�Զ�������ѧϰ(AutoML)���Խ��Խ��,�ǻ���ѧϰ�¸���չ����֮һ�����е�������ṹ����(NAS)��������Ҫ�ļ���֮һ���˹����������Ҫ�ḻ�ľ����רҵ֪ʶ,���������ڶ�ij�����,�����������ռ��NAS�����ڴ˾�������ռ����Զ����ҵ����ŵ�����ṹ,ʵ�����ѧϰ���Զ��������Ľ����ܼ��־����NAS����,���������һ����NAS��ֱ����������ȻNAS���ȶ���������,��NAS�ķ�չ����ͣ��,AutoML�ķ�չ������ͣ��,�Ͼ�һ�������AI��ѧ���Լ��ɳ���
1������ǿ��ѧϰ��NAS
������ܵ�������Zoph, Barret, and Quoc V. Le. ��Neural Architecture Search with Reinforcement Learning.�� ICLR, 2016.?��ƪ���ĵĴ����ܺ�˼·����ͼ��ʾ������ƪ����������ʹ��һ��RNN��Ϊ�����塣���߿��ǵ�������Ľṹ�����ӿ�����һ���ɱ䳤�ȵ��ַ�����ʾ,����������RNN�����������ַ�����RNN�����������������ַ���,һ������,��������(child network)�ͱ�ȷ���ˡ�ѵ�����������,�õ���֤������������ϵ�ȷ��,��Ϊ�����źš�Ȼ����ݽ�����������ݶ�,����RNN������һ�ֵ���,RNN�������������֤����ȷ�ʸߵ�һ������ṹ��Ҳ����˵,RNN������ʱ��������������������

����������Ҫ����һ��ǰ���ֻ��������������(û�п�����)��ʹ��RNN�������ɾ�����ij�����,��������ʾΪһ���������:
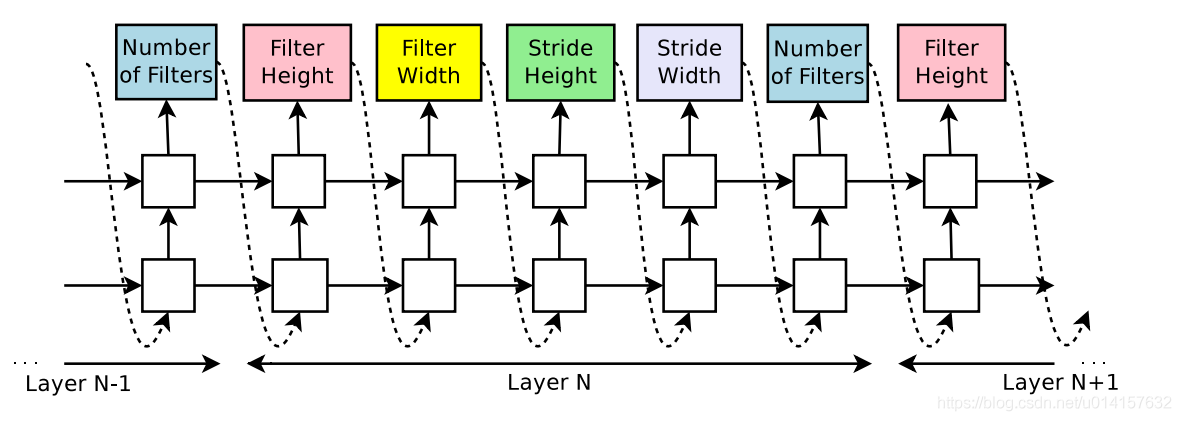
RNN��Ԥ��ÿһ����˲����ĸ߶ȡ�����,�����ĸ߶ȡ�����,���˲�������,һ��5��������ÿһ��Ԥ����ͨ��softmax������ʵ�ֵ�,���ʱ�䲽��Ԥ�����Ϊ�¸�ʱ�䲽�����롣�������ﵽһ���ض���ֵ,������ɵĹ��̾ͻ�ֹͣ�����ֵ������ѵ���������ӡ�һ��RNN������һ���ṹ,��������,���������ͻᱻѵ��,��֤����ȷ�ʱ���¼��������Ϊ������Ȼ�������RNN�IJ���

