,在某些场景(比如源集群故障)下要切换consumer到目标集群,就可以通过这个topic获取消费offset然后继续消费。
offset sync
这个topic ,主要是在两个集群间同步topic partition的offset。这里的offset并不是consumer的offset,而是日志的offset。
它的 schema 如下:
- topic (String):topic 名
- partition (int)
- upstream offset (int):源集群的 offset
- downstream offset (int):目标集群的 offset,和源集群的应该保持一致
config sync
mm2会将源集群的数据同步到目标集群,那么目标集群对应的topic的读写权限上怎样的呢?mm2约定了,目标集群对应的topic(源集群备份的那个)只有source和sink connector能够写入。为了实施此策略,MM2使用以下规则将 ACL 策略传播到下游主题:
- 若用户对源集群的topic有read的权限,那么对目标集群对应的topic也有read的权限
- 除了mm2,别的用户都不能写入目标集群对应的topic
同时会同步topic相关配置信息
acl
consumer切换集群
源集群的consumer group offset ,是存储在目标集群的checkpoint topic中,这点我们上面已经有说到过。要获取这些offset信息,可以使用MirrorClient#remoteConsumerOffsets这个 api,然后就能用 consumer#seek api 根据给出的offset消费。
这里顺便提供下大致代码,首先maven添加依赖:
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>connect-mirror</artifactId>
<version>2.4.0</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>connect-mirror-client</artifactId>
<version>2.4.0</version>
</dependency>
然后获取offset信息:
MirrorMakerConfig mmConfig = new MirrorMakerConfig(mm2.getProp());
MirrorClientConfig mmClientConfig = mmConfig.clientConfig("target-cluster");
MirrorClient mmClient = new MirrorClient(mmClientConfig);
Map<TopicPartition, OffsetAndMetadata> offsetMap =
mmClient.remoteConsumerOffsets("my-consumer-group", "source-cluster", Duration.ofMinutes(1));
consumer#seek的用法就不演示了。
其他功能
最后顺便介绍下其他比较基础的功能。
源集群和目标集群partition保持同步
- 消息的分区和排序,源集群和目标集群都会保持一样
- 目标集群的分区数与源集群分区保持一样
- 目标集群只会有一个topic与源集群topic对应
- 目标集群只会有一个分区与源集群的分区对应
- 目标集群的partition i对应源集群partition i
说白了就是源集群和目标集群的partition和消息会尽量保持一致,当然可能会有重复消息的情况,因为目前还不指定exactly-once,据说后续版本会有(2.4版本以后)。
同步topic增加前缀
mm1有一个缺陷,因为mm1备份数据的时候,源集群和目标集群的topic名称都是一样的,所以可能出现两个集群的消息无限递归的情况(就是两个名称相同的topic,一条消息a传b,b再传a,循环往复)。mm2解决这个缺陷,采用了给topic加一个前缀的方式,如果是两个集群相互备份,那么有前缀的topic的消息,是不会备份的。
同步配置和acl
mm1的时候,配置信息和topic acl相关的信息是不会同步的,这会给集群管理带来一定的困难,mm2解决了这个问题,即源集群的配置和acl都会自动同步到目标集群中。
说完功能,最后再介绍下部署方式。
部署方式
目前主要支持三种部署方式
- mm2专用集群部署:无需依赖kafka connect,mm2已经提供了一个driver可以单独部署mm2集群,仅需一条命令就可以启动:./bin/connect-mirror-maker.sh mm2.properties
- 依赖kafka connect集群部署:需要先启动kafka connect集群模式,然后手动启动每个mm2相关的connector,相对比较繁琐。适合已经有kafka connect集群的场景。
- 依赖kafka connect单机部署:需要在配置文件中配置好各个connector,然后启动Kafka connect单机服务。不过这种方式便捷性不如mm2专用集群模式,稳定性不如kafka connect 集群模式,适合测试环境下部署。
mm2 相关的配置参照KIP-382,主要配置包括 source 和 target 的 broker 配置,hearbeat ,checkpoint 功能是否启用,同步时间间隔等。
mm2独立集群部署
要部署mm2集群相对比较简单,只需要先在config/mm2.properties写个配置文件:
# 指定两个集群,以及对应的host
clusters = us-west, us-east
us-west.bootstrap.servers = host1:9092
us-east.bootstrap.servers = host2:9092
# 指定同步备份的topic & consumer group,支持正则
topics = .*
groups = .*
emit.checkpoints.interval.seconds = 10
# 指定复制链条,可以是双向的
us-west->us-east.enabled = true
# us-east->us-west.enabled = true # 双向,符合条件的两个集群的topic会相互备份
# 可以自定义一些配置
us-west.offset.storage.topic = mm2-offsets
# 也可以指定是否启用哪个链条的hearbeat,默认是双向hearbeat的
us-west->us-east.emit.heartbeats.enabled = false
然后使用一条命令就可以启动了,./bin/connect-mirror-maker.sh mm2.properties。启动后用jps观察进程,再list下topic,可以发现多了许多个topic,这种时候应该就启动成功了。
顺便说下,如果是使用kafka connect集群,那需要手动启动每个connector,类似这样:
PUT /connectors/us-west-source/config HTTP/1.1
{
"name": "us-west-source",
"connector.class": "org.apache.kafka.connect.mirror.MirrorSourceConnector",
"source.cluster.alias": "us-west",
"target.cluster.alias": "us-east",
"source.cluster.bootstrap.servers": "us-west-host1:9091",
"topics": ".*"
}
以上~