������������������֤��ȷ�����Ľṹ��
RNN����һ���������,�����ɵı�����п��Ա�����һϵ�ж���

����֤��������ȡ�õ�ȷ����Ϊ����R RR,Ȼ��ѵ��RNN��Ϊ���ҵ����ŵĽṹ,������RNNȡ�����������

:

��ʽ�ľ����������:

����m�ǿ�������ѵ��������һ��batch���ɵ�����������,T�����ɵ�ÿ��������ij���������,

�ǵ�k������������֤���ϵ�ȷ�ʡ������Ĺ�������ƫ��,�����кܸߵķ���,Ϊ�˽��ͷ���,����ʹ����baseline function:

����b��֮ǰ������ȷ�ʵ�ָ���ƶ�ƽ��ֵ��
������ܵľ��ǻ���ǿ��ѧϰNAS�Ļ���ԭ��,����ԭ�����л��д�������(skip)�����������RNN������,����Ȥ�Ķ��߿��Լ����Ķ�ԭ���ġ�����ǿ��ѧϰ�ķ�����NAS�Ŀ���֮��,��ȱ��Ҳ������:ÿ�������µ�����ṹ��Ҫ����ѵ��,�dz���ʱ,�Ҳ����ݶȲ�һ���ܴﵽ�ܺõĽ����
2�������Ŵ��㷨��NAS
��ڽ��ܵ�������Real, Esteban, et al. ��Large-Scale Evolution of Image Classifiers.�� ICML��17 Proceedings of the 34th International Conference on Machine Learning - Volume 70, 2017, pp. 2902�C2911.?���IJ����Ŵ��㷨�������������������,���߽�����һ��������ģ�͵���Ⱥ,�����Ⱥ������ܶͬ������ģ��,����ÿ��ģ�ͼ�Ϊһ�����������ģ�ͱ�ѵ��������֤���ϵ�ȷ��Ϊ�˸������Ӧ����������ÿһ����������,worker(�������)����Ⱥ�����ѡ����������,Ȼ����㲢�Ƚ�����Ӧ�ȡ���Ӧ�Ƚϲ�ĸ������Ⱥ�б��Ƴ�,�Ϻõĸ�����������Ϊ�ױ�������һ������ֳ����ֳ������,worker��������ױ�,Ȼ������������,��������нṹ�ϵ���,�ĺ��ģ�ͳ�Ϊ�������������ѵ��Ȼ��õ�����֤���ϵ�ȷ��,��Żص���Ⱥ�
�������IJ����ھ�������ռ���Ѱ�����ŵķ���ģ����Ҫ��ļ�����,Ϊ�����������һ�����ģ���еķ������ܶ�worker�ڲ�ͬ�ļ�������첽�ز���,���DZ˴�֮�䲻ֱ��ͨ�š�����ʹ��һ���������ļ�ϵͳ,�������ֵ�洢����Ⱥ����Ϣ,ÿ���ֵ����һ�����塣��Ӧ�IJ�������ͨ�����ֵ����,����,�Ƴ�һ�����弴Ϊ�ֵ������������ʱ������������,����ͬһ������,һ��worker���Զ��������,����һ��worker�������ڶ�����в���,��ʱ���worker�����IJ����³��ԡ�����ƪ������,��Ⱥ�Ĵ�С��1000������,worker�ĸ�������Ϊ��Ⱥ��С���ķ�֮һ��Ϊ�������Ŀռ���ʵ�ֳ�ʱ�������,�ᾭ���Ա��Ƴ��ĸ�����ֵ���������ռ���
���ڸ�����˵,��ṹ������Ϊһ��ͼ,���dz�֮ΪDNA����ͼ��,�����ʾ3�����������3��������ʾͼƬ�ij�����ͨ����������������Ǵ�ReLu��������,Ҳ�����Ǽ����Ե�Ԫ��ͼ�ı߱�ʾ���ӳ������,����������������Եı����˵���ֵ��������һ�������ж����ʱ,���ǵij�����ͨ����Ŀ���ܲ�һ�¡�Ϊ�˽���������,ѡ����Щ���е�һ����Ϊ��Ҫ��,�����Ҫ���Ƿǿ����ӵġ�����Ҫ�ߵļ���ֵ����Ҫ��Ϊ��,�ڳ������ά���Ͻ���zerothorder��ֵ,��ͨ�����ά���Ͻ�������ضϡ�����ͼ,ѧϰ��Ҳ������DNA������ͨ�����ױ��ĸ��ƺͱ��������,��Щ�����Ǵ�Ԥ�ȶ���ļ��������ѡ��ġ�Ԥ�ȶ���ı��켯�ϰ����ı�ѧϰ�ʡ�����������Ƴ��������ı䲽�����ı�ͨ����Ŀ�ȵȡ�����������ʱѡȡ���Ǿ��ȷֲ��ġ�������ֵ�͵ı���,�µ�ֵ������ֵ����ѡȡ������,һ������������һ����10�����ͨ���ľ���,���ᵼ��һ����5��20�����ͨ���ľ���(����ԭʼֵ��һ�뵽����),�ڴ˷�Χ�ڵ�ֵ���������ġ�������������Ҳ�����,�Ӷ�����һ���ܼ��������ռ䡣���ڲ���,��ʹ����2Ϊ��logֵ,�Ա㼤��ֵ����״������ƥ�䡣ԭ����,����û������,����,ģ�͵����û�����ơ��������ܼ��Ժ����Իᵼ�´������ܵ�����ṹ����ͼչʾ��һ�������Ĺ���,����������ʱ��,�����Dz��Լ�ȷ��,����ͼ���о����ĸ�ʱ������������ģ�ͽṹ�����ӡ�
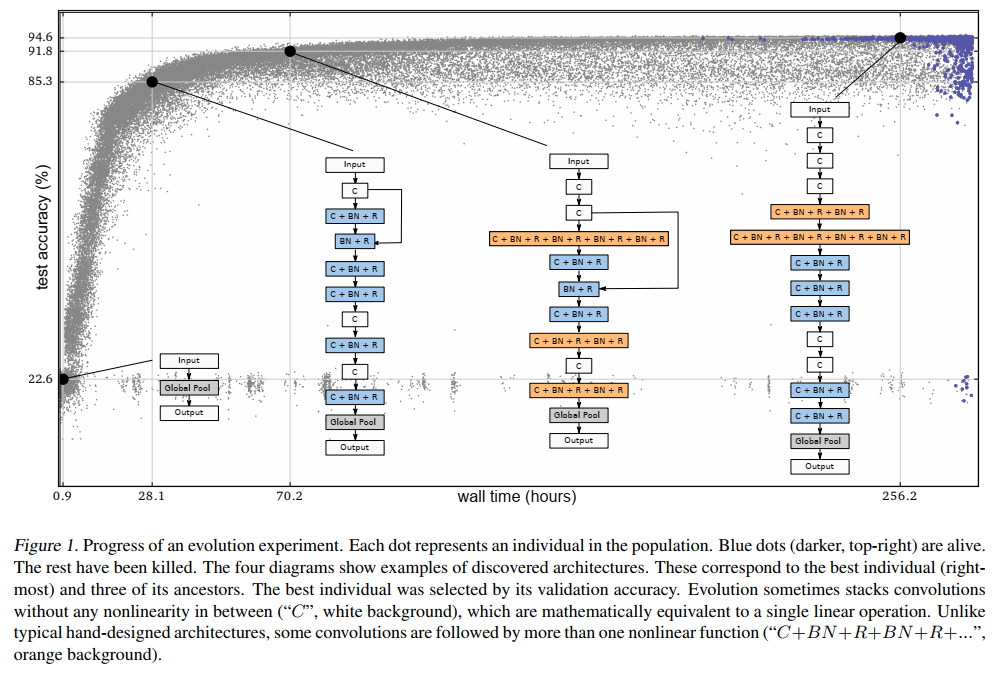
������ܵľ��ǻ����Ŵ��㷨��NAS,����ȱ��Ҳ����������,ÿ�ζ�Ҫ����ѵ���硣
3��One-shot NAS
���ڽ��ܵ�������Bender, Gabriel M., et al. ��Understanding and Simplifying One-Shot Architecture Search.�� International Conference on Machine Learning, 2018, pp. 550�C559. Ϊ������ѵ��ʱ��,one-shot NAS��˼·��ʹ�ó�����,��������纭���������ռ������п��ܵ�����ṹ,ÿ���ӽṹ����Ȩֵ�����ġ�һ������������ͼ��ʾ:
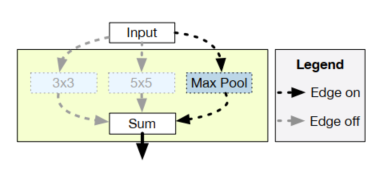
��ͼ��,�������ij��λ��,��3x3������5x5�����������ػ�������������ѡ��,��ͬ�ڷֱ�ѵ������ģ��,����ѵ��һ��������������������ģ��(one-shot model),Ȼ������֤��,����ѡ���Ե��������������������,����ʹԤ��ȷ����ߵIJ�����һ�������ӵ�����,��һ�������п����ںܶ�λ���ϰ����˺ܶͬ�IJ���ѡ��,�����ռ�������ѡ����Ŀָ��������,��one-shotģ�͵Ĵ�Сֻ��ѡ����Ŀ������������ͬ��Ȩ�ؿ������������ܶͬ�Ľṹ,����ؽ����˼�������
Ϊone-shot��������ռ���Ҫ�������¼���Ҫ��:(1)�����ռ���Ҫ�㹻�������������ĺ�ѡ�ṹ;(2)one-shotģ�Ͳ�������֤��ȷ�ʱ�����Ԥ�����ģ��ѵ�������ľ���;(3)�����ļ�����Դ��,one-shotģ����Ҫ�㹻С����ͼ������һ�������ռ������:
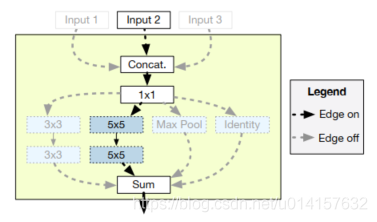
���ϲ��˹�������ṹ��Ӧ���������в�ͬλ�õIJ�������Ҫ���ߡ���ѵ��������,one-shotģ�Ͱ�����������ͬ������,��Щ���뱻������һ����������,������ͨ����Input 1��Input 3��ģ��һ��һ��������Input 2�����硣��һ���˵,���ǿ���ʹ�ܻ��ֹ�κ��������ӵ���ϡ�����,�����ռ�������Ŵ���Ŀ�������Ŀָ����������,��one-shotģ�ʹ�Сֻ���Ե����������Ӳ���������������һ��1x1����,ʹ�������ж��ٴ���Ŀ�����,������˲�����Ŀ���dz�����Ȼ��one-shotģ����1x1�����������Ӧ�ò�ͬ�IJ���,�������ӡ���������,����Ƴ�һЩ��������ͼ����4�ֲ���:3x3������5x5���������ػ���Identity,��ֻ��5x5������������������one-shotģ���Ǹ����͵�����,�ô�������SGDѵ��,Ϊ�˱�֤�ض��ܹ���one-shotģ�;��������ģ�;���֮������ù�ϵ,���߿��������¼�������:
- ������Ӧ��³���ԡ����ֱ��ѵ������one-shotģ��,ģ����ĸ����ֻ����ϡ���ʹ�Ƴ�����Ҫ�IJ���,Ҳ�����ģ��Ԥ�⾫�ȵļ����½�,one-shotģ�ͺͶ���ģ��֮���ȷ�ʵĹ�ϵҲ���˻���Ϊ�˽���������,������ѵ��one-shotģ��ʱҲ������path dropout(���������������dropout,������������),����ÿ��batch,Ҳ�������һЩ������ͨ��ʵ�鷢��,һ��ʼ��ʱ����path dropout,Ȼ������ʱ��������dropout�ļ���,���Դﵽ�ܺõ�Ч����dropout�ļ�����

,0<r<10��ģ�͵ij�����,k�Ǹ���һ�������½���·������Ŀ��Ȼ��dropoutһ���ڵ����������ļ����dz���,����������Ϊ5%���ڵ���cell��,��ͬ�IJ���ʹ�˴˶����ر��������һ��ģ�Ͱ������cell,����ÿ��cell��ͨ�õIJ����ᱻ���� - ѵ��ģ�͵��ȶ��ԡ�����һ������ʵ���ʱ����one-shot��ѵ���ܲ��ȶ�,������ϸ��Ӧ��BN���������ȶ���,����ʹ����BN-ReLU-Conv�����ľ���˳����������Ҫ��ijЩ����,���ʹÿ��batch��ͳ�����ı�,��Ϊ���ں�ѡ�ṹ����ǰ��֪��batchͳ�����������BN������ʱ��Ӧ�÷�ʽ����ѵ��ʱ��ȫ��ͬ������̬����batch��ͳ����Ϣ����������,ѵ��one-shotģ��ʱ,�����һ��batch���ÿ��������dropoutͬ���IJ���,ѵ��Ҳ��ȶ�����˶��ڲ�ͬ�������Ӽ�,����dropout��ͬ�IJ���:���߽�һ��batch�������ֳɶ��Сbatch(���г�Ϊghost batch),һ��batch��1024������,�ֳ�32��ghost batch,ÿ����32������,ÿ��ghost batch����ͬ�IJ�����
- ��ֹ����������ѵ���ڼ�,L2����ֻӦ���ڵ�ǰ�ṹ��one-shotģ�������õ����Dz��֡����������,��Щ������ɾ���IJ�ͻ���ӹ淶����
��one-shotģ��ѵ����֮��,��һ���̶��ĸ��ʷֲ������ز����ṹ,Ȼ������֤��������������ע�,�������Ҳ�������Ŵ��㷨������������ǿ��ѧϰ���档�������֮��,��ͷѵ��������õĽṹ,ͬʱҲ������չ�ܹ�������������,Ҳ������С�ܹ��Լ��ټ���ɱ���������ʵ����,�����˹���������������չ�ܹ���
��Ȼone-shot����Ȩֵ����������ѵ��,ÿ�������綼�̳���һ��ѵ����Ȩ��,������������������Ǹ�����,������ֻ���ܽ�ȷ��Ԥ�������������,one-shot����������Ч��,����Ҳ����one-shot�����ĺ������ѵ㡣
4������NAS
�νڽ��ܵ�������Liu, Hanxiao, et al. ��DARTS: Differentiable Architecture Search.�� International Conference on Learning Representations, 2018.?֮ǰ���ܵ�NAS���������ռ䶼����ɢ��,�����ַ����������ռ��ɳڻ�ʹ����������,�����ʹ���ݶȵķ����������
DARTSҲ����������cellȻ��ѵ�cell�γ����յ����硣�����cell��һ������������ͼ,����һ����N���ڵ���������С�ÿ���ڵ�

��һ��������ʾ(��������ͼ),ÿ������ı�(i,j)�DZ任

�IJ���

��������cell����������ӵ��һ������ڵ�,ÿ���м�ڵ��������е�ǰ���ڵ����õ�:

һ������IJ���:

,�����ڿ��ܵIJ���������,��ʾ�����ڵ�֮��û�����ӡ�ѧϰcell�ṹ�������ת������ѧϰ���ϵIJ�������

Ϊ��ѡ�����ļ���(������������ػ���

?),ÿ��������ʾ������

�ϵĺ���

��Ϊ��ʹ�����ռ�������,���߽��ض�������ѡ���ɳڻ�Ϊ�����п��ܲ����ϵ�softmax:

һ�Խڵ�(i,j)֮��IJ�����һ��

����

���������ɳڻ�֮��,��������ͱ����ѧϰһ�������ı���

,����ͼ��ʾ:
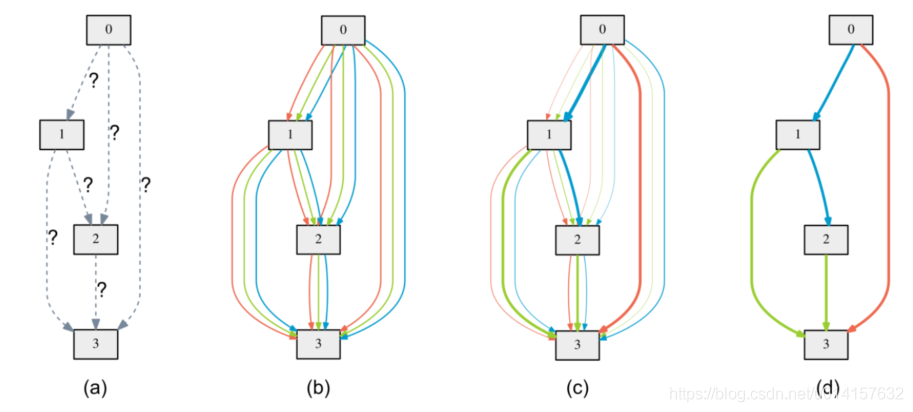
ͼ(a)��ʾ��ʼ���ı�,������δ֪�ġ�ͼ(b)ͨ����ÿ���߷��û�ϵĺ�ѡ�������ɳ������ռ�,ÿ����ɫ���߱�ʾ��ͬ�IJ�����ͼ(c)��ͨ�����һ���Ż�����,����ѵ����ѡ�����ĸ��ʺ������Ȩ��,��ͬ�Ĵ�ϸ��ʾ��

�Ĵ�С��ͼ(d)������ѧϰ���Ľṹ��
ѧϰ�������в����Ŀ�����

��,ѡ���������ſ��ܵIJ���,Ҳ����

��������,���Ƕ���

��ʾ�ṹ���ɳڻ�֮��,���ǵ�Ŀ����ǹ�ͬѧϰ�ṹ

��Ȩ��w,DARTS��Ŀ�������ݶ��½��Ż���֤����ʧ����

��

�ֱ��ʾѵ������֤��ʧ,���Ǿ���Ҫ�ҵ�һ�����ŵ�

��С����֤����ʧ

,����

ͨ����С��ѵ������ʧ

������һ��˫���Ż�����(bilevel opyimization problem),

���ϲ����,w���²����:

��������˫���Ż����������ѵ�,��Ϊ�κ�$\alpha$�ĸı䶼��Ҫ�����¼���

��������������һ�ֽ��Ƶĵ����ⷨ,���ݶ��½���Ȩ�ؿռ�ͽṹ�ռ����������Ż�w��

:

DARTS����ؼ����������ٶ�,�ṩ�˿�������һ����ӱ��˼·���������Ż��Ǹ��ѵ�,����������ģ�Ϳ��ܰ���������skip����������ģ�����ܱ�����
�����Ҫ�Ƽ������Լ�����PythonѧϰȺ:[856833272],Ⱥ�ﶼ��ѧPython��,�������ѧ��������ѧϰPython ,��ӭ�����,��Ҷ�������������,�����ڷ����ɻ�,�������ֱ���γ���ȡ���������Լ�������һ��2021���µ�Python�������Ϻ��������ѧ,��ӭ�����кͶ�Python����Ȥ��С������!������ɨ���VX��ȡ����Ŷ!

?
cs